-
-

Dashboard - upload interface and analysis launcher
-
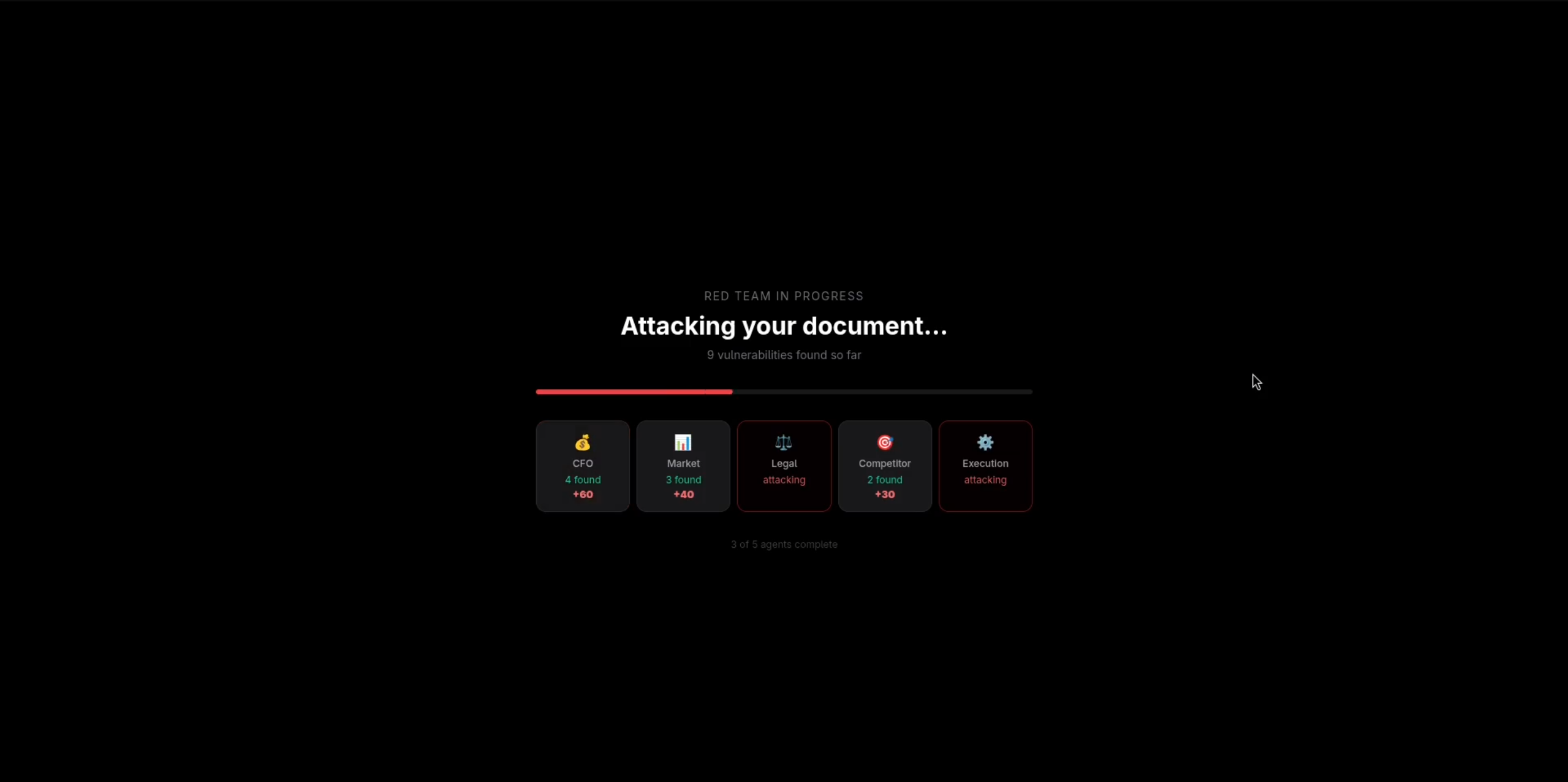
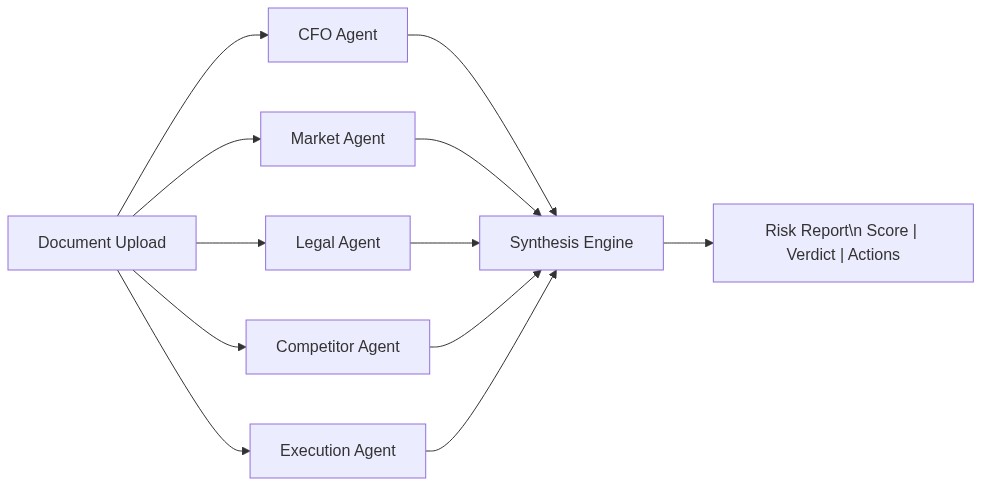
Analysis in progress - five agents attacking in parallel with real-time status
-
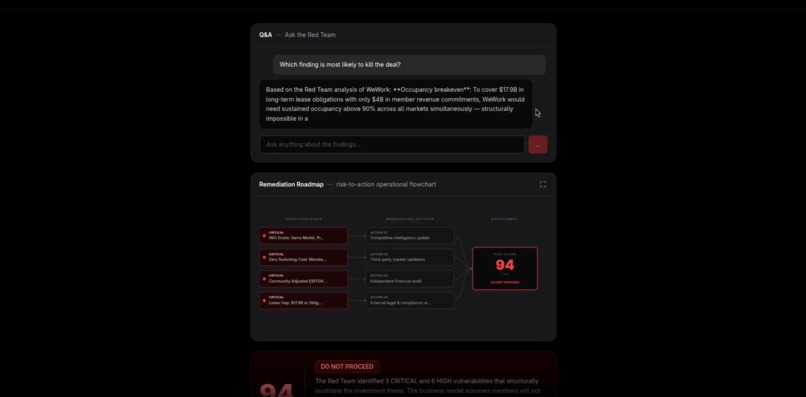
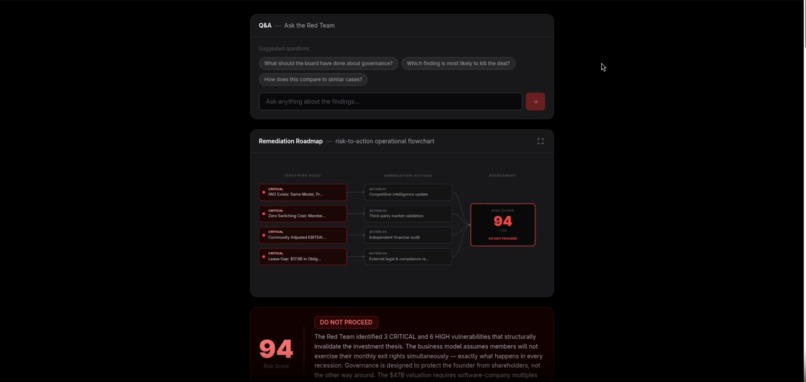
