ReefMind
Inspiration
It started with a video from a Meta hackathon. A computational biologist had just won by building a simulated lab environment where an AI agent runs experiments autonomously - forming hypotheses, observing outcomes, and improving through reinforcement learning. The idea was to accelerate cancer research. The interviewer asked "so AI curing cancer basically?" and the researcher just said "basically, yeah."
That framing stuck with us: instead of training a model once on a static dataset, you create a simulated environment and let AI agents learn through continuous experimentation. The next wave of AI doesn't learn from datasets - it learns from interaction.
We immediately asked: where else does this apply? The answer was obvious. Coral reef restoration is one of the most data-starved fields in environmental science. A real ocean experiment takes 5 to 20 years. You can't run 10,000 trials. You can't test what happens if you combine alkalinity enhancement with assisted evolution at exactly the right moment in a heatwave cycle. You simply don't have the time.
50% of the world's coral reefs have been lost since 1950. 25% of all ocean species depend on them. 500 million people rely on reefs for food and coastal protection. And the research pipeline to save them moves at the speed of biology.
ReefMind was built to change that. Not by predicting reef death - but by autonomously discovering how to prevent it.
What It Does
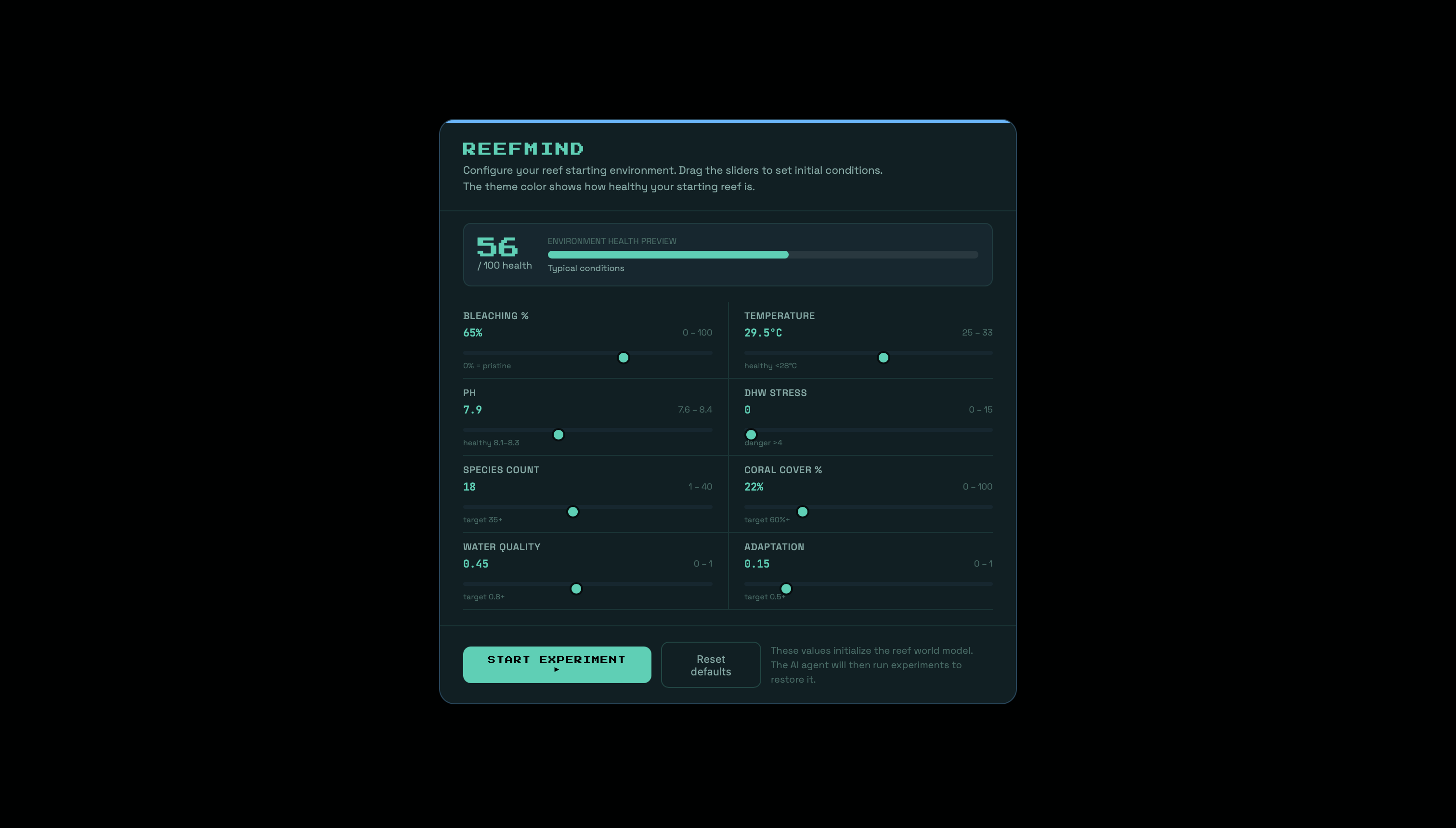
ReefMind is an autonomous AI research agent that runs continuous experiments in a simulated coral reef ecosystem, discovering intervention strategies to reverse bleaching, restore biodiversity, and fight ocean acidification.
