-
-

XIAO ESP32
-
-
-
-

-
-
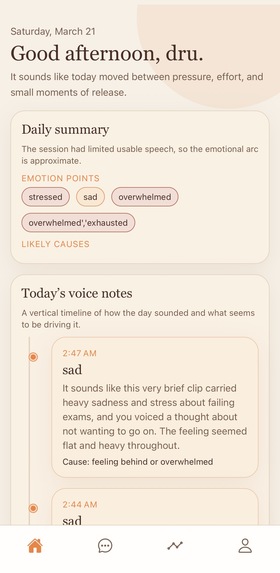




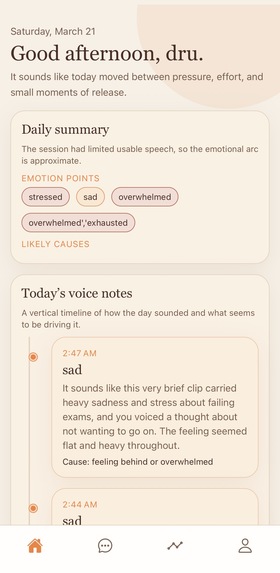
Sona Sona is an AI-powered wearable bracelet designed to capture emotionally significant moments: when a user feels overwhelmed, frustrated, drained, or simply needs to reflect. Instead of acting as a therapist or diagnostic tool, Sona helps users better understand their day by transforming spoken reflections into structured emotional insights, mood patterns, and an end-of-the day reflection question, curated based on the transcript recordings for that day. By combining embedded hardware, voice capture, transcription, sentiment modeling, and session-level fusion, Sona converts unstructured emotional expression into something useful, clarifying, and supportive.
Inspiration We built Sona around a simple problem: people often know that something feels “off,” but they do not always have an easy way to process it in the moment. Traditional journaling requires effort, reflection apps often depend on manual logging, and most tools assume a user already knows how to describe what they are feeling. We wanted to create a lower-friction alternative: a wearable that lets someone speak naturally, then helps them make sense of what was happening emotionally afterward. Our goal was not to replace therapy, diagnose mental health conditions, or overstate what an AI system should do. Instead, we wanted to build a tool for reflection, emotional awareness, and daily pattern recognition: something that could help users better understand stress, overwhelm, emotional shifts, and recurring themes in their day.
