

Problem Statement
Large language models process text as tokens: small units that directly determine compute, cost, and energy.
1.5 quadrillion tokens are processed every month around the world. Up to 73% of those are redundant. Wasted tokens silently eat away at our resources. This is a globally invisible problem, embedded in every prompt, compounding across billions of requests.
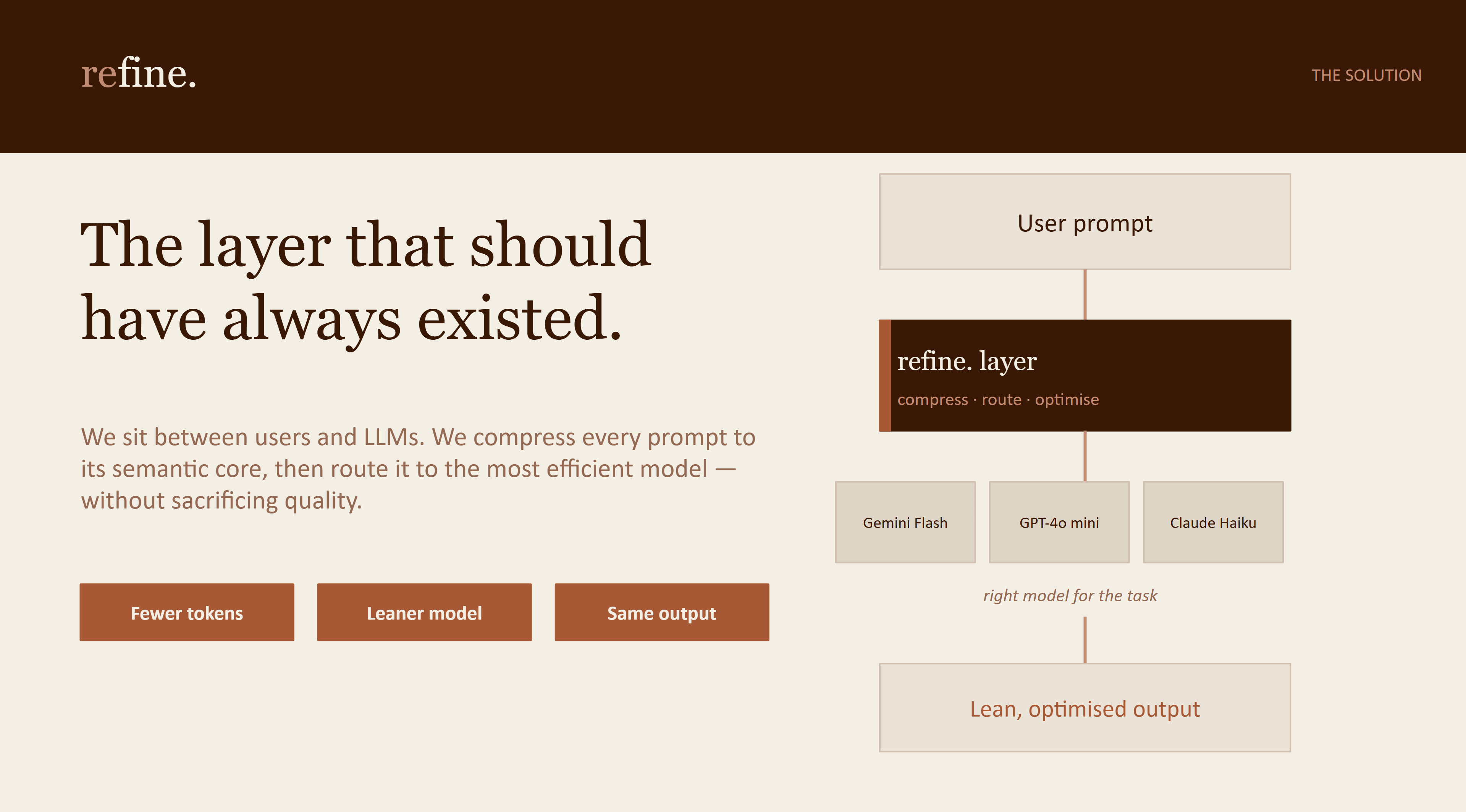
Our software is the layer between users and LLMs, prioritising energy efficiency, we minimise tokens and analyse intent to route each prompt to the most efficient model, without sacrificing quality.
Measurable Impact
Having explored current research, we determined the energy cost of every AI inference is determined by three things multiplied together: the size of the prompt going in, the size of the response coming out, and the size of the model doing the work.
The industry's state of the art in this are Microsoft's LLMLingua, semantic caching, and RAG compression, that all do the same thing. Shrink the prompt, and minimise input tokens. One lever. Nobody takes output tokens into account. Nobody asks if the model was the right choice.
That's the gap. We have built the only pipeline that pulls all three levers simultaneously.
Reduce tokens in → Industry does this. So do we.
Reduce tokens out → Industry doesn't. We have.
Right-size the model → Industry doesn't. We have.
