-
-
Landing Page
-
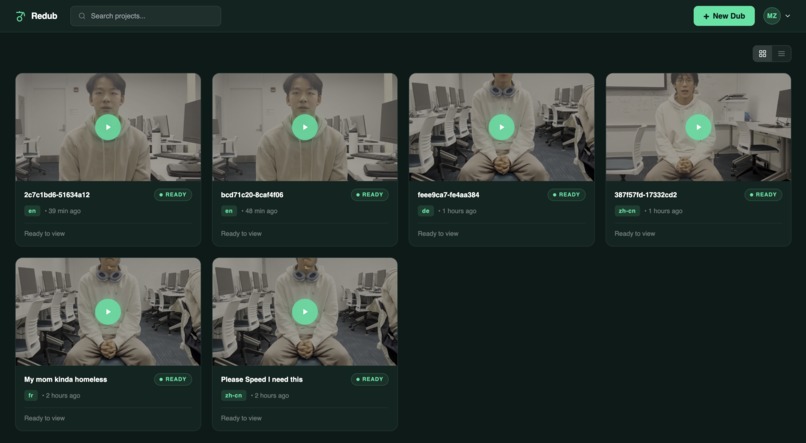
Dashboard
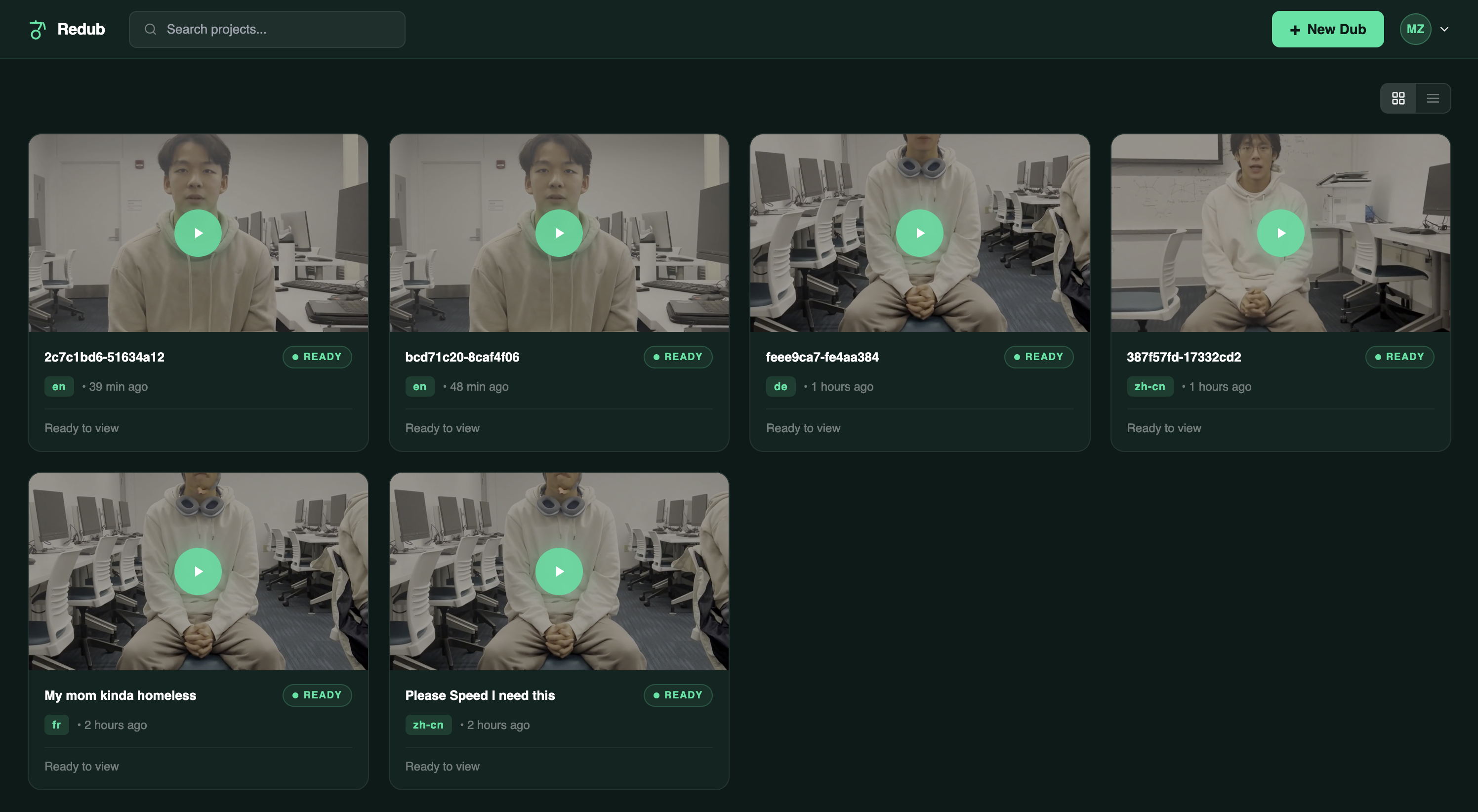
-
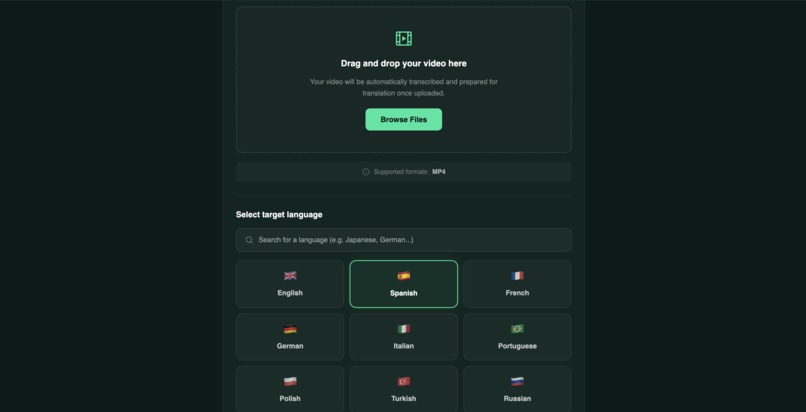