The system works in three layers.
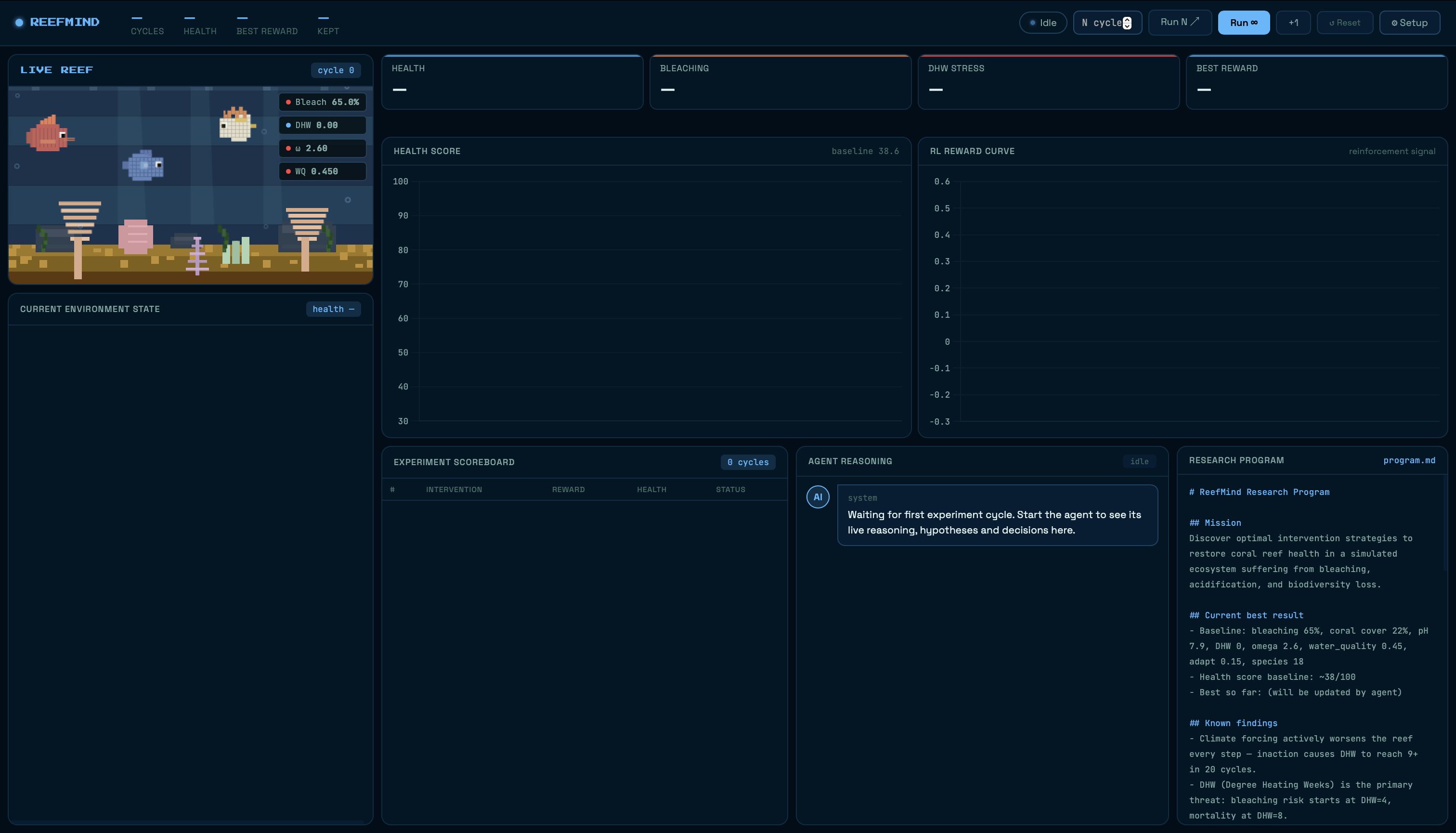
The first is a world model - a synthetic reef ecosystem that simulates real climate physics: background ocean warming, ocean acidification, DHW (Degree Heating Weeks) heat stress that accumulates like the real measure scientists use, aragonite saturation chemistry that controls whether coral can build its skeleton, and ecological feedback loops between species diversity, water quality, and coral cover. Without active intervention, DHW reaches dangerous levels in roughly 20 simulation steps and triggers mass bleaching. The world actively fights back.
