-
-
Chat compression
-
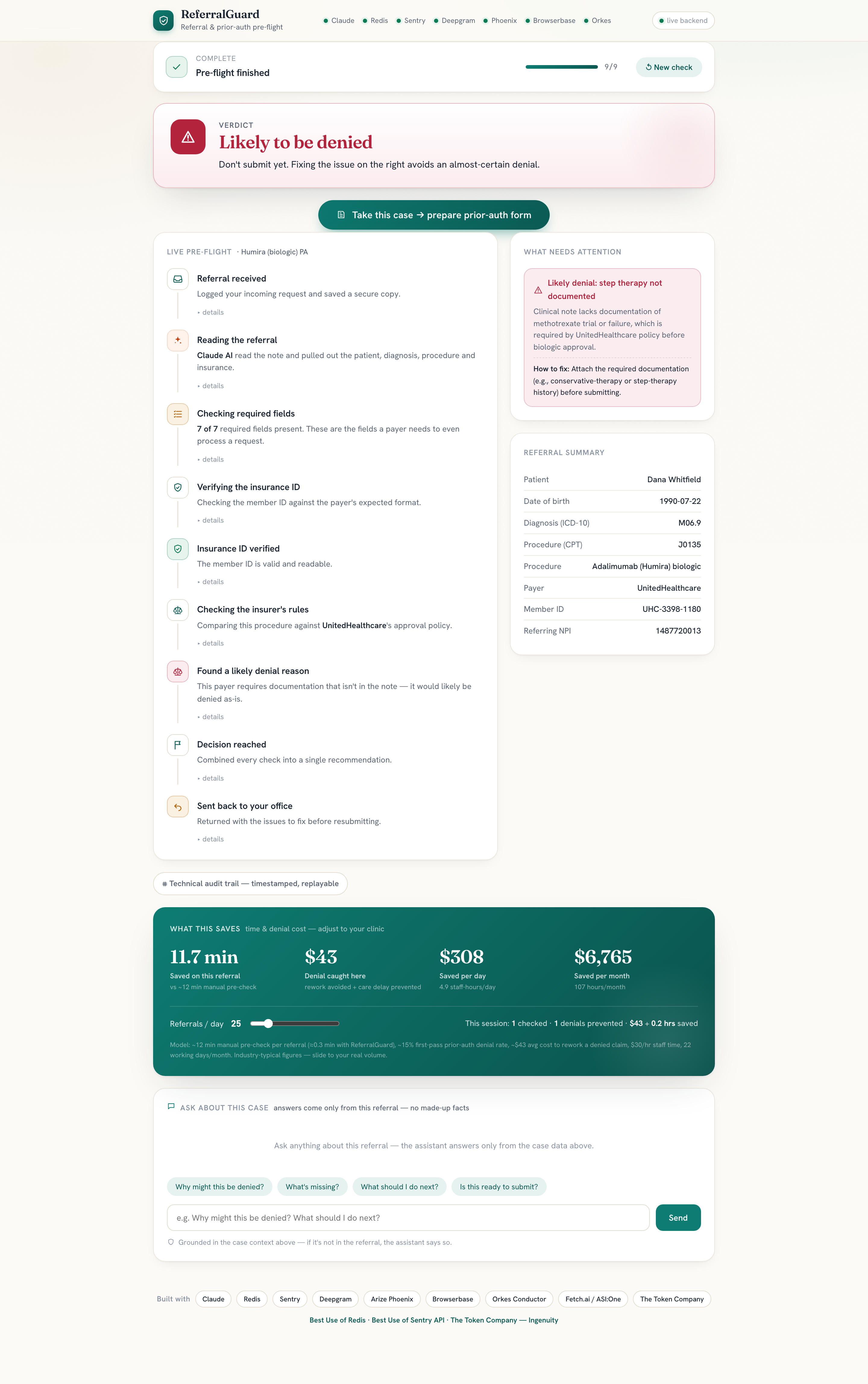
Verdict
-
Editable form
-
Final results
-
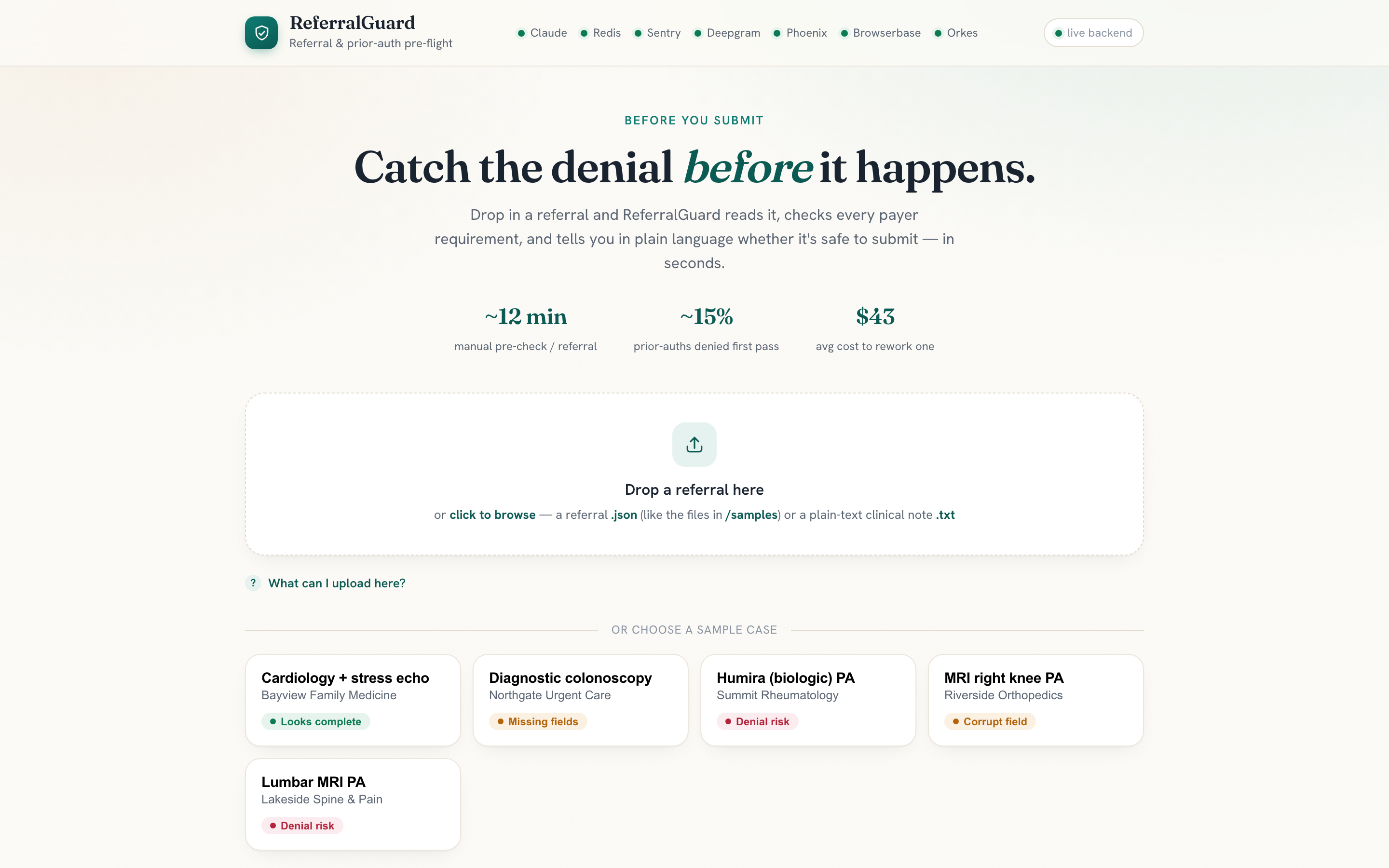
Home
💡 Inspiration
A friend doing residency mentioned something that stuck with us. The hardest part of her week wasn't medicine. It was insurance paperwork. The numbers back it up: physicians spend ~13 hours a week on prior authorizations, and roughly half of specialty referrals never get completed, not because the care was wrong, but because a form was missing an ICD-10 code, a member ID was unreadable off a fax, or a payer's step-therapy rule wasn't documented.
The maddening part is that almost every one of those denials is predictable. The information needed to know "this will bounce" is sitting right there in the referral. Nobody just checks it before hitting submit. So we built the thing that does.