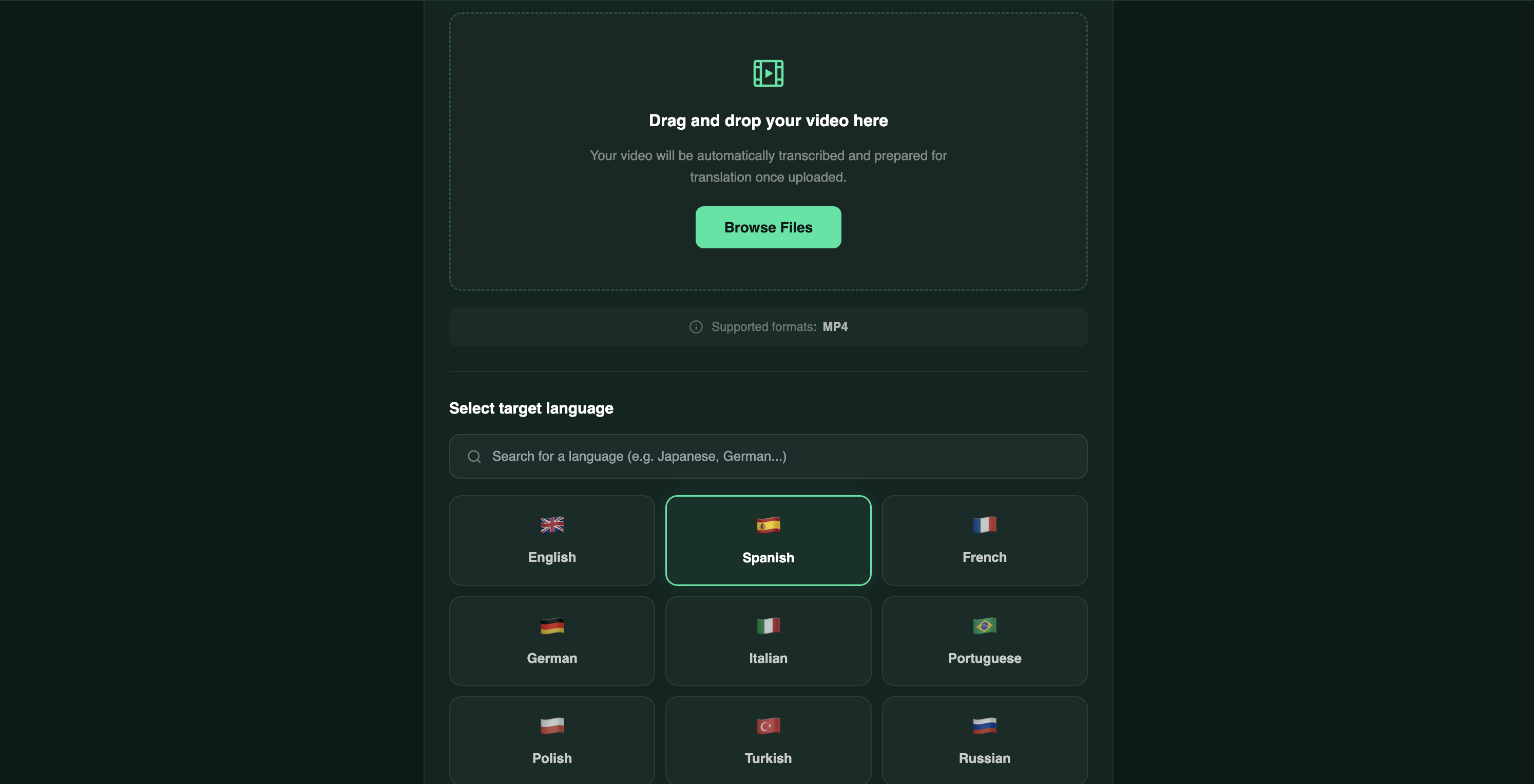
Video Upload and Language
-
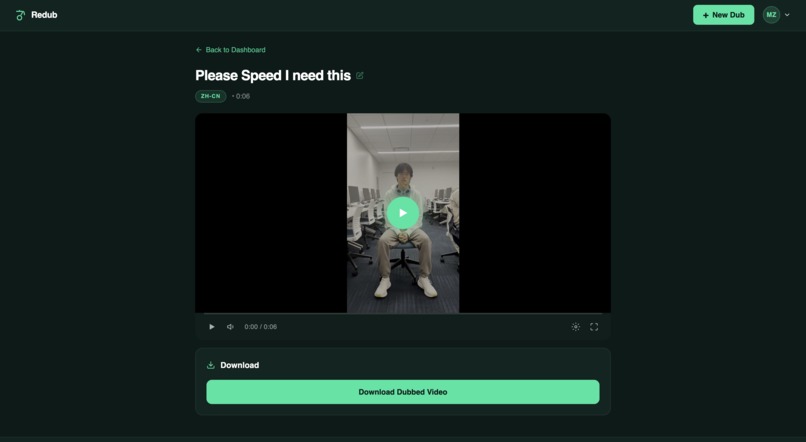
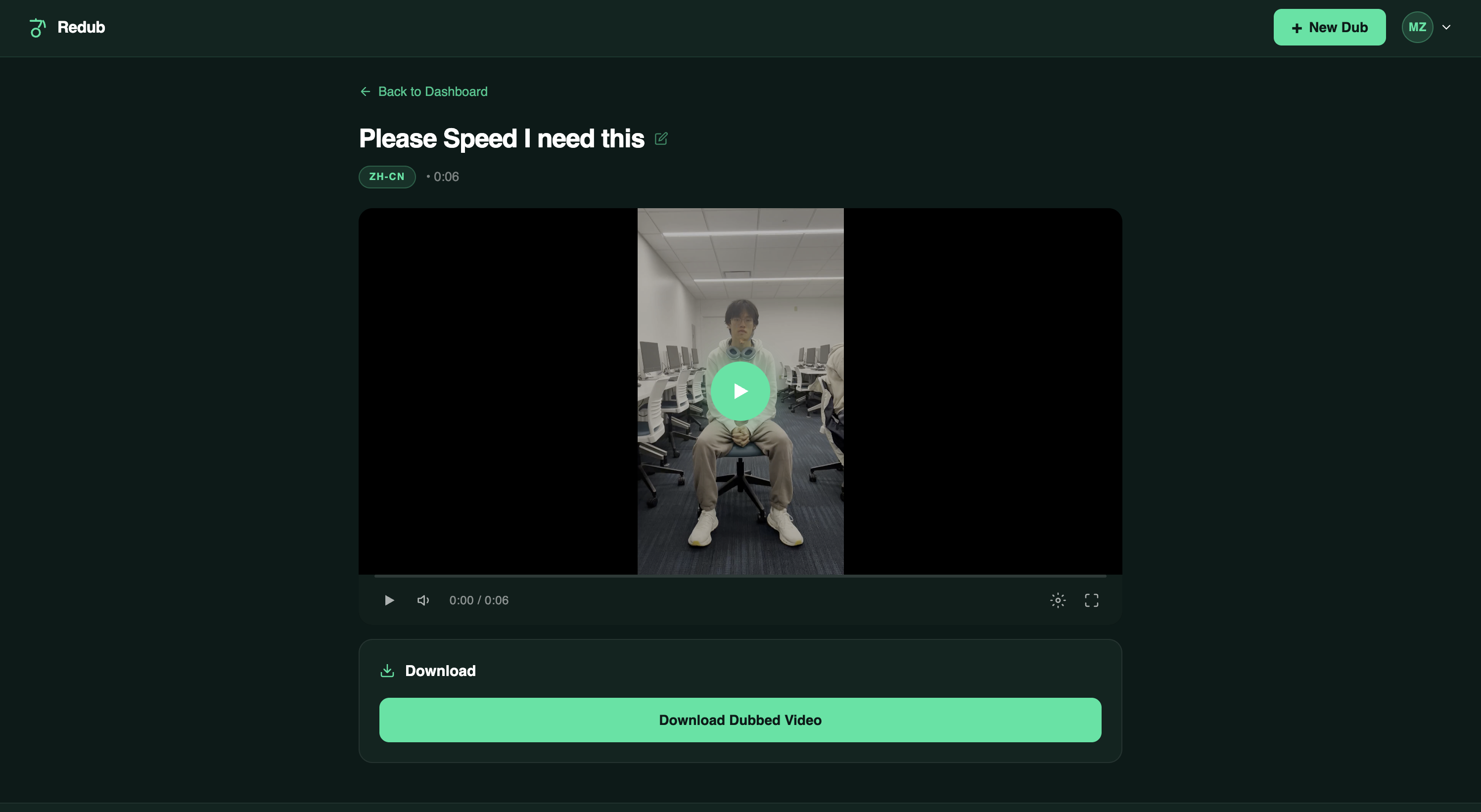