What it does Sona allows a user to press a button and speak naturally throughout the day. The bracelet records short reflections or emotionally significant voice notes, which are then processed through a data-science pipeline that converts raw audio into structured, readable insights. Rather than stopping at transcription, Sona analyzes both: what was said, through transcript-based sentiment and emotion understanding how it was said, through vocal tone, pacing, and speech-level emotional signals The system then fuses those signals over time to produce outputs such as: dominant emotions across a session emotional arc over time moments of emotional escalation or relief repeated stress triggers or recurring themes mismatch between spoken content and vocal delivery end-of-day reflection summaries gentle, action-oriented follow-up prompts
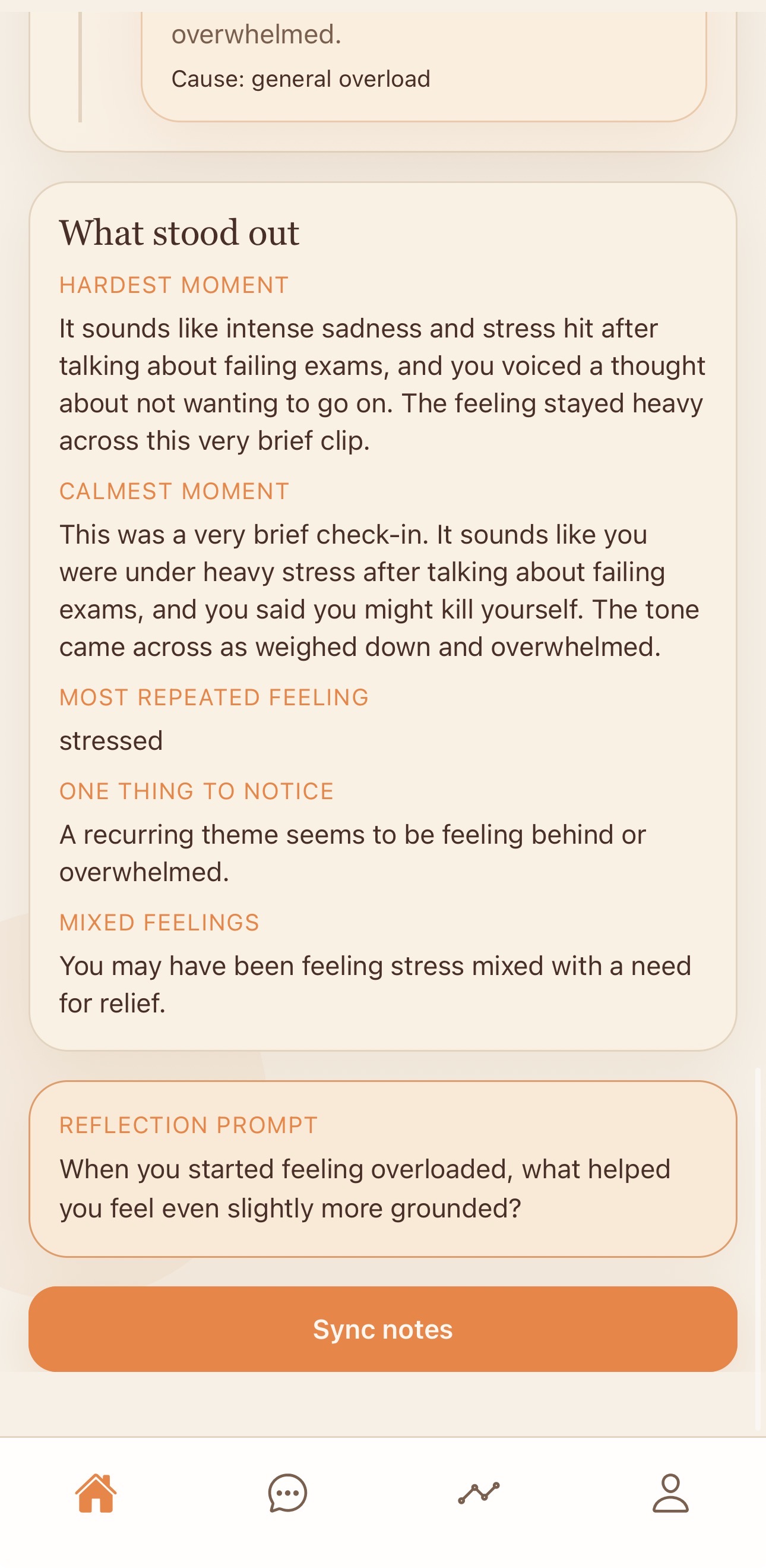
Example outputs include: “Today’s reflection was shaped mostly by overwhelm, frustration, and mental fatigue.” “Your strongest emotional shift happened after discussing school pressure.” “You sounded more calm near the end of the session than at the beginning.” “A recurring theme across your reflections was feeling pulled in too many directions.” The result is a tool that helps users reflect more clearly on what shaped their day, without positioning itself as a diagnosis engine or substitute for professional care.
How we built it Sona combines embedded hardware, signal processing, natural language processing, speech analysis, and session-level data fusion into one end-to-end system.
