-
-
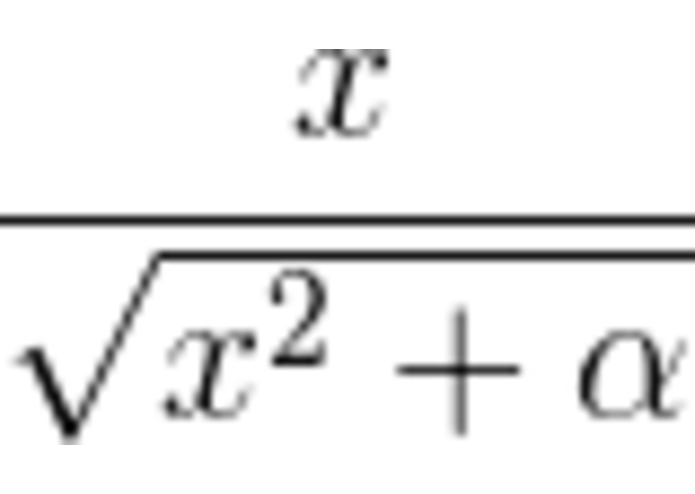
normalization function
-
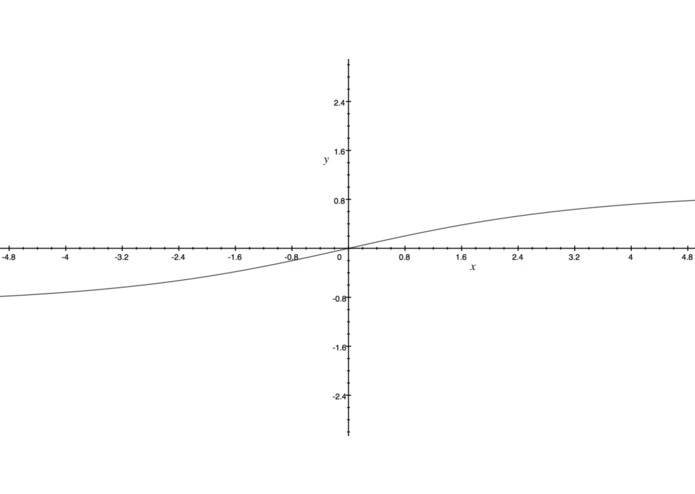
normalization graph
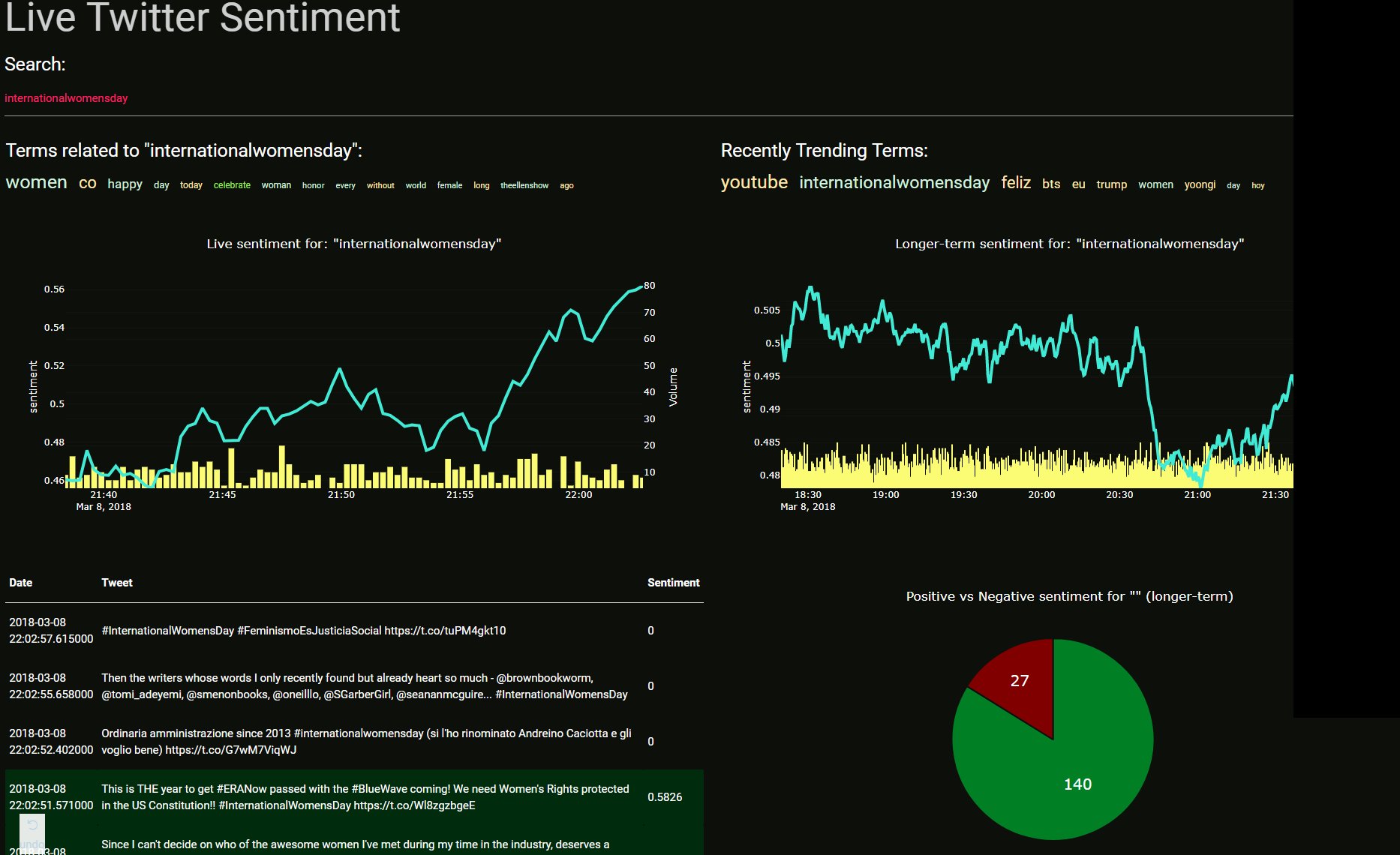
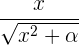
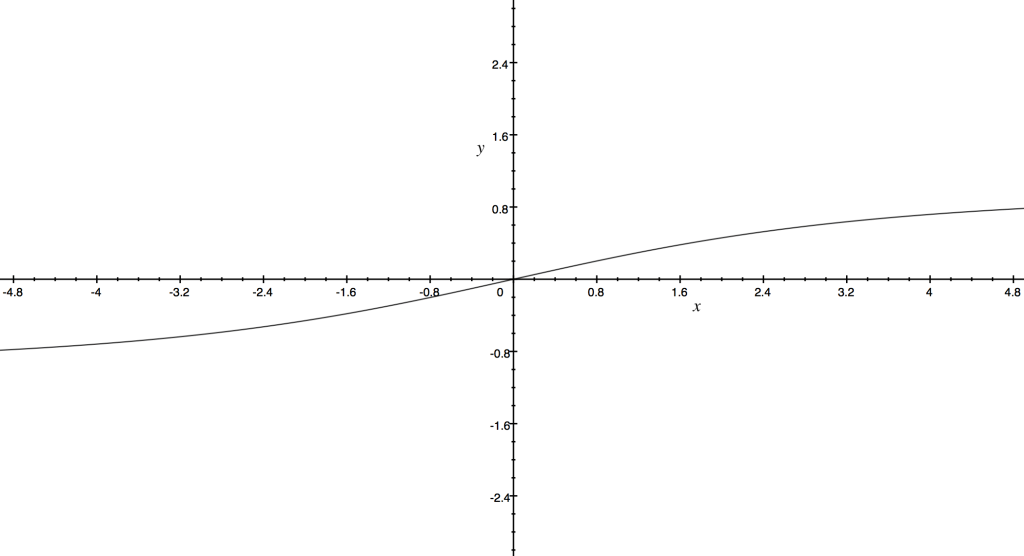