🛡️ What it does
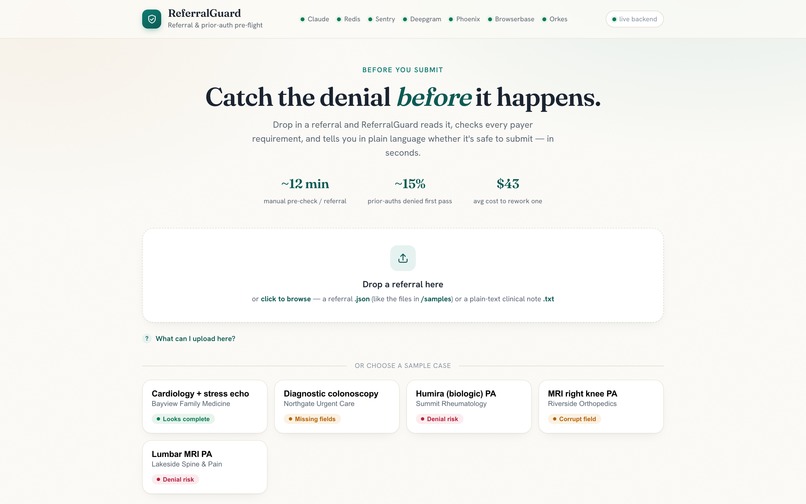
ReferralGuard is a multi-agent pre-flight check for specialty referrals and prior-auth requests. Drop in a referral (typed, faxed, or spoken down a phone line) and in seconds you get:
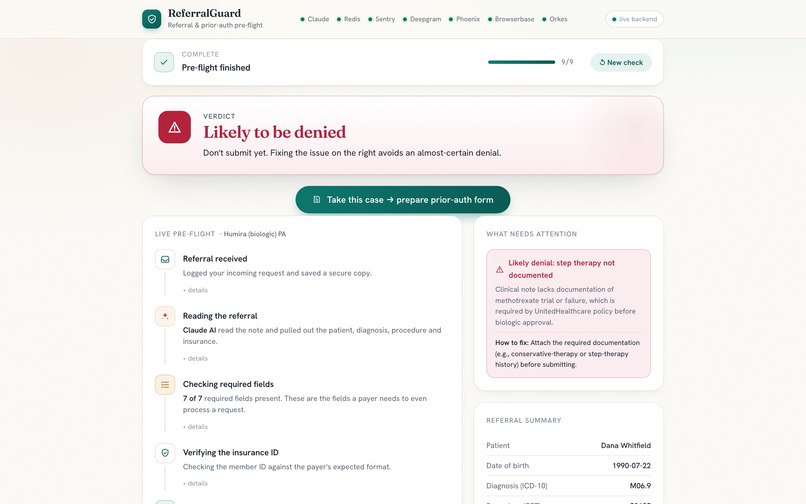