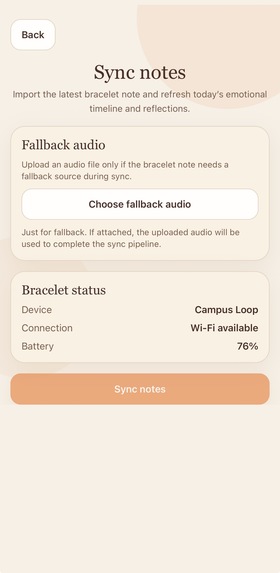
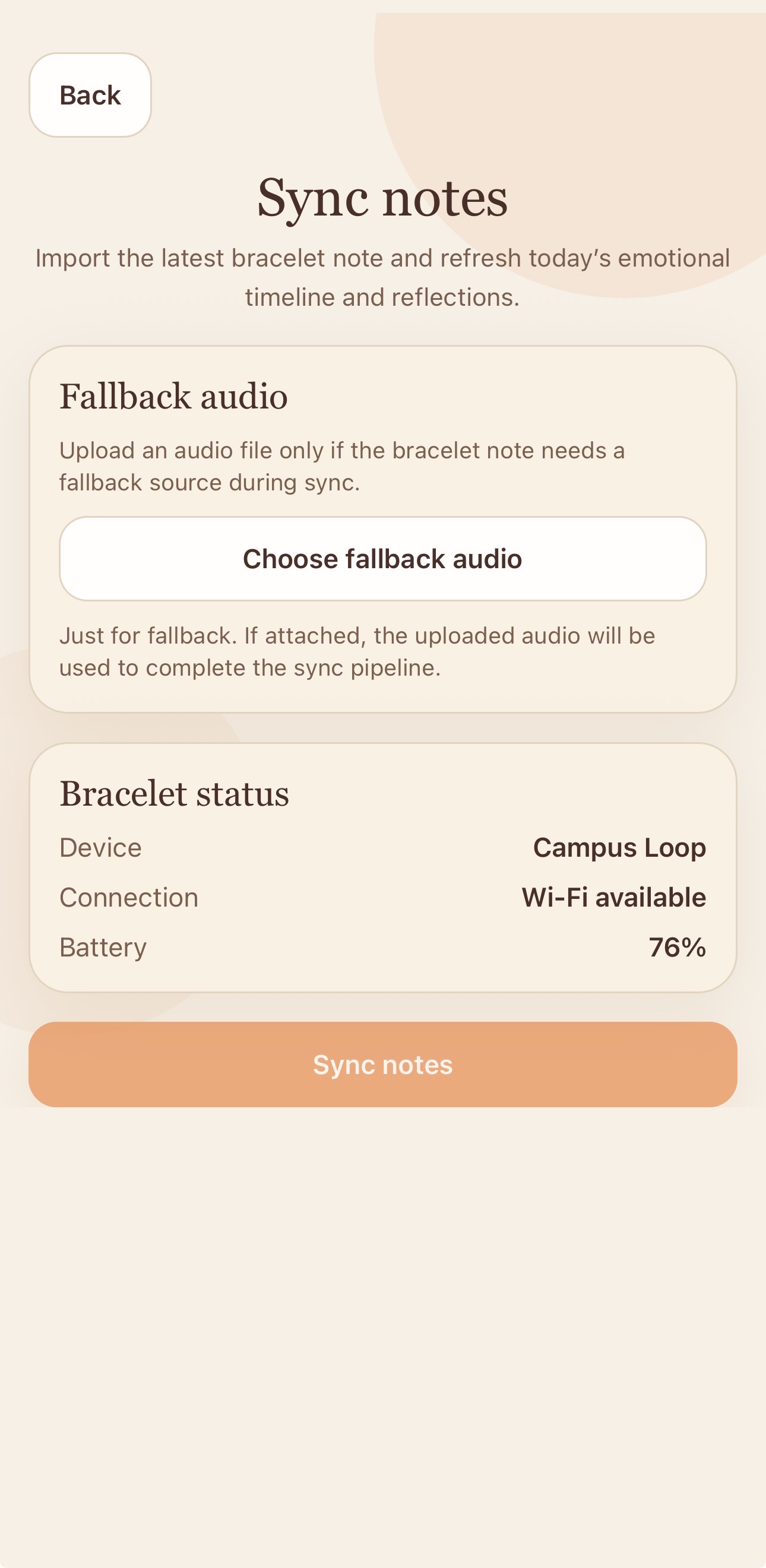
Hardware layer Our prototype wearable stack was designed to stay simple and realistic for a hackathon MVP. It includes: a microcontroller and sensing board with an onboard microphone local storage using a microSD card a latching push button for intuitive start/stop interaction USB-C for power, programming, and debugging a connected laptop for model inference, pipeline orchestration, and interface development This gave us a clean input workflow: the user presses a button, records a voice reflection, and the system captures raw data for downstream processing.