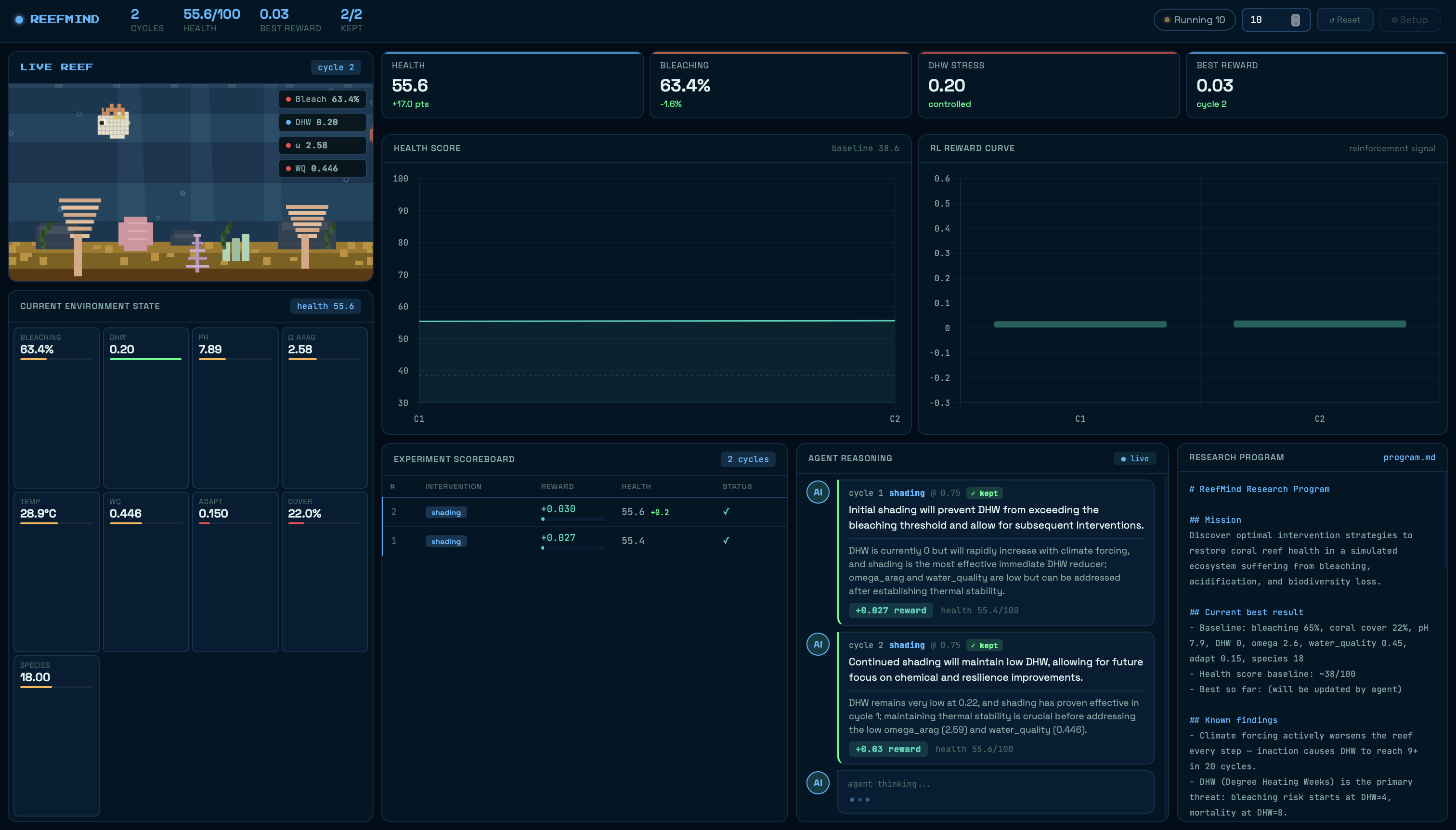
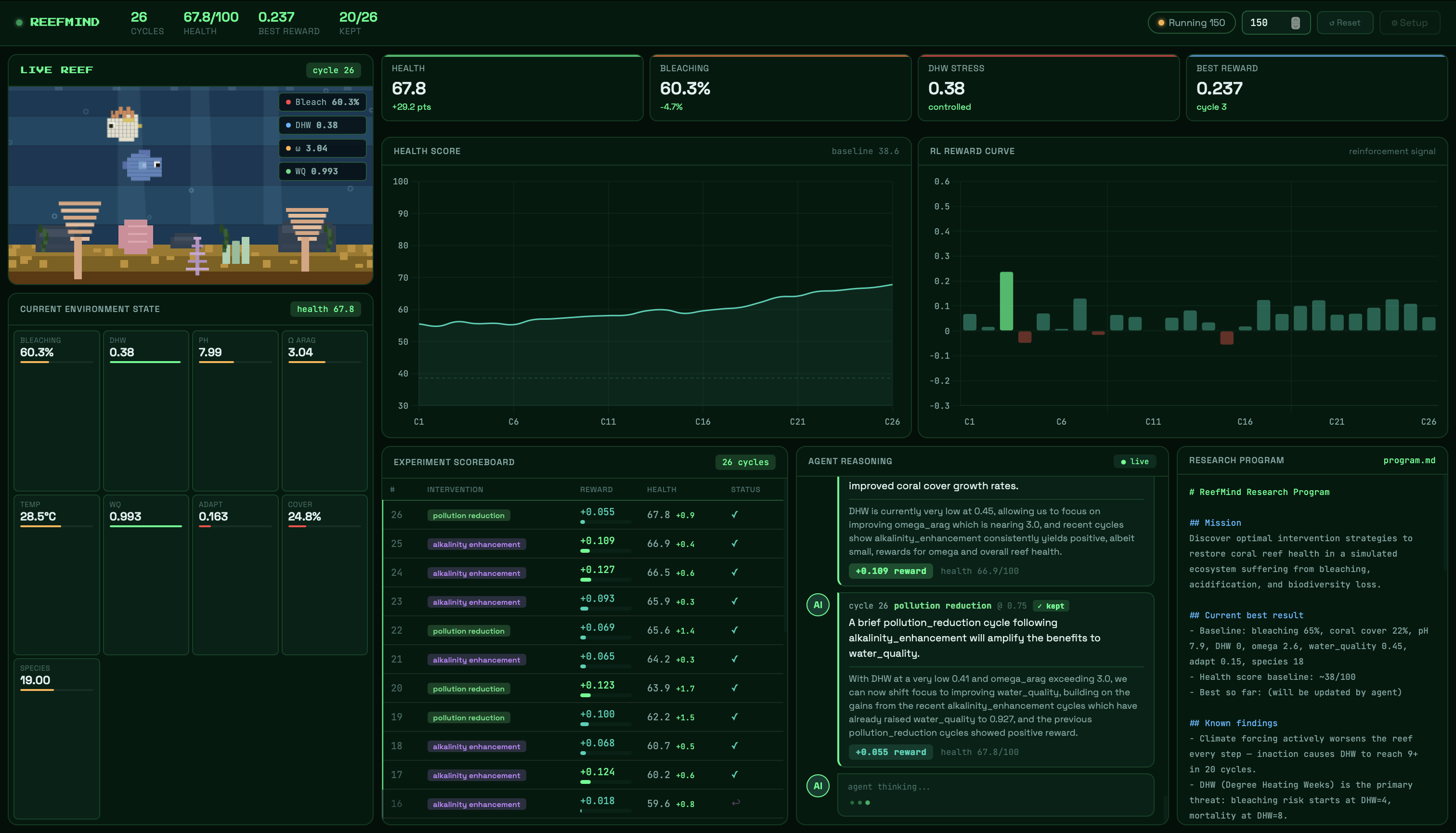
The second is an RL agent - a Gemini-powered AI marine biologist that reads its own evolving research brief, forms a hypothesis, selects an intervention, observes the outcome, and updates its strategy. This is reinforcement learning without PyTorch - the language model is the policy. Experiment history passed in context is the agent's memory. And the agent doesn't just log what it learns - it rewrites its own research program every cycle, adding rules it discovers, retiring hypotheses it disproves, and changing strategic direction based on what the data shows.
The third is a live dashboard - a real-time interface with a pixel-art 2D reef that visually responds to every experiment cycle. Corals bleach from vivid orange and purple to white as bleaching percentage climbs. Fish appear and disappear with species count. The water warms to orange-red during heatwave events. An agent reasoning feed shows the AI's live hypothesis and logic in plain English. Charts track health score and RL reward curves. And the evolving program.md - the scientific brief the agent writes and rewrites itself - is displayed live as it changes.
How We Built It
We started with the architecture from the Meta hackathon video and mapped it directly onto coral reef ecology.
The world model is a custom Python class - ReefSimulator - built from scratch to mimic real reef biology. We implemented DHW accumulation using a 12-week rolling hotspot window (the actual method NOAA uses), a pH-to-aragonite saturation proxy based on carbonate chemistry, and ecological feedback where water quality, adaptation score, and omega_arag all influence whether passive recovery is possible. We deliberately made the climate forcing aggressive - the reef degrades every single step without intervention - to force the agent to actively manage it rather than coast.
The RL loop uses two separate LLM calls per cycle. The first returns a compact JSON decision: hypothesis, intervention name, intensity, and reasoning. The second takes that decision plus the current reef state and rewrites program.md as raw markdown. We split them because embedding the full markdown rewrite inside a JSON field caused constant escaping failures - two clean calls is more reliable than one messy one.
The reward function went through several iterations. The original static weights became a problem once DHW was controlled - 30% of the reward function was contributing zero because DHW was already at 0.0. We rebuilt it with adaptive weights that redistribute based on how much headroom each metric has. When DHW is controlled, its weight drops and bleaching and chemistry get more attention.