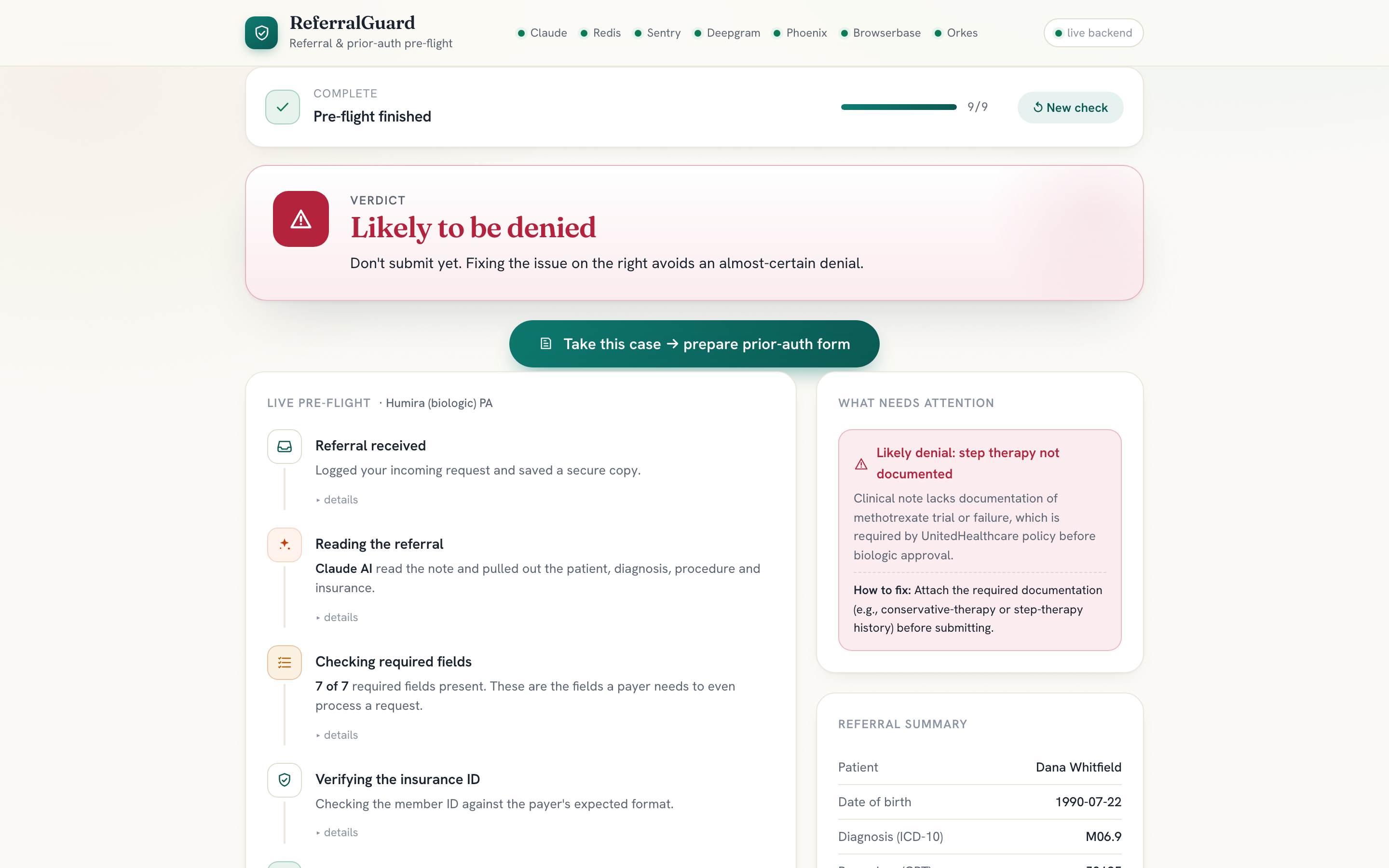
- a verdict in plain English:
READY TO SUBMIT,NEEDS INFO, orHIGH DENIAL RISK - a reason for every flag (e.g. "United requires a documented methotrexate trial, not in the note")
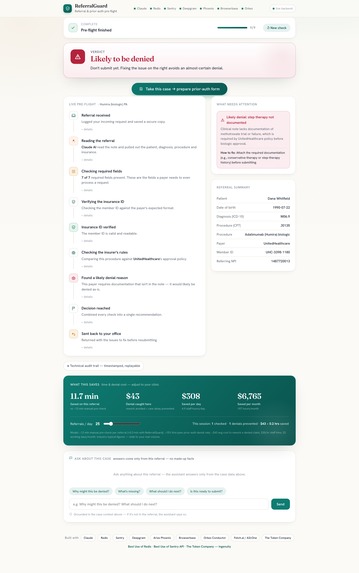
