-

-
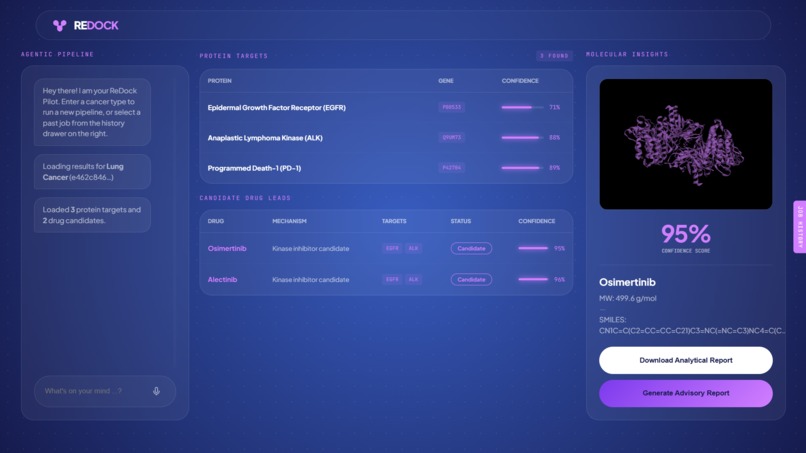
ReDock application page
-
Redock Landing Page