Measured live on real prompts: 70.5% token reduction. That's 2.3g CO₂ saved per inference. Applied across 2.5 billion daily AI requests, it has the potential for real impact to an otherwise globally invisible and overlooked issue.
Execution
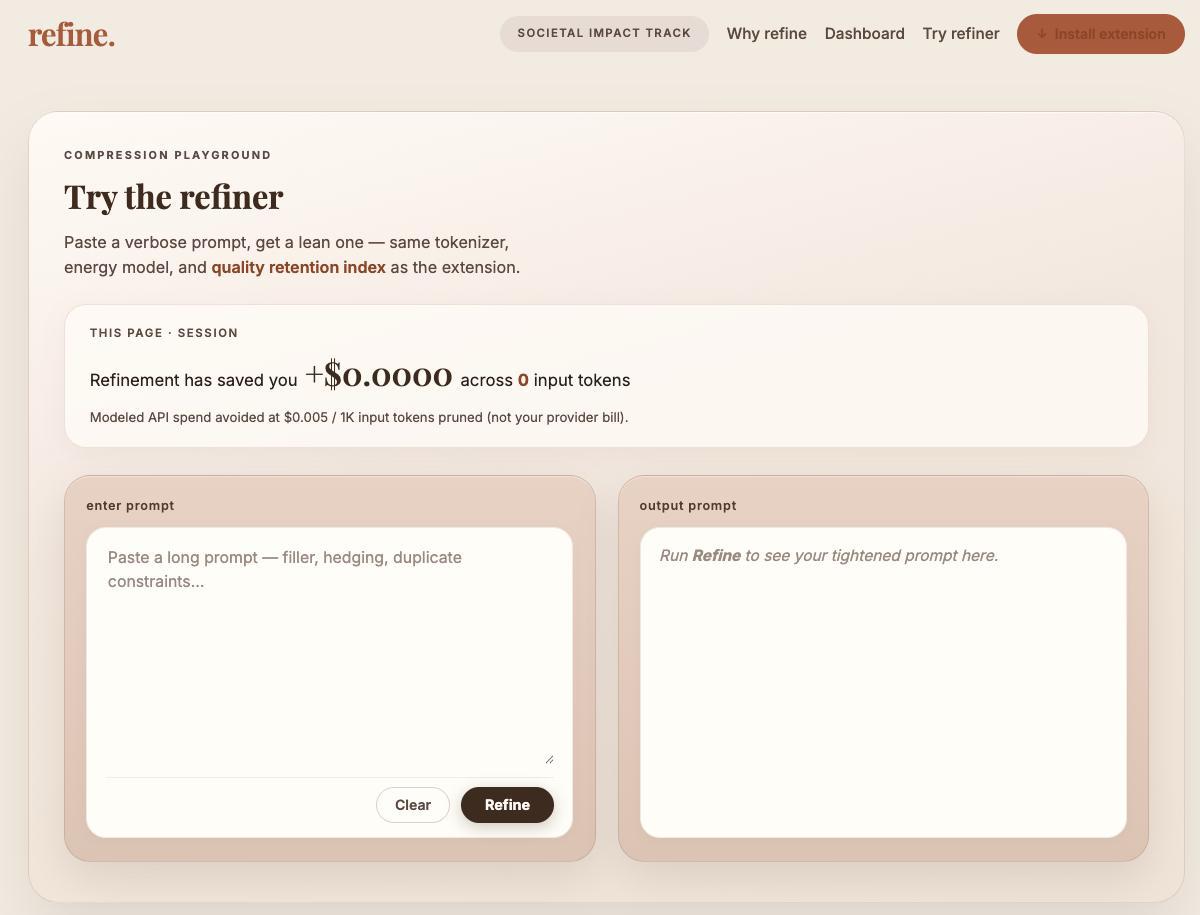
We have implemented 2 main features, the prompt refinement tool, focused on reducing token usage and compressing prompts, and the model optimiser, for prioritising energy efficient models based on the use case.