Data-science pipeline The core of Sona is a multi-stage multimodal data pipeline that transforms raw spoken reflections into structured emotional signals, temporal patterns, and grounded user-facing insights. Rather than assigning a single label to an entire recording, Sona models a session as a sequence of aligned windows and fuses information from transcript semantics, vocal delivery, and physiological context over time.
- Audio capture Sona starts with low-friction voice capture through the bracelet’s onboard microphone. The interaction is intentionally simple: the user speaks naturally without needing to type, manually tag emotions, or navigate a complex interface during an emotionally difficult moment. This preserves more realistic behavioral data and makes the system practical for real-world use.
- Audio ingestion and preprocessing The raw audio file enters the processing pipeline and is standardized before analysis. The system loads the waveform, resamples it to a consistent format, optionally applies light denoising, and trims leading and trailing silence. These steps improve stability for downstream modeling while preserving the core structure of the recording. If a heart-rate stream is available, it is processed in parallel through smoothing, quality checks, and short-gap interpolation so it can later be aligned with the same time windows as the speech data.
- Speech-to-text transcription The cleaned audio is transcribed with Whisper-1, which produces both transcript text and timing information. This step is critical because it converts the recording into a semantic representation while also providing the temporal alignment needed to connect language, voice, and physiological signals within the same moments of the session.
- Temporal segmentation Instead of analyzing the full recording as one example, Sona divides the session into rolling time windows. Each window contains the aligned transcript slice, audio slice, and HR slice for that same interval. This design allows the system to model emotional progression over time, rather than flattening the session into a single prediction.
- Text-based emotion and theme modeling For each transcript window, Sona runs two NLP layers: GoEmotions-based text emotion classification to estimate the emotional content of the language Zero-shot NLI-based theme detection to identify what the emotional content is about, such as pressure, uncertainty, conflict, self-doubt, or recovery This branch captures the semantic meaning of the reflection: not only what the user is feeling, but also what appears to be driving that emotional state.
- Vocal signal analysis In parallel, Sona analyzes the audio directly. librosa-based acoustic extraction captures interpretable delivery features such as pitch behavior, energy, and pause patterns a wav2vec2-based speech emotion recognition (SER) model estimates coarse vocal affect, including audio-derived valence and arousal signals This branch matters because emotional state is often communicated through delivery, not just through words. Two recordings may contain similar language but sound very different emotionally.
- Window-level multimodal representation Each aligned time window is converted into a structured intermediate record containing: transcript text text emotion labels text valence theme/trigger labels acoustic features speech-emotion indicators HR statistics, when available timing metadata confidence and usability flags This intermediate format is one of the most important data-science layers in Sona. It standardizes outputs from multiple model branches into a common multimodal representation that can be compared and aggregated downstream.
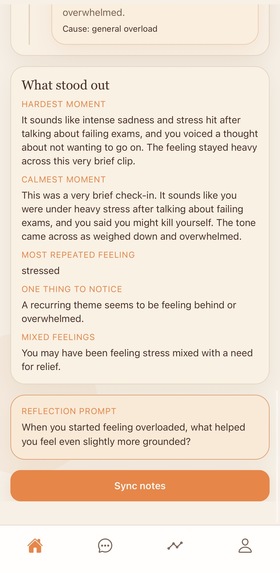
Session-level late fusion This is the core intelligence layer of Sona. Rather than training one end-to-end model (common example: XGBOOST CNN), Sona uses rule-based late fusion over the window-level records to compute higher-order session signals in order to properly address user runs without overfitting on recorded data. From those windows, the system identifies: dominant recurring emotions a smoothed emotional arc across the session the largest emotional shift or turning point repeated triggers that appear across multiple windows mismatch between transcript sentiment and vocal affect signs of stabilization or recovery later in the recording This allows Sona to model emotional structure over time, not just isolated classifications. The goal is not simply to tag one emotion, but to understand how the session evolves.