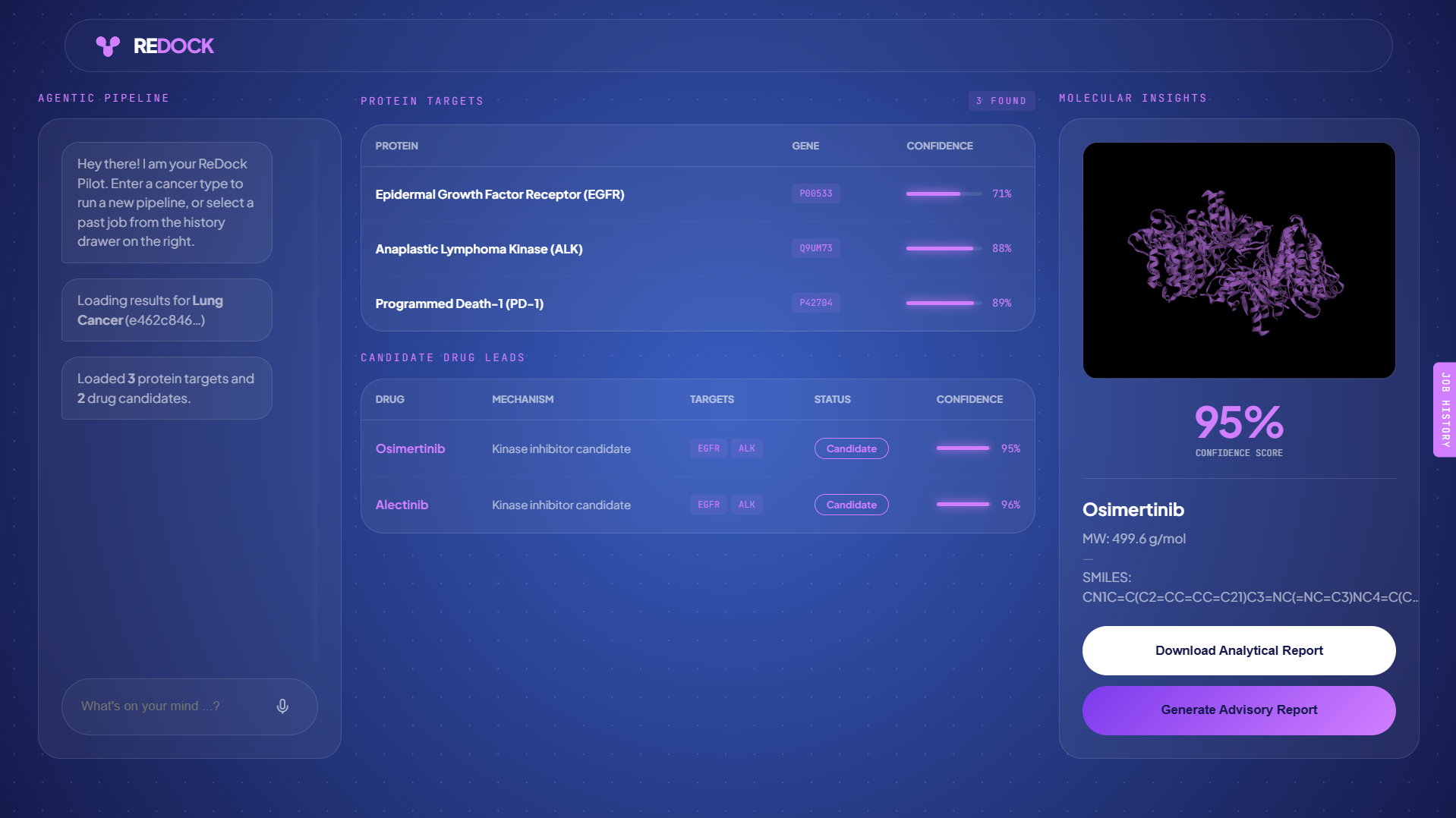
ReDock — Devpost Submission
Inspiration
Small biotech and academic research teams are priced out of computational drug discovery. The tools exist — molecular docking, literature synthesis, AI-driven target identification — but they require expensive infrastructure, specialist engineering teams, and months of manual work to operationalize. A lab with a breakthrough hypothesis shouldn't need a $2M compute budget to test it.
We built ReDock to close that gap. Our goal was simple: take a process that takes months and costs hundreds of thousands of dollars, and reduce it to a single text input that returns actionable results in minutes.
What It Does
ReDock is a multi-agent AI system for autonomous cancer drug discovery. A researcher types a cancer type — lung cancer, glioblastoma, pancreatic cancer — and ReDock's 8-agent network runs the full computational pipeline end to end.
8 Autonomous Agents. One Command.
Science Pipeline — runs sequentially, each agent feeding the next:
- Research Agent — Gemini 2.5 Flash crawls scientific literature to identify key protein targets and current approved treatments
- Retrieval Agent — pulls 3D protein structures from RCSB PDB and drug candidates from PubChem
- Docking Agent — submits every protein-drug pair to NVIDIA DiffDock NIM and scores binding affinity across multiple poses
Review Panel — runs in parallel, then converges:
- Risk Officer — flags toxicity concerns, off-target effects, and safety risks
- Devil's Advocate — challenges the findings, surfaces methodological weaknesses
- Angel's Advocate — champions the strongest candidates, rebuts criticism
- Strategist — assesses commercial feasibility, development timeline, and funding outlook
- Chairman — synthesises all four reviews into a final verdict with recommended next steps
No human in the loop. The output is two downloadable PDFs: a Docking Results Report with molecular data and confidence scores, and an Advisory Report with the full review board deliberation and verdict.
Built on fetch.ai uAgents, deployed on Agentverse, and discoverable via ASI:One. Send the Gateway agent a cancer type from anywhere in the world and the full pipeline runs autonomously.
How We Built It
Backend — Python 3.12 and Flask with async SQLAlchemy and SQLite. The pipeline runs in background threads with their own asyncio event loops to avoid blocking the web server.
Agent Framework — fetch.ai uAgents 0.24.0. Each agent is a standalone process communicating via typed Pydantic message models. The Orchestrator sequences the science pipeline and fans out to the review panel in parallel using asyncio.gather.
AI — Google Gemini 2.5 Flash powers the Research Agent (literature synthesis), and all five review panel agents (Risk Officer, Devil's Advocate, Angel's Advocate, Strategist, Chairman).
Molecular Docking — NVIDIA DiffDock NIM API. SMILES strings are converted to SDF format via RDKit before submission. DiffDock returns log-likelihood confidence scores and 3D docked pose coordinates for each protein-drug pair.
Data Sources — RCSB PDB for 3D protein crystal structures, PubChem for small molecule SMILES and molecular data.
Frontend — Vanilla HTML, CSS, and JavaScript. No framework, no build step. 3Dmol.js renders interactive 3D protein-ligand visualisations in the browser. Gesture controls via MediaPipe and OpenCV stream hand tracking data to the frontend via Flask-SocketIO, allowing researchers to rotate and zoom molecular structures hands-free.
PDF Generation — fpdf2 generates two structured PDF reports per pipeline run.
Challenges We Ran Into
Async agent coordination — orchestrating 8 agents where each stage depends on the previous one's output, across async message passing, required careful state management. The Orchestrator holds an in-memory state dictionary per job and uses asyncio.create_task to trigger the Chairman only once all four panel responses arrive.
Molecular data formats — NVIDIA DiffDock requires SDF format, not SMILES. Converting SMILES to 3D SDF via RDKit requires geometry embedding and force-field optimisation, which fails silently for certain molecule classes (metal-containing compounds like cisplatin). We added metal atom detection and a fallback path for these cases.
Gemini rate limits — the review panel runs five Gemini calls simultaneously on the free tier. We added asyncio.sleep delays between orchestrator phases and implemented tenacity retry logic with exponential backoff for rate limit errors.
DiffDock inference time — each docking job takes 5-10 minutes. We used a semaphore to limit concurrent API requests to 2 and ran all protein-drug pairs with asyncio.gather to parallelise where possible.
SQLite + async Flask — SQLAlchemy async ORM doesn't play nicely with Flask's threading model. We solved this by using direct sqlite3 connections in synchronous Flask routes and reserving the async ORM for pipeline background tasks.
Accomplishments We're Proud Of
We built a pipeline where the output of one AI model becomes the structured input of the next — from Gemini literature synthesis to RCSB PDB retrieval to NVIDIA DiffDock simulation to a five-agent Gemini review board — with no manual steps in between.
The adversarial review panel structure is something we're particularly proud of. Having the Devil's Advocate and Angel's Advocate argue opposing positions — with the Chairman synthesising both — produces genuinely more rigorous scientific assessments than a single model prompt ever could.
The gesture-controlled 3D molecular viewer is a demo moment. Researchers can rotate and zoom protein-ligand docking poses hands-free, seeing exactly how a drug candidate sits in a protein's binding pocket.
We also built a sustainable business model: covering NVIDIA GPU compute costs through tiered access while keeping the platform affordable for the small teams who need it most.
What We Learned
We learned to design systems where AI models talk to each other — not just to humans. The message schema design in messages.py was critical: strongly-typed Pydantic models enforced clean interfaces between agents and made debugging significantly easier.
We gained a working understanding of computational biology concepts: protein binding pockets, molecular docking confidence scores, SMILES notation, PDB file formats, and why DiffDock's diffusion-based approach outperforms traditional grid docking for flexible ligands.
We learned the fetch.ai uAgents framework from scratch — agent addressing, mailbox configuration, Bureau orchestration, and Agentverse deployment.
What's Next
- More molecular databases — ChEMBL, DrugBank, UniProt direct integration
- Multi-round debate — a full two-round Devil vs Angel debate before the Chairman rules
- Wet lab integration — direct export to lab automation platforms
- Expanded cancer coverage — pre-seeded protein target libraries for the 20 most common cancers
- ASI:One discovery — making ReDock findable and usable by any researcher on the ASI network without needing to run any local infrastructure




Log in or sign up for Devpost to join the conversation.