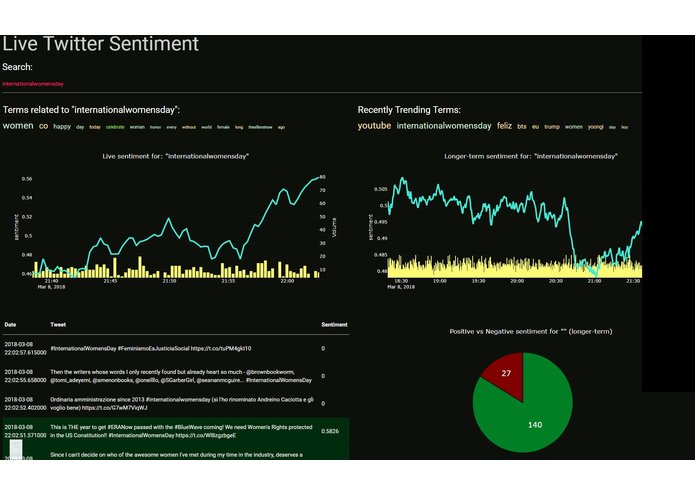
This project is a way to readily visualize sentiment over long periods of time in a usable manner, in this case, with twitter. This could be useful for trying to gauge public reception to a topic, or how the populace feels about something.