Video Preview
-
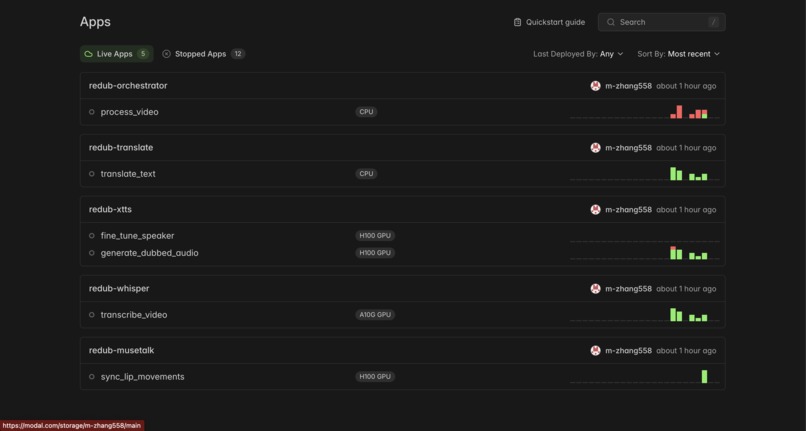
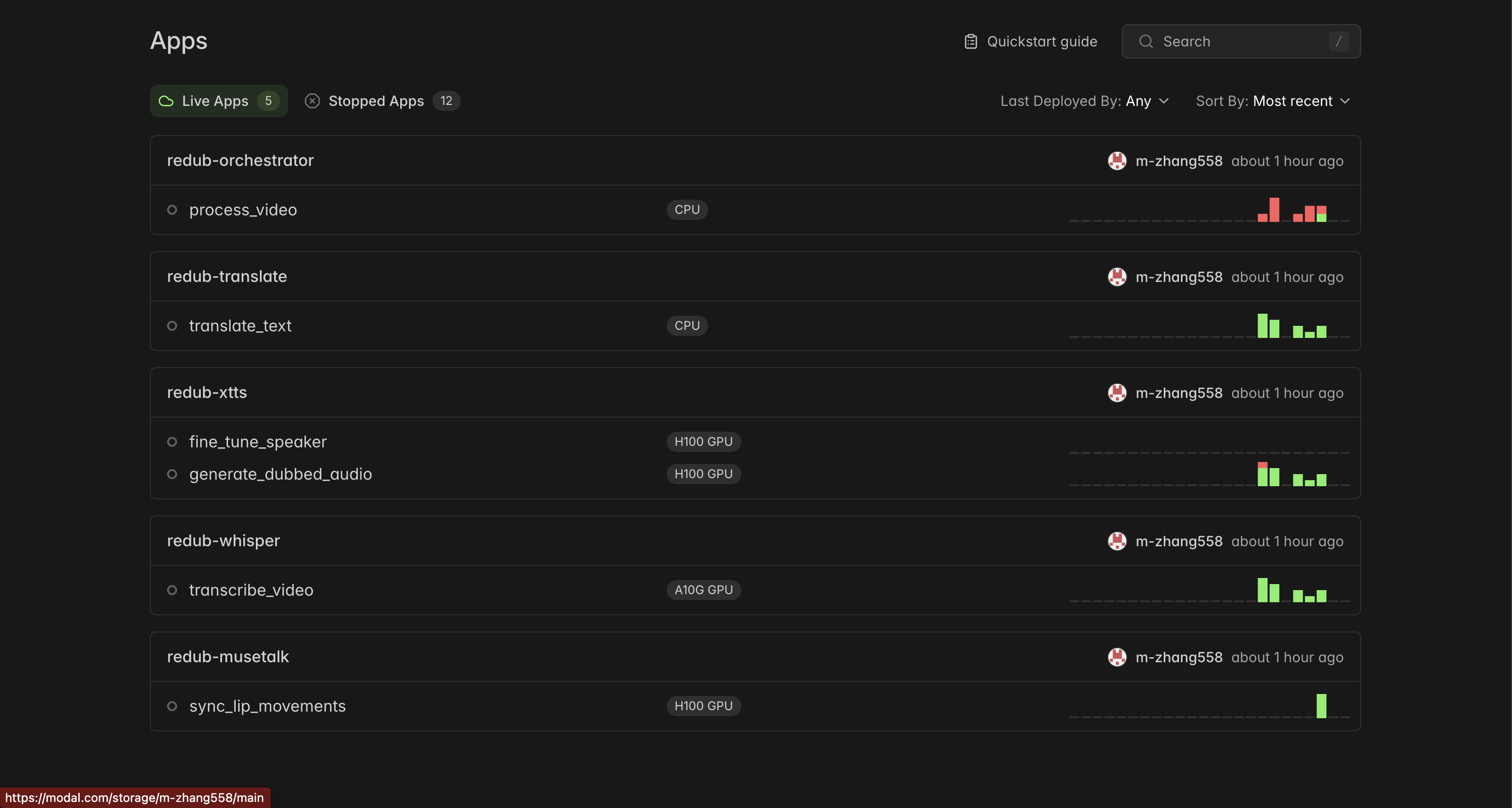
Modal Containers
-
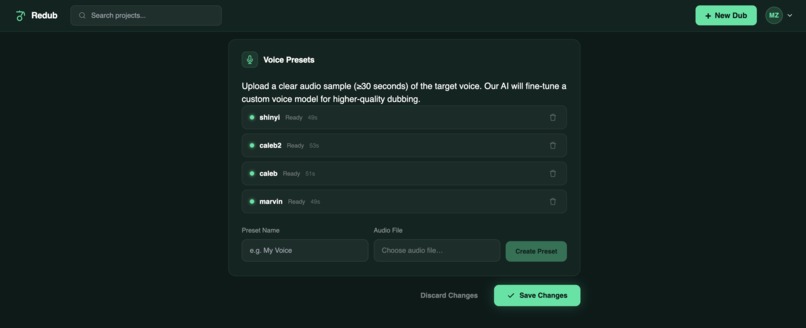
