-
-
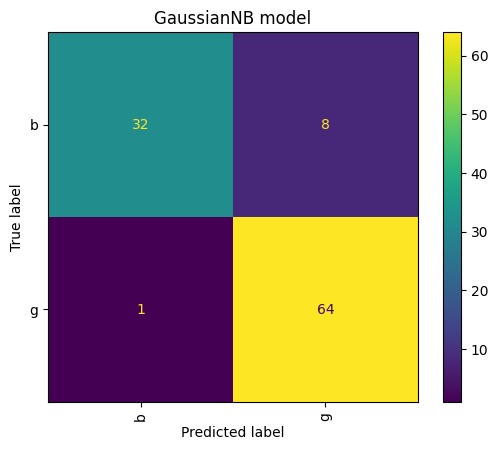
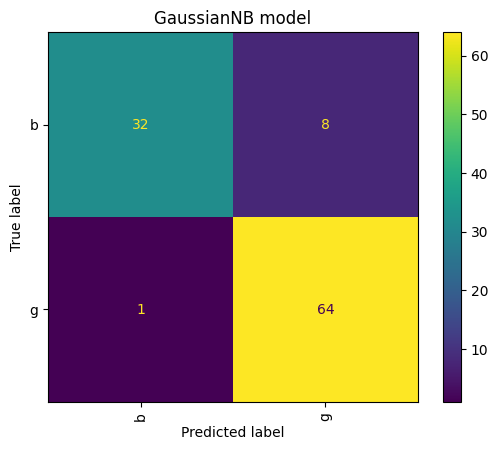
GN result for Upsampling for train data only
-
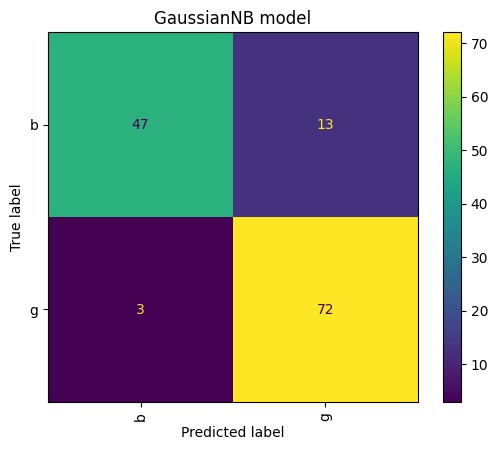
GN result for Upsampling for all data
-
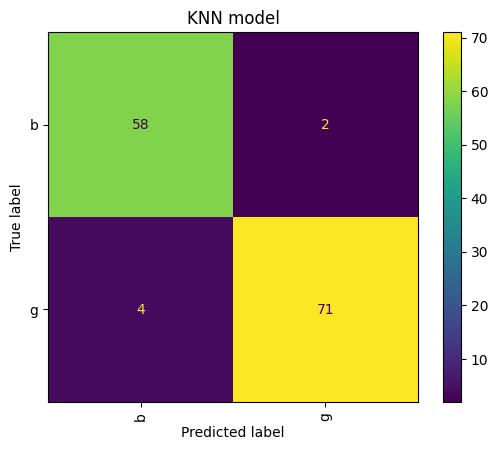
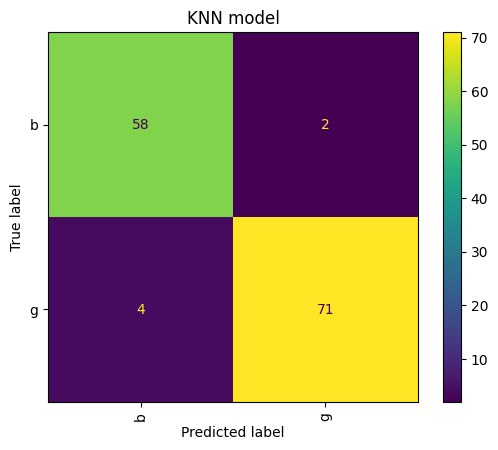
KNN model result

Project Goal
Feature reduction and classification are essential tasks in machine learning and data analysis. In this project, we aim to implement these tasks using Python and built-in libraries. The Ionosphere dataset, which contains 34 features, serves as our primary dataset. By applying Principal Component Analysis (PCA), we aim to reduce the dimensionality of the features while retaining key information.
Methods:
Feature Reduction with PCA:
- Implement PCA to reduce feature dimensions.
- Determine the optimal number of reduced features 's'.
- Explain the criteria for selecting 's' based on variance explained and cumulative explained variance.
Classification with Naive Bayes:
- Utilize different classifiers for classification tasks.
- Handle class imbalance issues by performing upsampling on the train set if required.
- Train the classifier on the train dataset.
- Evaluate the classifier's performance on the test dataset using confusion matrix, precision, recall, and F-score.

Log in or sign up for Devpost to join the conversation.