- a live, replayable audit trail of what each agent checked and why
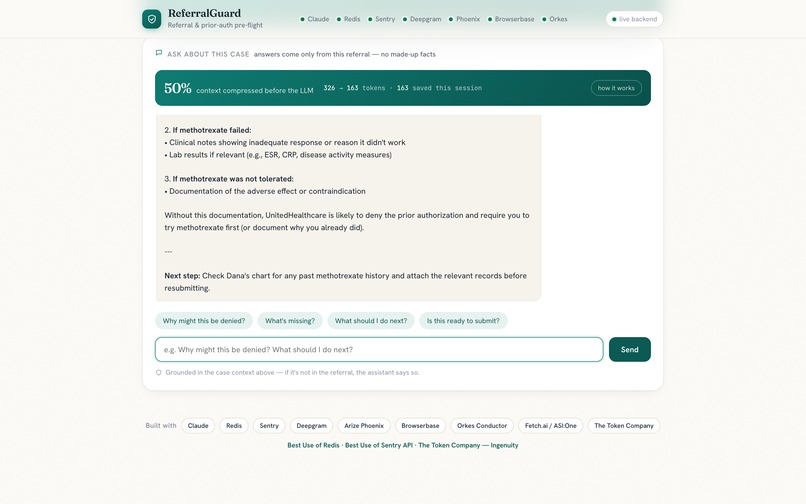
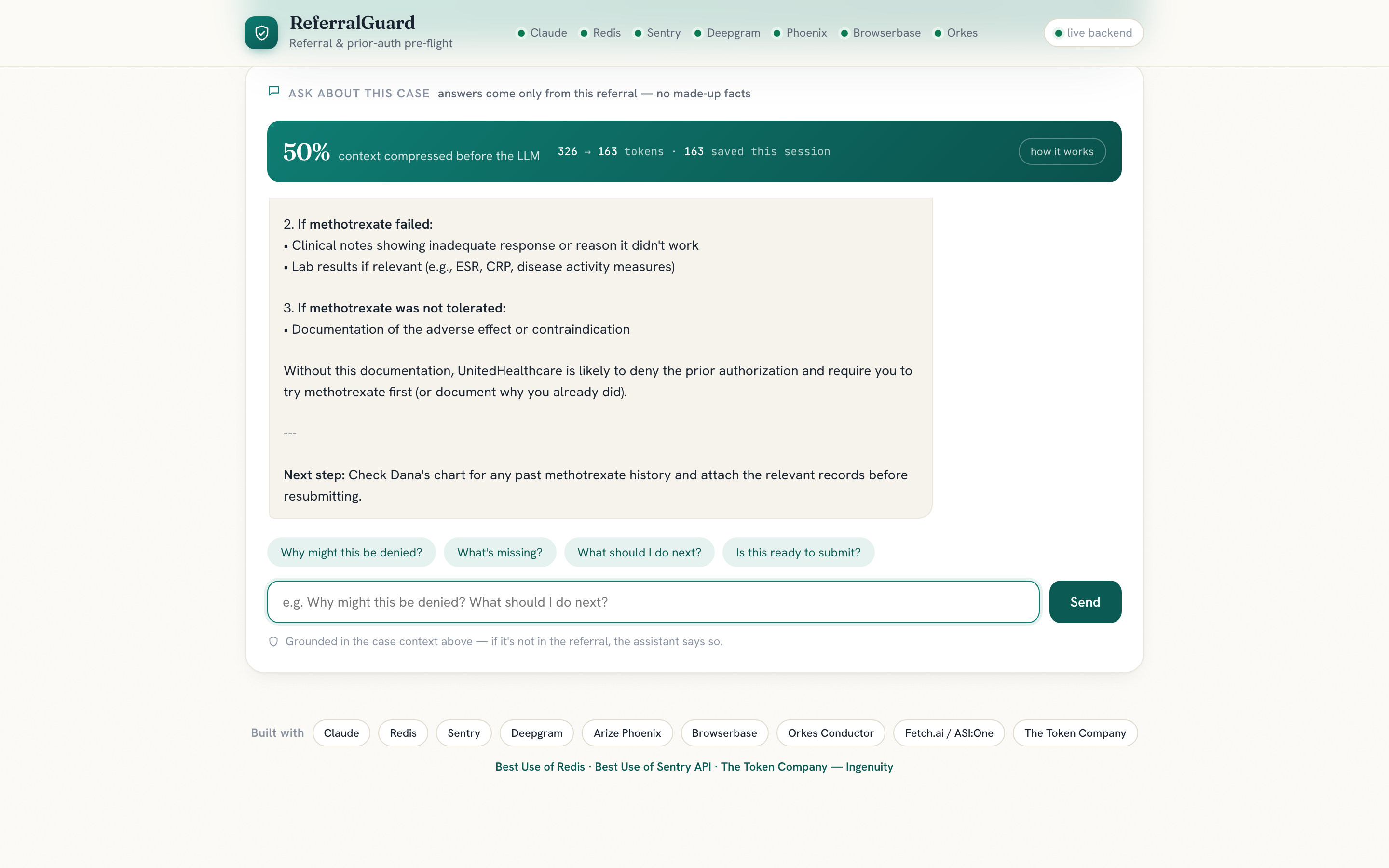
- a grounded case chatbot that answers only from that referral, so it won't invent clinical facts
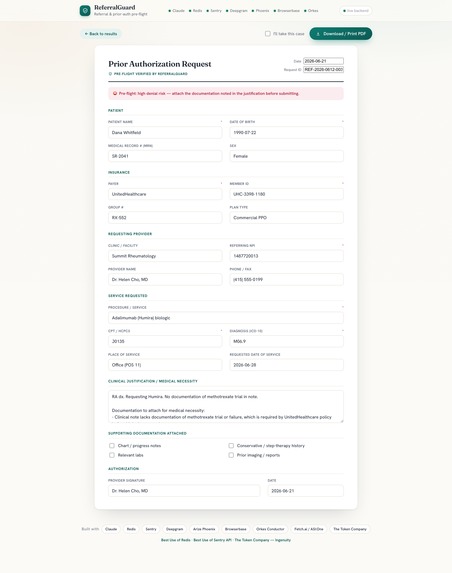
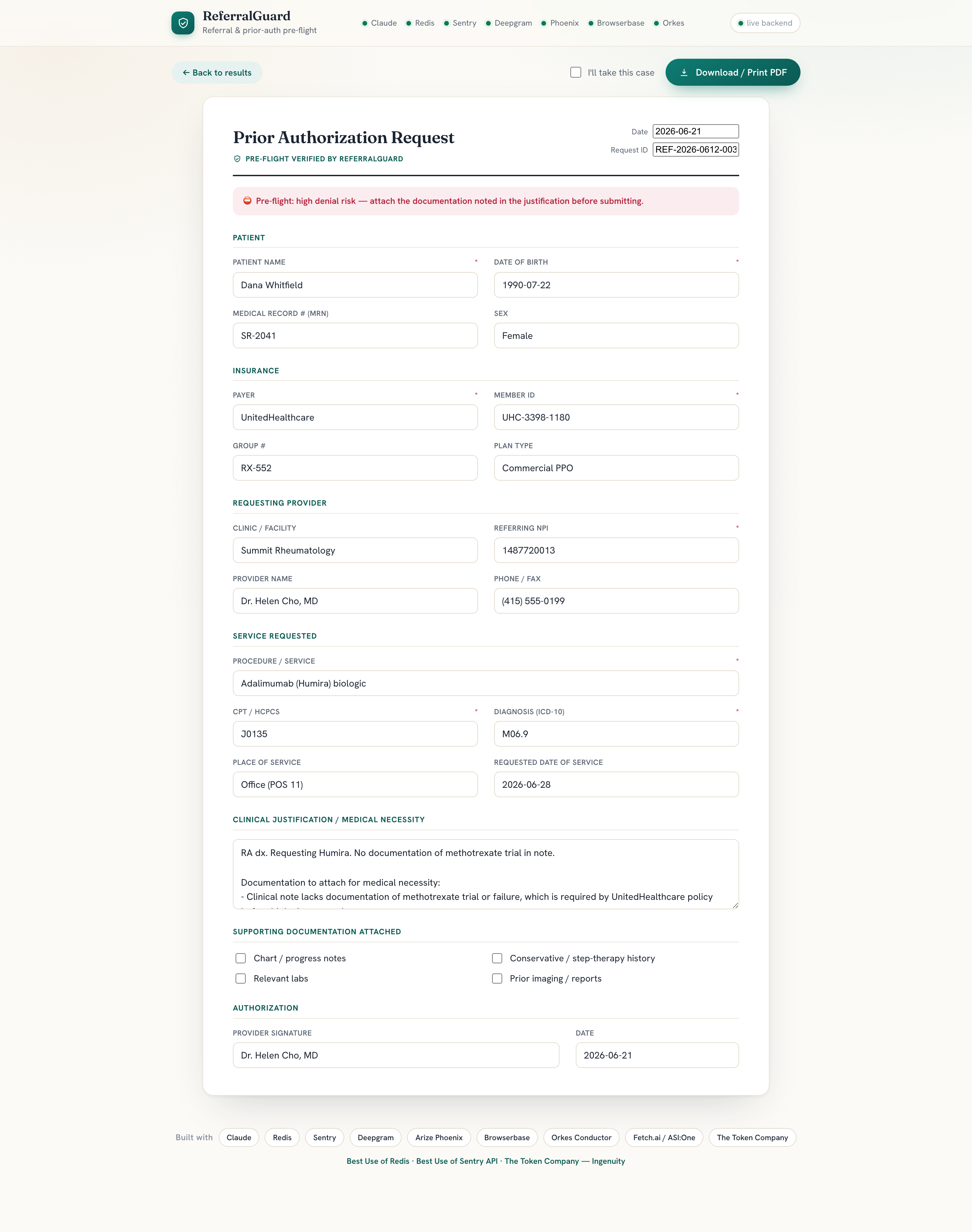
- an auto-filled prior-auth form you can download as a PDF
- the ROI: time and denial cost saved, per referral, per day, per month
If a request is clean, a human approves and a real headless browser submits it to the payer portal and returns a confirmation number.
