-
-
Reeder AI home screen
-
Docs uploaded (left sidebar)
-
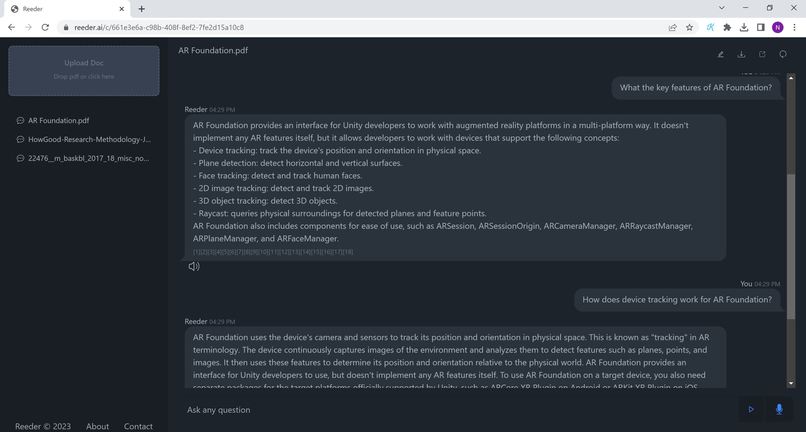
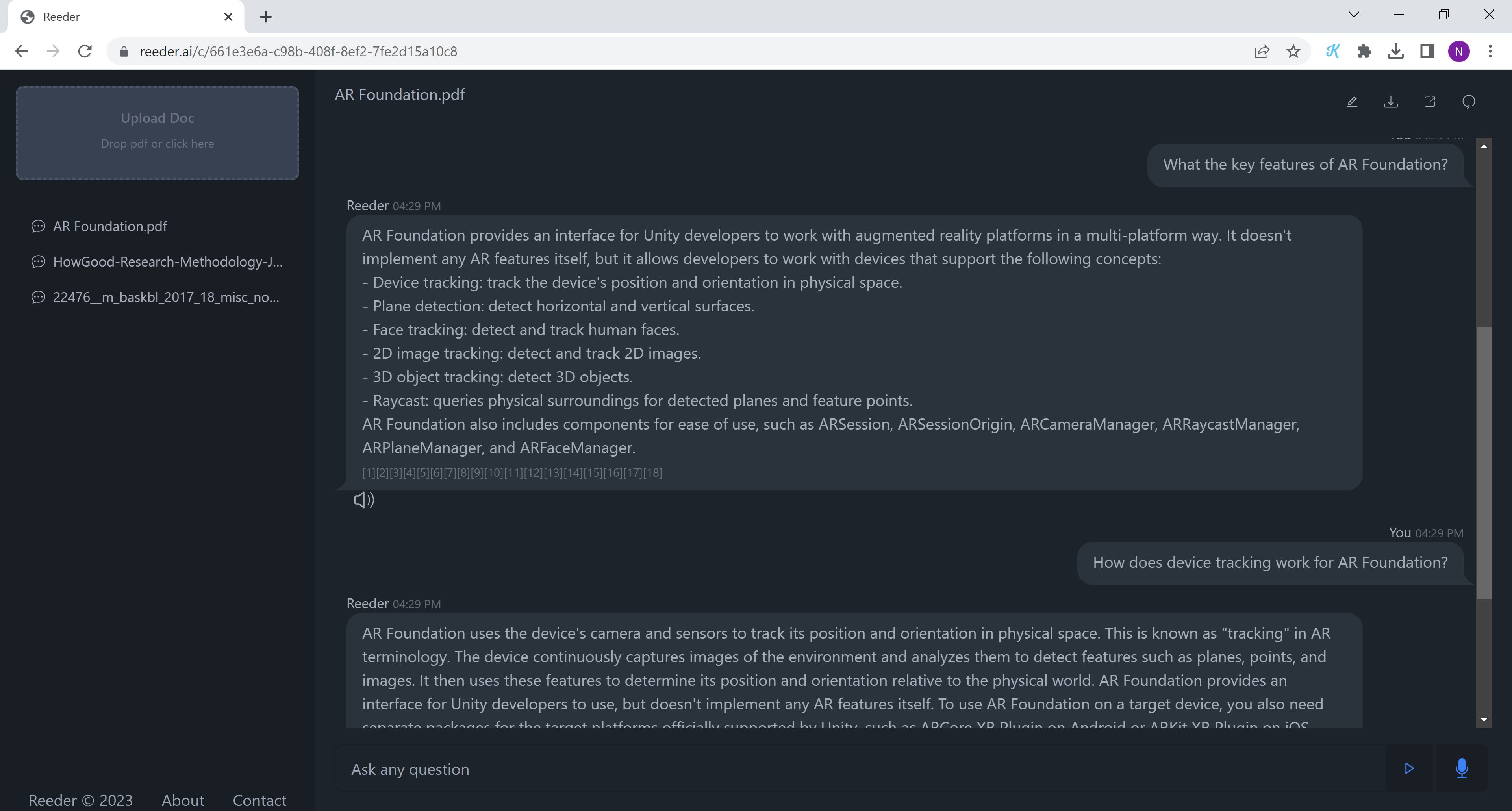
Q&A on document
Summary
LLMs like ChatGPT are trained on the overall Internet to answer questions based on “general knowledge.” However, LLMs do not answer questions well from documents they were not trained on. Although "context windows" are increasing in size, LLMs are still limited in their ability to do Q&A on large documents because LLM inputs are limited (10-300 pages depending on the LLM).
Reeder AI allows LLM-based Q&A on large documents (up to 2,000 pages) or collections of documents (coming feature).
Inspiration
We were inspired to create Reeder based on the problems we see our friends having in their everyday jobs. Excessive documentation has invaded industries - law, finance, consumer, tech, insurance, etc. People we know often spend hours finding specific answers to questions buried in large corporate document stores. LLMs can simplify this process.
LLM technology was not advanced enough to help solve the problem we have described here until 6 months ago.
What it does
LLM context windows (the amount of input text they can receive) are limited in size. When a user asks a question about a document to an LLM, Reeder intelligently picks the parts of the document that are relevant to the question. It then feeds those parts to the LLM in order to generate an answer.
To do this Reeder separates uploaded documents into chunks, and then stores the embeddings for each chunk in Pinecone's vector DB. When a user asks a question, Reeder runs a similarity search between the question embedding and document embeddings to determine the most relevant parts of the document (chunks) to the question. These chunks are then used to create an LLM query to get a good answer to the question.
We used Pinecone, Langchain, OpenAI, and Hugging Face to build our project.
Challenges we ran into and what we learned
The most difficult part of solving this problem involves the engineering details around how to efficiently chunk documents and store them for fast retrieval. In particular, we wanted our system to show users the sources (parts of a document) which the LLM is using to answer a question. Coming up with a vector DB structure to store chunk embeddings and metadata in a way that allows for efficient retrieval and for source information to be shown was the hardest part of the project.
We also experimented with prompt engineering to improve the answers the system is able to produce when doing Q&A on documents.
What's next for Reeder
Friends whom we showed reeder.ai to were surprised at the answer quality the system produces and the speed of the system in reading documents.
Some of the use cases we imagine include: (1) Employees asking questions about HR documents through LLMs instead of by reading them; (2) Customer support docs being loaded into Reeder so that users can get their questions answered by LLMs instead of combing through support articles; and (3) Improved legal document search.
We are planning to build out more features next - Q&A over folders of many documents, chat history saving, and the ability to read an entire site (all pages) in one click and deploy a Q&A bot against it.
Built With
- appengine
- huggingface
- langchain
- nextjs
- pinecone
- postgresql
- python
- supabase

Log in or sign up for Devpost to join the conversation.