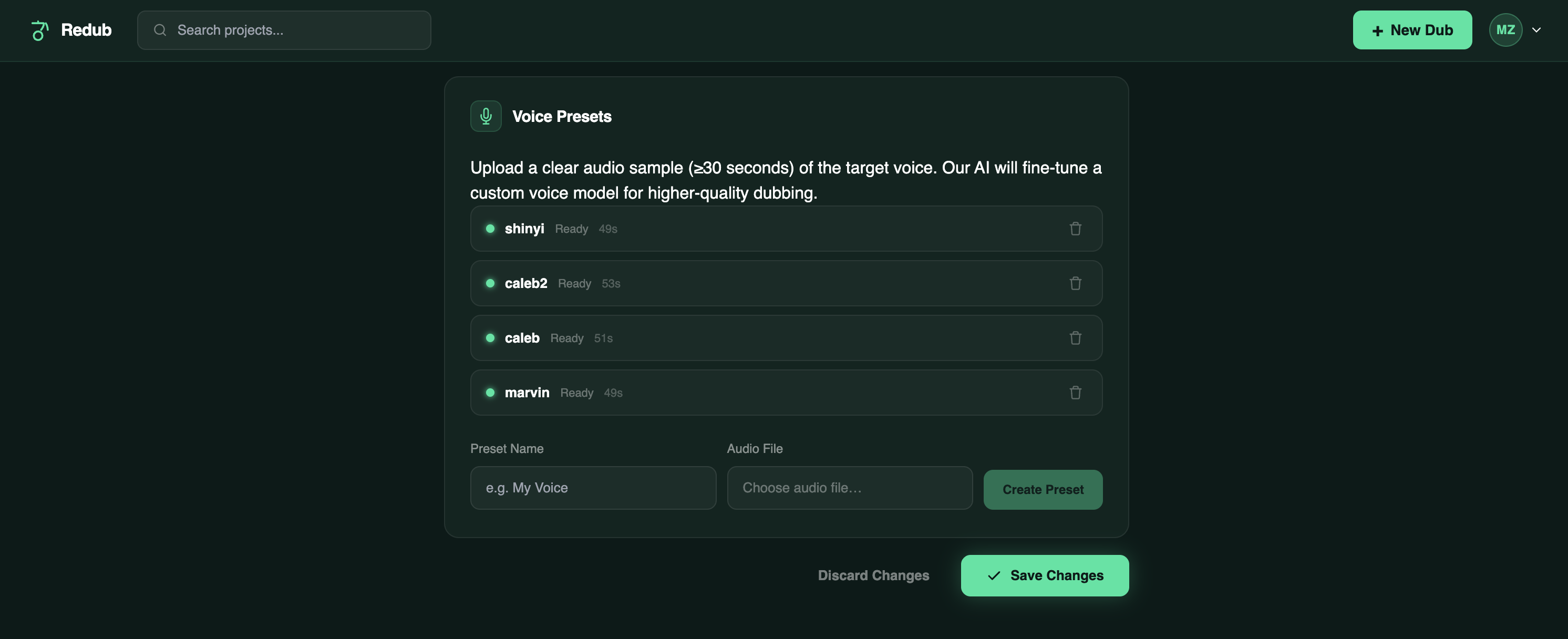
Voice Fine-Tune Settings
Inspiration
Professional video dubbing is expensive, slow, and inaccessible to most creators. Studios spend weeks manually re-recording dialogue, casting voice actors, and hand-animating lip movements. We wanted to automate that entire pipeline — transcription, translation, voice cloning, and lip sync — into a single serverless workflow that anyone can use.