What its made with: tweepy: python library for accessing the Twitter API python 3; VADER Sentiment Analysis Framework: to analyze the sentiment of the database Dash: Graph visualization and frontend., Ploty for the graphs
How VADER works: First, we must understand how the sentiment of a single word is found, then we can move on to the sentence; Emotion intensity or sentiment score is measured on a scale from -4 to +4, where -4 is the most negative and +4 is the most positive. The midpoint 0 represents a neutral sentiment. Sample entries in the dictionary are “horrible” and “okay,” which get mapped to -2.5 and 0.9, respectively. In addition, the emoticons “/-:” and “0:-3” get mapped to -1.3 and 1.5. The next question is, how do we construct this dictionary?By using human raters from Amazon Mechanical Turk! Once we have the sentiment of a word, we can construct the sentiment of a whole sentence: VADER sentiment analysis (well, in the Python implementation anyway) returns a sentiment score in the range -1 to 1, from most negative to most positive. The sentiment score of a sentence is calculated by summing up the sentiment scores of each VADER-dictionary-listed word in the sentence. Now here you may notice a contradiction: individual words have a sentiment score between -4 to 4, but the returned sentiment score of a sentence is between -1 to 1. They’re both true. The sentiment score of a sentence is the sum of the sentiment score of each sentiment-bearing word. However, we apply a normalization to the total to map it to a value between -1 to 1. The normalization used is shown above under 'normalization function'. In that equation, x is the sum of the sentiment scores of the constituent words of the sentence and alpha is a normalization parameter that we set to 15. The normalization is also shown graphed above under 'normalization graph'.
We see here that as x grows larger, it gets more and more close to -1 or 1. To similar effect, if there are a lot of words in the document you’re applying VADER sentiment analysis to, you get a score close to -1 or 1. Thus, VADER sentiment analysis works best on short documents, like tweets and sentences, not on large documents.
General Information and Usage
This app is a web app designed to show live and long-term sentiment graphs with Dash of twitter feeds using the tweepy api.
Repo Contents:
dash_mess.py- front-end. Runs on local or external servertwitter_stream.py- streams from twitter, creates database, runs in background.config.py- Words not in "trending"cache.py- For caching purposes in effort to get things to run faster.db-truncate.py- A script to truncate the infinitely-growing sqlite database. You will get about 3.5 millionish tweets per day, depending on how fast you can process. You can keep these, but, as the database grows, search times will dramatically suffer.
Quick start
- Clone repo
- install
requirements.txtusingpip install -r requirements.txt - Fill in your Twitter App credentials to
twitter_stream.py. - Run
twitter_stream.pyto build database - If you're using this locally, you can run the application with the
dev_server.pyscript. - You might need the latest version of sqlite.
sudo add-apt-repository ppa:jonathonf/backports sudo apt-get update && sudo apt-get install sqlite3 - Consider running the
db-truncate.pyfrom time to time (or via a cronjob), to keep the database reasonably sized. In its current state, the database really doesn't need to store more than 2-3 days of data most likely.
NOTE: This is deployed at socialsentiment.net



Log in or sign up for Devpost to join the conversation.