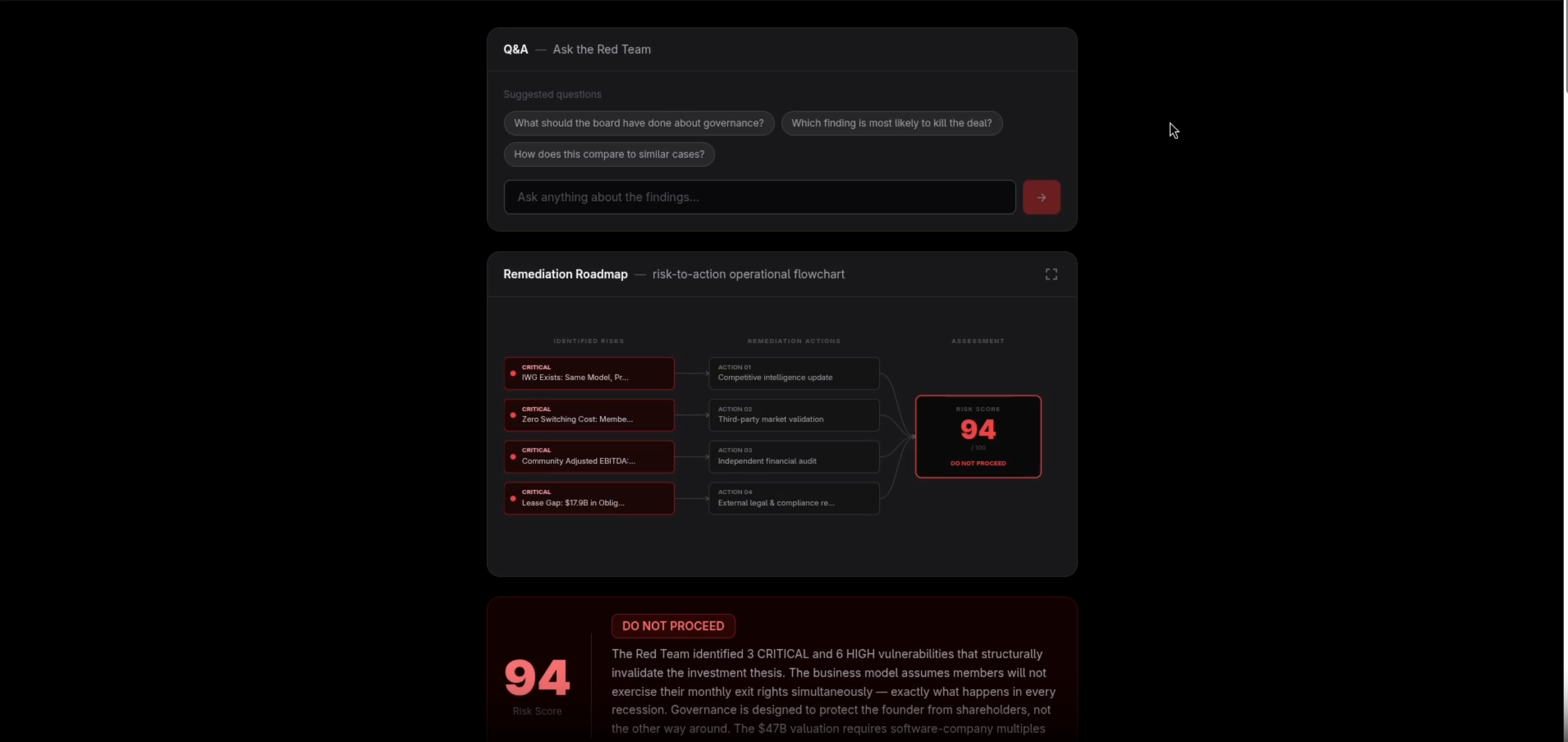
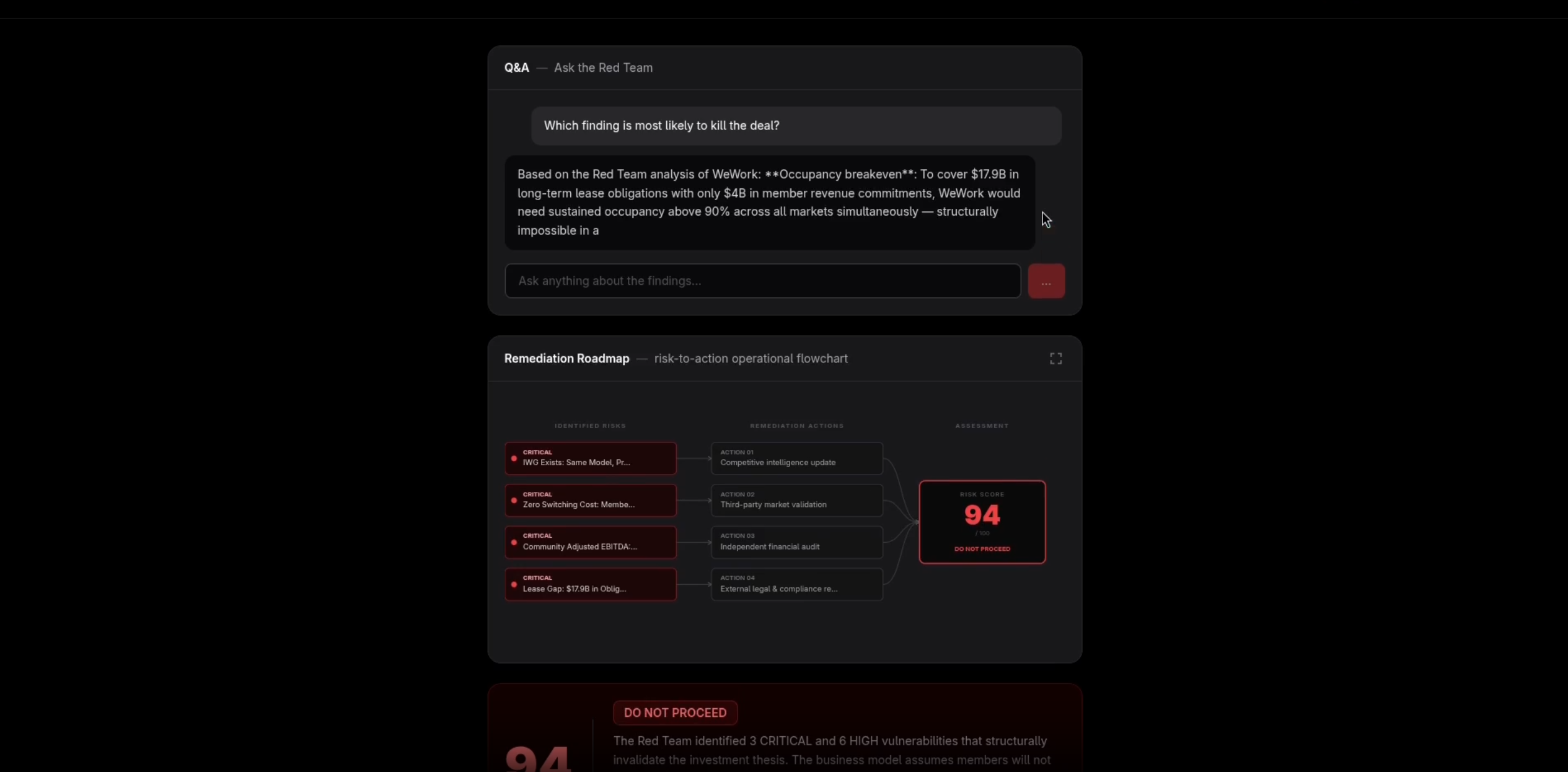
Final report - risk score, verdict, vulnerability breakdown, and remediation roadmap
-

An AI system that attacks your strategy before the market does.

Inspiration
WeWork filed its S-1 in 2019 with a $47 billion valuation. Six weeks later, the IPO was dead. The red flags were all in the document — net losses exceeding revenue, a founder selling his own trademark back to the company, governance that made him unremovable.
Nobody inside the room was paid to say no. Boards, investors, and strategy teams are surrounded by people who want the deal to close. Advisors get paid when it proceeds. The incentives are wrong. Human red teams cost $10k–$50k+ and take days to assemble — and they still soften their criticism because of political friction.
We built RedTeam AI because the most expensive mistakes in business are the ones nobody is paid to find.