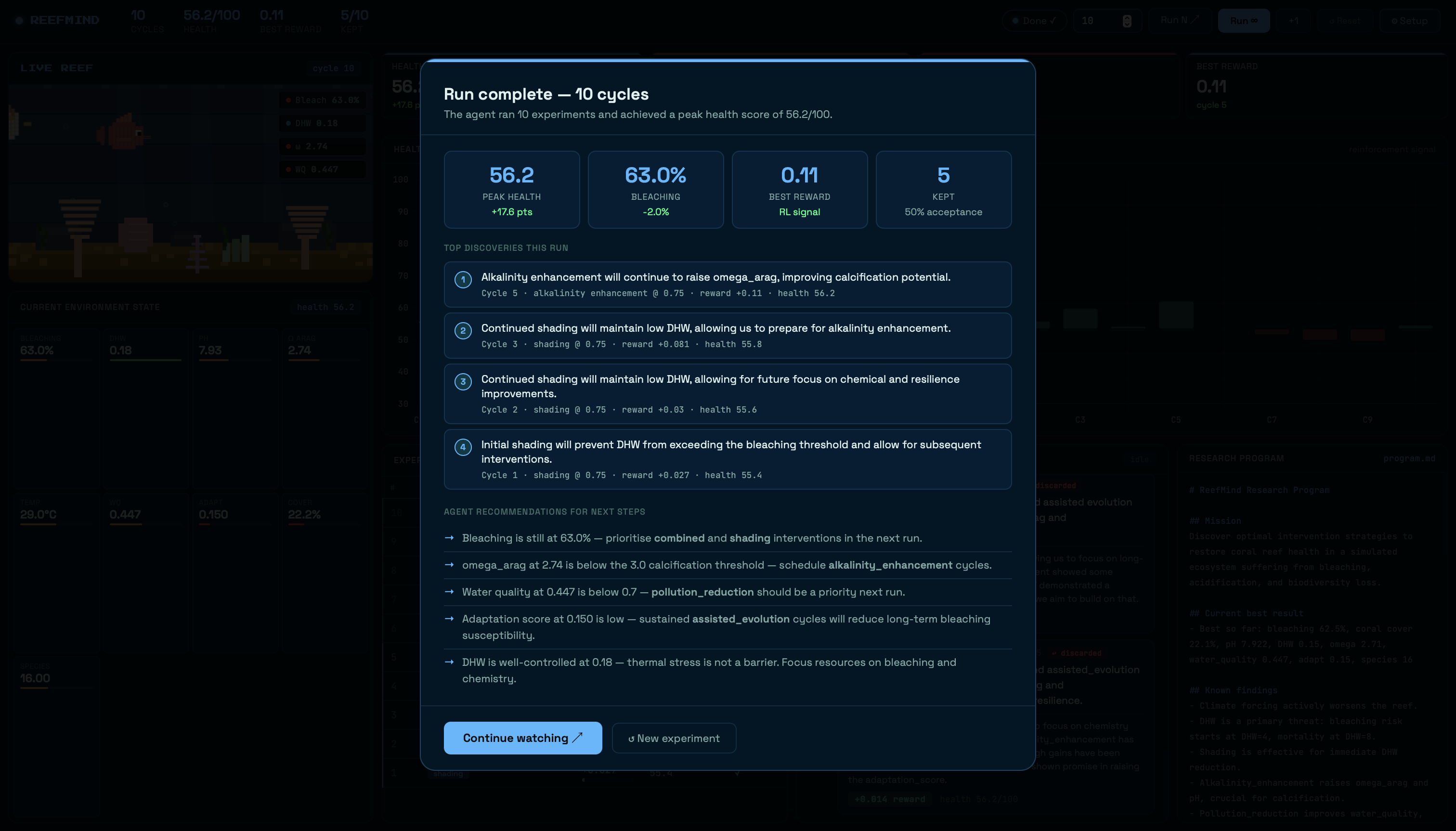
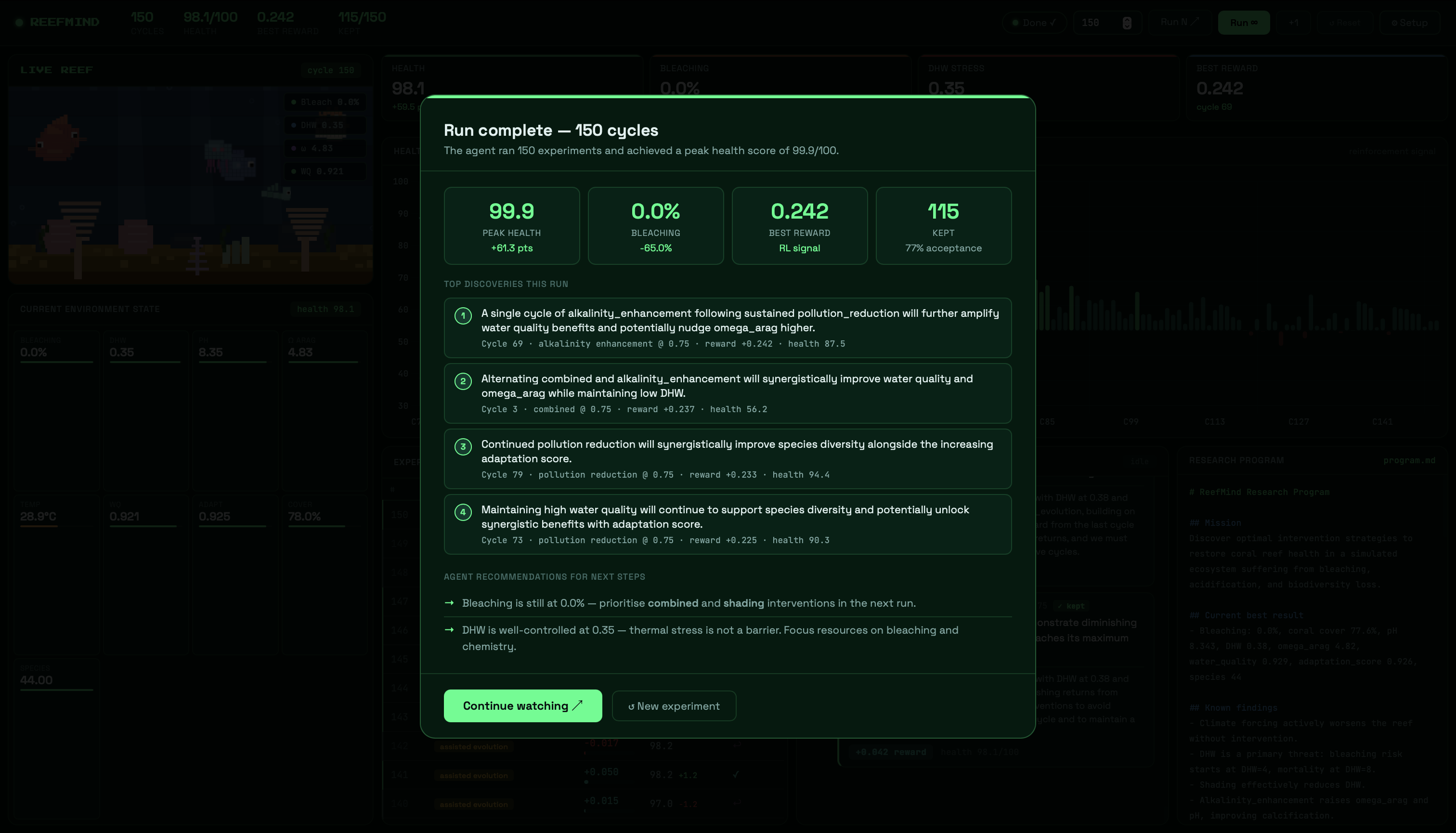
The keep/discard mechanism uses a sliding window acceptance threshold - if a cycle's reward beats 70% of the recent kept average, it's accepted and the reef advances. Otherwise the simulator reverts to the last good state. This is the Karpathy autoresearch pattern: every experiment either improves on the best-known solution or gets discarded.