What it does
ReDub takes a video and a target language as input and returns a fully dubbed video where:
- The original speech is transcribed with timestamps using Whisper large-v3
- The transcript is translated segment-by-segment using Llama 3.3-70B
- The dubbed audio is synthesized using XTTS v2 zero-shot voice cloning — the dubbed voice sounds like the original speaker
- Lip movements in the video are re-rendered using MuseTalk to match the new audio
Users can upload videos, track per-step pipeline progress in real time, name and organize their dubs, and download the finished MP4 directly from the dashboard.
How we built it
ML pipeline — Five independent Modal apps, each running on serverless GPU instances:
app_whisper.py— Whisper large-v3 on an A10G, returns timestamped segmentsapp_translate.py— CPU-only, calls Llama 3.3-70B to translate each segmentapp_xtts.py— XTTS v2 on an A10G, takes text + a 6-second reference WAV extracted from the source video and returns dubbed audio with duration matched to the original segmentsapp_musetalk.py— MuseTalk on an H100, takes the source video + dubbed audio and returns the lip-synced MP4orchestrator.py— CPU, chains the four apps viamodal.Function.from_name(), uploads the result to Cloudflare R2, and fires a webhook to the backend
Backend — FastAPI app with JWT auth, Cloudflare D1 for job and user records, and a presigned-URL flow for direct browser → R2 uploads. Webhooks from Modal update job status and trigger the frontend to redirect to the preview page.
Frontend — React 18 SPA with React Router v6. All styles are inline JS objects. The dashboard shows real-time pipeline progress (per-step polling), and VideoPreview has an inline-editable title that persists to the database.
Challenges we ran into
Lip syncing was by far the hardest part of the project. We went through three different models before landing on something that worked end-to-end.
LatentSync (ByteDance) was the first model we tried — a 2024 diffusion-based model that promised much higher quality. The dependency stack was brutal: transformers, torch, diffusers, mediapipe, insightface, and onnxruntime-gpu all had conflicting version requirements that took significant time to untangle. After resolving those, LatentSync OOM'd on every GPU tier below an H100. Even with the right hardware, its subprocess invocation required manually setting PYTHONPATH to the repo root because the script uses relative imports that don't resolve correctly from an external caller. While we got LatentSync to work, the lip mask was very corrupted, and the lip movements were barely discernible.
Wav2Lip was the second model we used. The model dates to 2020 and its inference script was written against PyTorch 1.x. On top of that, the checkpoint is hosted on Google Drive, which aggressively rate-limits automated downloads from cloud infrastructure — making cold starts flaky and unreliable. When it did run, the output quality was noticeably blurry and degraded around the mouth region.
MuseTalk (Tencent) was our final solution and the one that actually works. It brought its own set of problems: the mmpose dependency stack (mmengine → mmcv → mmdet → mmpose) must be compiled inside the Docker image at build time using mim install — it can't be deferred to cold start. The model also strictly expects video input at 25fps; feeding it anything else causes an index-out-of-bounds inside the whisper feature extraction step. We had to re-encode every source video with ffmpeg before inference. After handling all of that, MuseTalk produced clean, fast results.
Accomplishments that we're proud of
- A fully serverless pipeline where no step requires a persistent server — every GPU runs only for the seconds it's needed
- Zero-shot voice cloning that actually preserves the original speaker's vocal characteristics across languages, using just a 6-second reference clip extracted automatically from the source video
- Per-step real-time progress tracking delivered via webhooks from the Modal orchestrator to the FastAPI backend to the React frontend
What we learned
- How diffusion-based and GAN-based lip-sync models differ architecturally — and why diffusion models need significantly more GPU memory
- How to chain independent ML workloads using Modal Volumes as the handoff mechanism between containers that never communicate directly
- The full dependency management story for Python ML projects: version conflicts between
torch,transformers, and model-specific libraries are the rule, not the exception
What's next for ReDub
- Voice presets — fine-tune XTTS on a longer reference clip so the cloned voice is even more accurate
- Subtitle export — download the translated transcript as SRT or VTT alongside the video
- More languages — expand the ISO 639-1 mapping in the orchestrator beyond the current set
Built With
- cloudflare
- coqui-xtts
- fastapi
- jwt
- llama
- modal
- musetalk
- react
- whisper


Log in or sign up for Devpost to join the conversation.