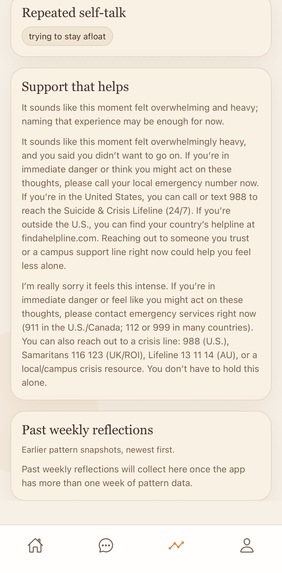
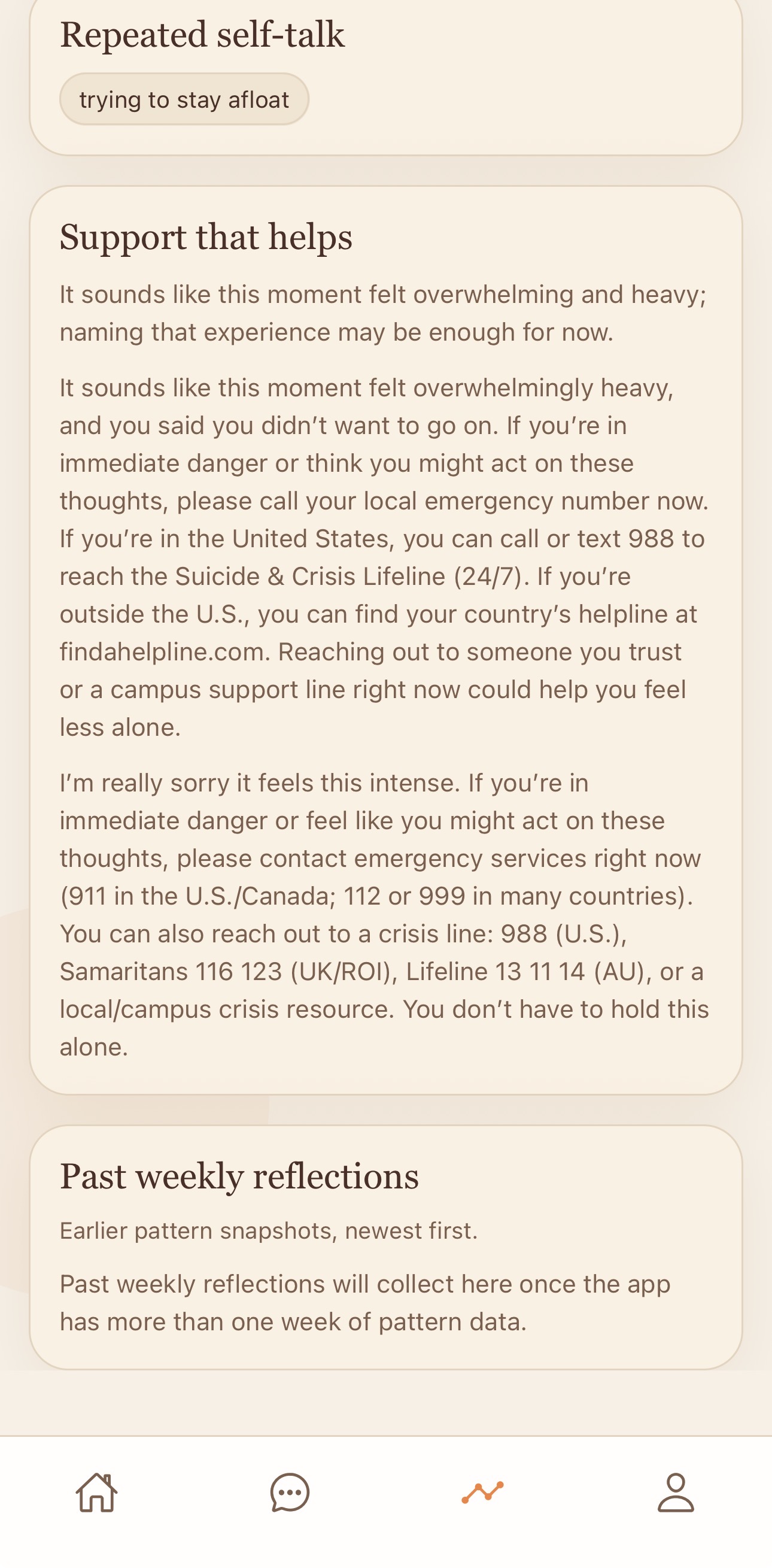
Structured reflection generation Once the multimodal summary is built, the system converts it into a grounded reflection. Importantly, the reflection layer does not generate directly from raw audio or raw model outputs. Instead, it generates from the fused session summary, which keeps the final response more constrained, interpretable, and evidence-based. The reflection focuses on: what shaped the session where emotional shifts occurred what may have remained unresolved what seemed to help what patterns repeated
Since Sona is currently implemented as a multimodal late-fusion pipeline using pretrained components and rule-based aggregation, we did not evaluate it as a single supervised classifier. Instead, we focused on whether the pipeline worked end to end, whether each modality contributed usable signals, and whether the final reflection was grounded and interpretable. As we collect a labeled dataset of multimodal sessions, the next step is to add formal model-level evaluation for fusion quality, trigger detection, and recovery detection.