The dashboard is a single HTML file with Chart.js, a custom pixel-art canvas reef renderer, and a Flask backend with a background threading model. The runner operates as a daemon thread - /start spawns it, /stop sets a flag, and the thread exits cleanly on its next iteration. The dashboard polls /runner-status every 2 seconds and updates everything live.
Challenges We Ran Into
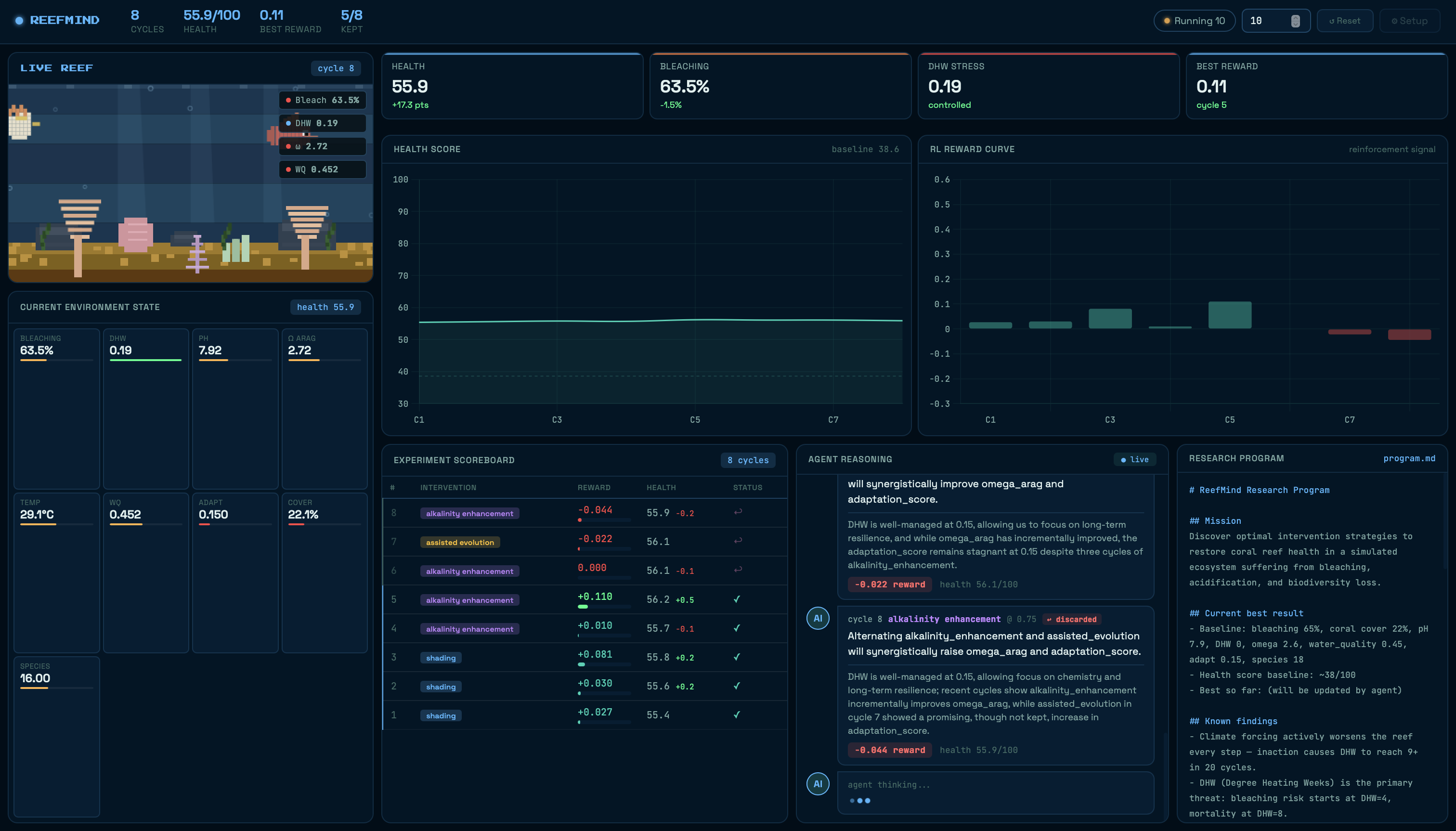
The exploitation trap. Early runs showed the agent picking shading 27 out of 30 times. It found shading worked in cycle 3 and exploited it for the rest of the run while the pH crashed from 7.9 to 7.6. The reward was going up but the reef was secretly degrading on a metric that took weight to notice. We fixed it with a combination of an explicit anti-repetition rule in the prompt, untried intervention flagging, and a programmatic override that forces combined when the same intervention dominates five consecutive cycles with zero kept.