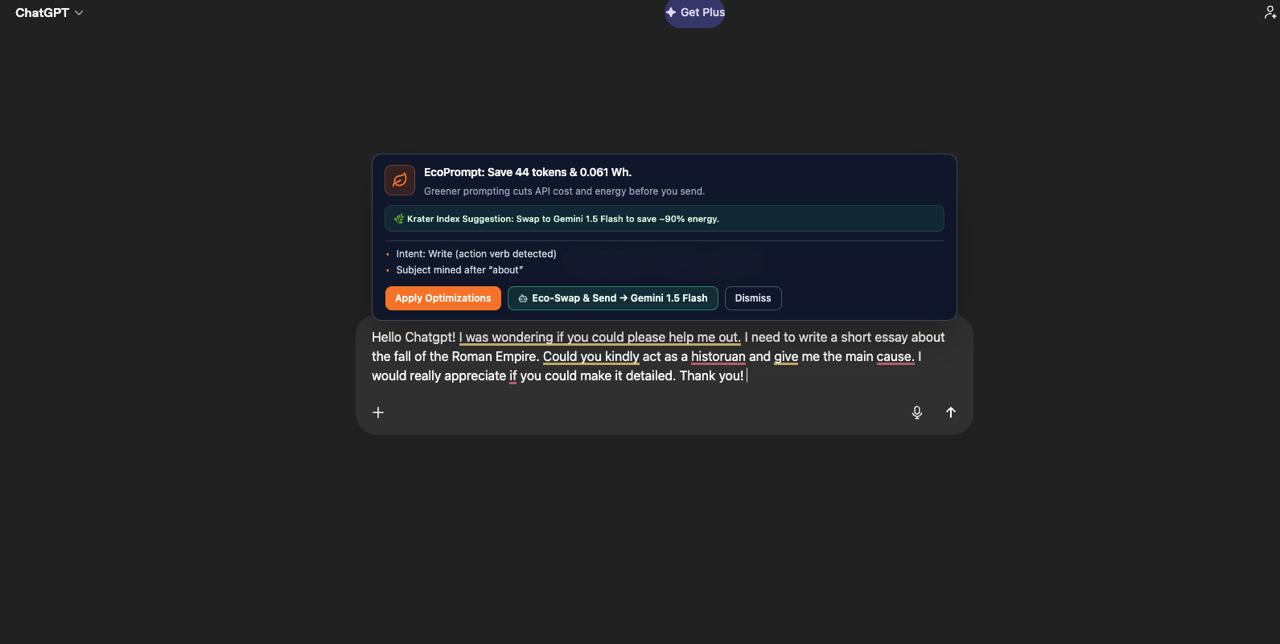
As shown in the demo and project gallery, our product displays a dashboard that aggregates carbon metrics, token savings, and energy efficiency into a seamless interface. We also extended this such that it can be integrated as a browser extension easily into the most common LLM models.
Prompt Refinement
The pipeline runs three stages.
Stage 1 - Removing redundancies Uses Natural Language Processing and a Regex Layer to strip anything that adds no value: filler phrases, polite openers, redundant context. Though trivial, impact evidenced by OpenAI’s CEO confirmed costs of tens of millions in electricity annually, purely from users saying "please" and "thank you.
Stage 2 - Compression Using lexical reduction to further minimise tokens and reduce inference that the LLM would otherwise carry out, reducing the computational load before the prompt ever reaches a model.
Stage 3 - Identifying role and task Focuses on component extraction by identifying the two elements that define any prompt, the role and the task, and rebuilds the prompt around just those. Same intent. A fraction of the tokens. The prompt is then brought together in its compressed form with the role and task.
Model Switching
Krater.AI is utilised in order to categorise tasks by complexity using an Efficiency Index. Therefore we can flag if a request doesn’t require heavy reasoning and is able to use a more light weight model. The distilled prompt, selected persona and target model are now stored as a Lava packet. This is then triggered to the new agent, which reads our packet, thus completing the loop of model switching.
We used Lava as it is the unified gateway that makes this routing possible, a single interface across all mainstream LLMs. Critically, where an LLM is wasteful by design, a prompt asking for a financial statistic, for example, we skip the model entirely and route directly to FRED or Dune via Lava's specialised APIs, returning a precise answer at a fraction of the energy cost.
Carbon Metric Data
In order to quantify carbon metrics for specific prompts we looked to current research for an optimisation formula and an API that specifically weighted the energy impact of each prompt. Every inference is then verified via Ecologits, giving users a scientifically grounded carbon footprint. The research papers we used for this are below: https://www.sciencedirect.com/science/article/pii/S2666498426000293?ref=pdf_download&fr=RR-2&rr=9e3958404cc41376 https://arxiv.org/pdf/2407.16893
Challenges faced
The first challenge we encountered was in the compression of the prompts. The quickest way would be to employ an LLM to refine the prompts, however this would directly oppose the fundamental principle we are optimising for which is saving time, energy and cost. We circumvented this problem by developing an Natural Language Processing and Regex Layer, as it runs locally and has a lower power consumption than using a local LLM such as llama.
The second challenge we encountered was in quantifying the energy efficiency of the prompts, and how reducing tokens would directly impact the energy consumption, given they have a complex and relational link. We researched thoroughly as to how LLM energy profiles have currently been categorised, and ultimately derived an optimisation formula from current research as referenced above. The key takeaway from our optimisation was that energy in LLMs scales with tokens, model size, and inference time, and thus we focused on reducing all three.
What inspired the idea.
We wanted to tackle a problem that matters. A problem that had potential for scalable impact. One of the biggest problems that we recognised was humanity’s impact on the planet. Reducing our consumption in a meaningful way is one of the best ways to tackle this issue. Given AI is known to be extremely taxing from an energy point of view, what might look harmless in a single prompt, a few extra tokens, a larger model will compound across billions of requests into real cost, compute, and energy. That invisible accumulation is what we set out to fix.
Built With
- css
- ecologits
- javascript
- krator
- lava
- react
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.