Why it matters Sona is not just a speech-to-text wearable. It is a system for turning unstructured human expression into interpretable emotional reflection. Many wellness tools either stop at note capture or jump too quickly into high-level recommendations. We wanted to focus on the middle layer that is often missing: helping the user see what emotional patterns were actually present, how they changed over time, and what themes may have driven those shifts. That makes Sona especially relevant for users who: struggle to journal consistently need a more natural reflection interface want insight into recurring stress or emotional patterns benefit from spoken processing more than typed logging
Challenges we ran into One of our biggest challenges was designing a system that felt both technically credible and emotionally useful within hackathon constraints. The core technical challenges included: GPT 4.0 transcribe was not windowing text switched to Whisper-1 SER model was delivering an exponentiated emotion score above 1 so we applied a sigmoid function on each class score Combining transcript meaning with vocal delivery and HR. Our solution was to use a rule-based late fusion model. deciding how to aggregate window-level predictions into meaningful session-level outputs (15s window with stride = 7s) designing outputs that felt reflective rather than robotic in terms of UX We also had to think carefully about product responsibility. Because this project touches mental wellness, it was important not to overclaim. We intentionally framed Sona as a reflection tool, not a therapist, not a medical device, and not a diagnostic system. Another major challenge was balancing ambition with MVP scope. There are many possible wearable signals we could include, but for a hackathon build, we focused on the most compelling and demo-able pipeline: voice capture to reflective emotional insight. Accomplishments that we’re proud of We are proud that Sona goes beyond a generic AI journaling app or a simple transcript summarizer.
Our key accomplishments include: designing a believable wearable AI concept with a clear user interaction loop without prior hardware experience building a data-science-heavy pipeline creating a session-level fusion layer that captures emotional progression over time centering interpretability and emotional readability in the user-facing output framing the project responsibly within the mental-wellness space integrating hardware, speech processing, NLP, and reflection generation into one coherent story Sona does not just ask “what label fits this audio clip?”. Instead, it asks the deeper question of “what emotional pattern did this session reflect?”
What we learned This project taught us that emotional AI is much more nuanced than simply classifying text as positive or negative. A person can sound calm but speak about distress. They can sound sharp, tired, relieved, or conflicted in ways that do not map neatly onto a single label. That made it clear that if we wanted Sona to feel useful, we had to focus on: emotional change over time mixed emotional states structured fusion across modalities interpretable outputs rather than raw model scores We also learned that in wellness-oriented products, technical performance alone is not enough. The output has to be understandable, respectful, and grounded in what the system can actually support.
What’s next for Sona There is a lot of room to extend Sona beyond the hackathon MVP. Our next steps would be: improve personalization by learning each user’s emotional baseline over time strengthen audio-only emotional detection and tone robustness support repeated daily reflections and long-term trend tracking add a calendar or timeline view for mood patterns across days incorporate more context-aware reflection prompts refine action-oriented suggestions based on recurring themes make the wearable hardware smaller, cleaner, and more production-ready
Long term, we see Sona as a reflection companion that helps users better understand patterns in stress, overwhelm, recovery, and emotional change: not by replacing human support, but by helping users notice what their day was already telling them.

Log in or sign up for Devpost to join the conversation.