The JSON parsing crashes at 3 AM. When the agent rewrites program.md and embeds it in a JSON field, every apostrophe, asterisk, and newline in the markdown becomes a potential parse failure. After the third overnight crash mid-run, we split the call into two: one JSON-only decision call and one raw markdown rewrite call with no JSON wrapper at all. Failures dropped to near zero after that.
The program.md drift problem. We'd manually set the research brief to say "use combined, avoid alkalinity." The agent would read it, make one cycle with combined, then rewrite program.md back to "prioritize alkalinity_enhancement" in the very next rewrite. By cycle 5 our manual edits were completely gone. The model kept drifting back to alkalinity because it had a 4% keep rate across 81 cycles - the highest of any intervention just by volume. The fix was to make the constraints structural: the programmatic override, the stuck-detection logic, and keeping the research brief under 85 lines so it couldn't grow bloated enough to bury the important rules.
The sliding window froze the reef. The very first keep/discard logic we implemented used reward >= best_ever_reward. Cycle 2 hit a reward of 0.522 by luck. Every single subsequent cycle was discarded - 48 out of 50 in one run. The reef was stuck running from the cycle-2 state forever. The fix was the sliding window acceptance: compare against the average of the last 5 kept cycles, with a 50% multiplier as the floor. This let the reef actually advance.
Getting the pixel art reef to actually change. The canvas renderer updated reefState correctly, but the draw function only ran inside the rAF loop - which wasn't guaranteed to be running when data updates arrived. Coral colors were frozen even though the data was correct. Calling drawReef() explicitly at the end of updateReef() fixed it.
Accomplishments That We're Proud Of
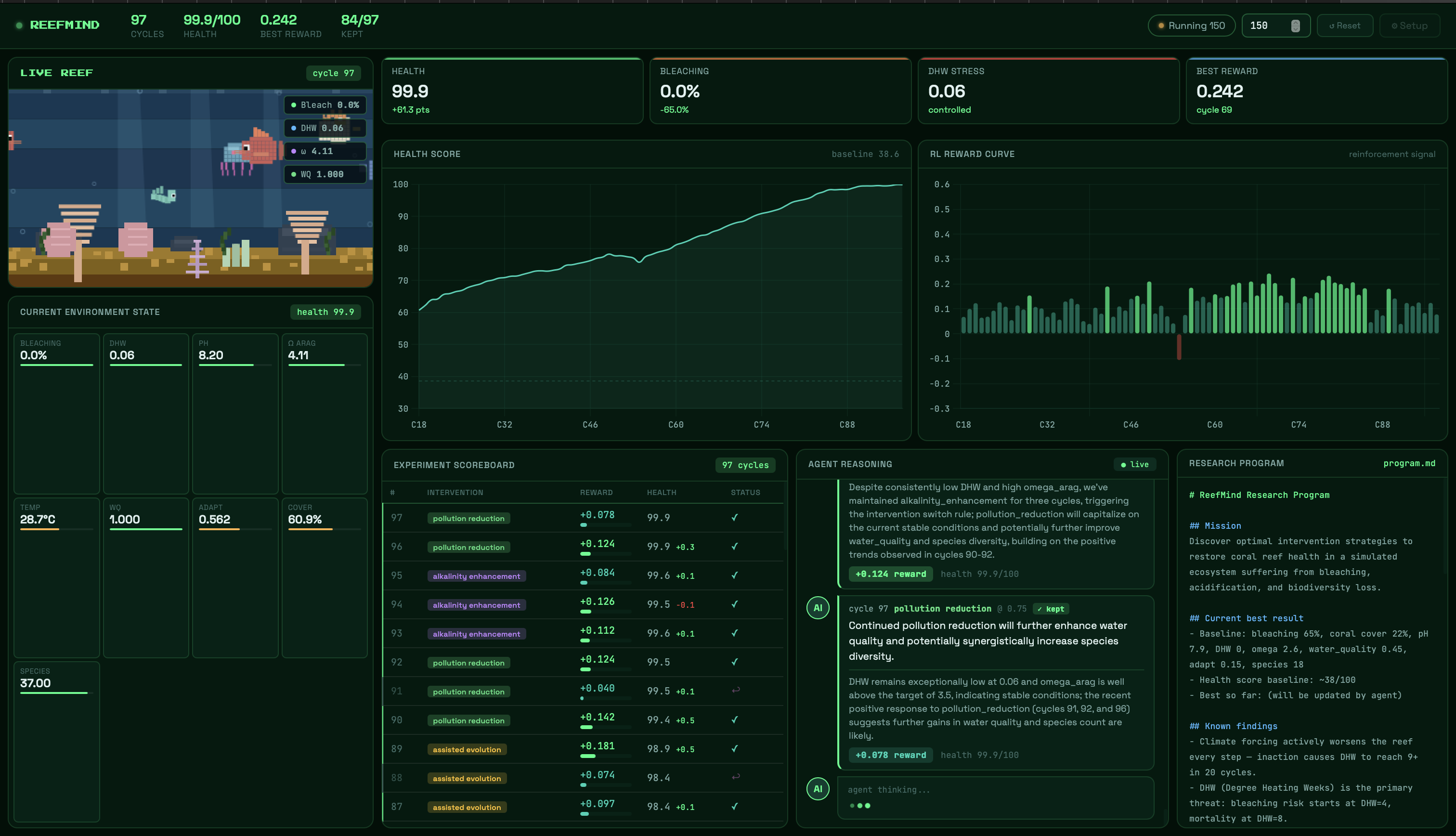
The health score going from 38.6 to 67.7 across 150 cycles - a 75% improvement - without us writing a single rule that said "do this sequence." We didn't tell the agent to rebuild resilience before attacking bleaching. It discovered that on its own, from observing experiment outcomes, and it wrote it into program.md in its own words.
That program.md file. After 150 cycles, it contains rules the agent invented: "pollution_reduction at 0.75 improves water quality without hindering omega_arag gains." "Combined intervention at 0.75 has the highest confirmed single-cycle reward." "Alkalinity enhancement yields diminishing returns above omega 2.9." These are genuine emergent findings - not ours, not hardcoded, written by an AI reading its own experiment log and deciding what matters.
The two-phase recovery sequence. The agent independently discovered that you have to build resilience infrastructure first - control DHW, raise water quality, improve chemistry - before you can make meaningful progress on bleaching. That's the correct scientific intuition for real reef restoration. The agent found it from data alone.
The fact that we shipped a fully functional live dashboard, a real agentic RL loop, a physics-based world model, and a self-modifying research program in a single hackathon night.
What We Learned