🧠 How we built it
It's a real agent pipeline, not a prompt wrapper. Each agent emits one timestamped step:
Intake → Extraction → Completeness → Validation → Denial-Risk → Decision → Approval → Submission
- Claude: field extraction, denial-risk reasoning, the grounded case chat
- Redis: inter-agent session state and the audit trail
- Sentry: captures the failure paths (e.g. an unreadable member ID) with breadcrumbs
- Deepgram (
nova-3): transcribes spoken phone referrals - Arize Phoenix: OTEL traces of every agent decision
- Browserbase: drives the live payer-portal submission over CDP
- Orkes Conductor: the human-approval gate prior auth legally requires
- Fetch.ai / ASI:One: ReferralGuard is also a discoverable uAgent. Describe a referral in plain English in ASI:One and get the verdict back with no UI, plus an agent-to-agent handoff.
- The Token Company: the chat compresses its own context before every model call
The compression is real and measured with the model's own tokenizer:
Reduction = 1 - (T_after / T_before) ≈ 0.5
A Claude guard then verifies every decision-critical field survived compression and restores it if not, so we cut tokens with no quality loss.
The ROI panel is honest arithmetic, live on a slider: Monthly Savings = D × (r_time × c_staff + p_deny × c_rework) × W
where: D = referrals per day
r_time = hours saved per referral
c_staff = staff cost per hour
p_deny ≈ 0.15 (first-pass denial rate)
c_rework ≈ $43 (rework cost per denial)
W = working days per month
🧗 Challenges we ran into
- Bleeding-edge Python. We were on Python 3.14, and half the SDKs had no wheels yet.
greenletwouldn't compile, which blocked Playwright; a newer pin fixed it. - The Browserbase bug that looked like success. Submissions silently fell back to "retry" with no confirmation. The cause: Playwright's sync API can't run inside FastAPI's asyncio loop. Moving the pipeline into a threadpool made the real browser submission complete.
- Fetch.ai on 3.14. The uAgent crashed at startup because
uagentsrelied on the implicit event loop Python 3.12+ removed. Creating a loop before building the agent fixed it. - Keeping it honest. Everything degrades to a clearly labeled mock with no keys, but each engine is a real SDK call when live, and we made the "live vs mock" line explicit so judges can trust it.
📚 What we learned
- "Looks like it works" and "actually works" are different projects. The most valuable hours went to chasing two silent failures end to end.
- The best agent UX for a non-technical user (a doctor) is plain language plus a reason for every decision. The audit trail is the product.
- Context compression isn't just a cost trick. With a verifier guard it keeps agents fast and faithful.
🚀 What's next
Real payer-policy feeds instead of our 3-rule knowledge base, EHR and fax connectors, and a fine-tuned small model as the dedicated context compressor.
Built With
- agentverse
- anthropic-claude
- arize-phoenix
- asi-one
- browserbase
- css
- deepgram
- fastapi
- fetch.ai
- html
- javascript
- opentelemetry
- orkes-conductor
- playwright
- python
- redis
- rest-api
- sentry
- the-token-company
- uagents
- uvicorn



Log in or sign up for Devpost to join the conversation.