What it does
The Five Attackers
Each agent is a specialized LLM instance with a single-minded mandate to find what's broken:
| Agent | Role | Attack Angle |
|---|---|---|
| CFO | The most cynical financial mind in the room | Why the numbers don't add up |
| Market | Your most skeptical future customer | Why nobody will actually buy this |
| Legal | The lawyer looking for conflicts of interest | Who really controls this, and who gets hurt |
| Competitor | The CEO of your main rival | How they will beat you, and why your moat is sand |
| Execution | The COO who's seen plans like this fail | Why this organization will never actually pull it off |
How we built it
Technologies Used
| Category | Technology | Why This Choice |
|---|---|---|
| Core Framework | Python 3.13 + FastAPI | Async-native, high-performance API layer with native SSE streaming support |
| AI Models | Gemini 2.0 Flash (reasoning + synthesis) | Fast inference for parallel agent execution; strong structured output for JSON report generation |
| Agent Orchestration | Google ADK (Agent Development Kit) | Native ParallelAgent and SequentialAgent primitives for multi-agent coordination without custom orchestration code |
| Document Processing | PyMuPDF + semantic chunking (512-token windows, 64-token overlap) | Production-grade PDF extraction with domain-aware chunk tagging across financial, legal, market, competitive, and operational categories |
| Vector Search | Vertex AI Vector Search + text-embedding-004 |
Dual-index architecture (decision layer + internal context layer) with graceful fallback to in-memory keyword search |
| Data Persistence | Google Cloud Firestore | Session-level result persistence for audit trails and historical comparison |
| Frontend | React 18 + TypeScript + TailwindCSS | Type-safe component architecture with real-time SSE consumption and responsive dark-mode UI |
| Infrastructure | Google Cloud Run | Serverless container deployment with independent scaling for backend and frontend services |
Target Users
| Persona | Goal | Pain Point | How RedTeam AI Helps |
|---|---|---|---|
| Boards & Audit Committees | Make informed go/no-go decisions on major strategic moves | Surrounded by advocates; lack an independent adversarial voice | Provides a structured, politically independent risk assessment before every major vote |
| Investors & VCs | Conduct rigorous due diligence before committing capital | Time-constrained, reviewing dozens of decks; easy to miss red flags in optimistic presentations | Surfaces the vulnerabilities the pitch deck is designed to obscure — in 90 seconds per document |
| Corporate Strategy Teams | Stress-test plans before they go to the C-suite | Internal reviewers avoid criticizing colleagues' work; groupthink compounds | Delivers adversarial feedback with zero social friction — the AI has no career to protect |
| Founders | Find blind spots before a skeptical investor does | Too close to the plan to see its weaknesses; advisors are often cheerleaders | Acts as the most skeptical reader in the room — the one who finds the cracks before due diligence does |
Challenges we ran into
1. Parallel Agent Synchronization Running 5 LLM calls simultaneously sounds simple until you need them to return in a predictable window, handle rate limits, and fail gracefully. We built a custom async orchestrator with timeout handling and fallback degradation — if one agent stalls, the other four still deliver a partial report.
2. Eliminating Generic Hallucinations Early versions produced vague criticism like "the financials look risky." We fixed this by forcing each agent to cite specific excerpts from the source document and ground every claim in evidence. This required strict prompt engineering and JSON-schema enforcement.
3. Calibrating a Universal Risk Score A 0-100 score is meaningless if it's inconsistent across document types. We iterated on the synthesis algorithm for hours, testing against real S-1 filings, YC pitch decks, and M&A memos to ensure the score maps to actual decision-making thresholds.
4. Speed vs. Depth Human red teams take days. We had to deliver in 90 seconds. We optimized by parallelizing everything - document parsing, agent inference, and synthesis all run concurrently. The final pipeline averages 72 seconds for a 50-page document.
Accomplishments that we're proud of
- Sub-90-second analysis of complex strategic documents — from upload to verdict
- 5-agent parallel architecture with zero single points of failure
- Document-grounded adversarial reasoning — every criticism cites specific source text
- Calibrated risk scoring that produces consistent, actionable verdicts across document types
- Zero political friction — an AI system with no incentive to soften its findings
- Real-world validation — the WeWork S-1 demo surfaces every documented failure reason in 72 seconds
What we learned
Adversarial AI is not just a feature — it's a product category. Most AI tools are designed to be helpful assistants. We learned that building an AI explicitly designed to find failure requires fundamentally different prompt architecture, safety guardrails, and output calibration.
We also learned that decision-makers don't want more data — they want unambiguous direction. The most valuable part of our system isn't the 50 findings — it's the single verdict at the bottom that forces a decision.
Finally, we learned that multi-agent systems beat monolithic models for complex analytical tasks. One generalist LLM gives balanced, hedged answers. Five specialists with conflicting mandates produce sharper, more complete intelligence.
What's next for RedTeam AI - Adversarial Decision Intelligence
Immediate:
- ESG & Regulatory Agent — sixth attacker focused on compliance and sustainability risks
- Batch Comparison Mode — upload two competing strategies and see which one bleeds more
- Confidence Calibration — show which findings the agents are most/least certain about
Short-term:
- Enterprise SSO & Audit Logging — for boardroom and compliance use cases
- Real-time Collaborative Red Teaming — multiple human analysts working alongside the AI agents
- API-First Platform — integrate into due diligence workflows at VC firms and consultancies
Long-term: RedTeam AI is the first product in a new category: Adversarial Decision Intelligence. Every major strategic decision that costs millions or billions should be attacked by an AI before it reaches a board vote. We are building that infrastructure.

Log in or sign up for Devpost to join the conversation.