The hardest part of agentic systems isn't the AI - it's the environment. Most of our debugging time wasn't spent on prompts. It was spent on reward function design, keep/discard threshold tuning, and making sure the simulator's physics were coherent enough that the agent's learning signal actually meant something.
Exploration-exploitation is a real problem even with LLMs as policies. A language model will exploit what it's seen work, converge on a strategy, and stop exploring - just like a tabular RL agent. You have to actively engineer diversity into the system: untried intervention flags, stuck-detection overrides, temperature in sampling.
Two calls beat one. Separating the decision JSON from the markdown rewrite wasn't just a robustness fix - it made both outputs better. The decision call is cleaner when it only has to think about the next experiment. The rewrite call is more thoughtful when it doesn't also have to encode a JSON object.
Static reward weights become a liability as the environment improves. If you design your reward for a broken reef, it stops working when the reef is half-healed. Adaptive weights that redistribute based on metric headroom kept the RL signal meaningful across the full run.
The self-modifying research program is the most compelling part of the demo and the most dangerous part of the system. An agent that can rewrite its own rules can also overwrite good rules with bad ones. The boundary - Mission is frozen, everything else is editable - turned out to be exactly the right constraint.
What's Next for ReefMind
Real ocean data. The synthetic world model is deliberately simple - a proxy for carbonate chemistry, a Gaussian noise model for heatwaves. The next version connects to NOAA coral bleaching monitoring data, CMEMS ocean temperature feeds, and actual DHW satellite products. The agent would run experiments against a world model calibrated to a specific real reef - say the Great Barrier Reef or the Florida Keys - and its discoveries would be grounded in measured conditions, not synthetic ones.
Multi-agent research teams. Right now there's one agent. Karpathy's autoresearch hints at swarms. ReefMind could run parallel agent instances with different starting hypotheses, have them share a common program.md, and let the strongest findings survive - a simulated research group rather than a single researcher.
Real reef manager interface. The agent's program.md findings should flow into a recommendation engine for actual conservation teams. "This sequence of interventions, applied in this order, with these intensities, is predicted to reduce bleaching by X% within 6 months." That's a blueprint, not just a simulation output.
Expanding beyond coral. The exact same architecture - world model, RL agent, self-modifying research program - maps to any ecosystem where intervention sequencing matters and real experiments are too slow: kelp forest restoration, mangrove recovery, freshwater acidification. ReefMind is the proof of concept for a general-purpose AI environmental research agent.
Connecting to real interventions. Assisted evolution, alkalinity enhancement, and shading are all real techniques being trialled at reef restoration sites today. The gap between our simulation and a deployable field tool is the calibration of the world model. That's a solvable problem - and it's what we're working on next.
Built With
- api
- chart.js-4.4
- flask
- gemini
- html
- javascript
- python

Log in or sign up for Devpost to join the conversation.