-
-
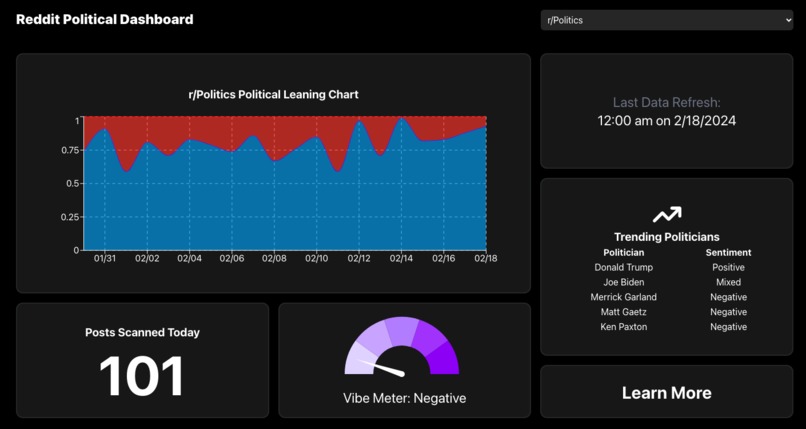
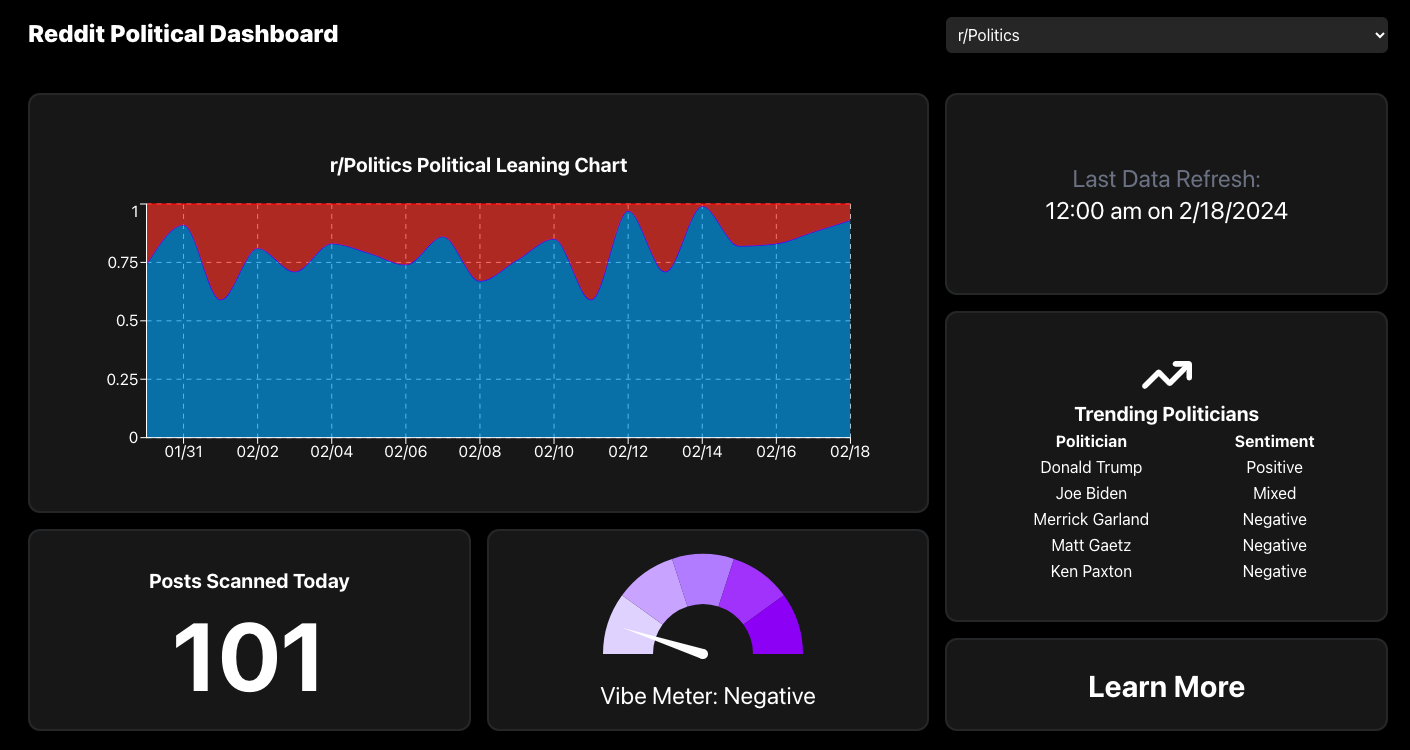
Our Current Website
-
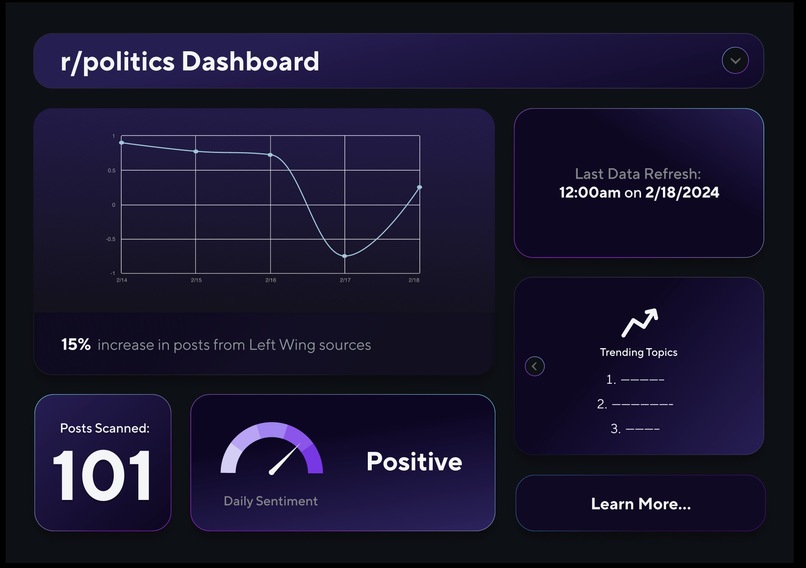
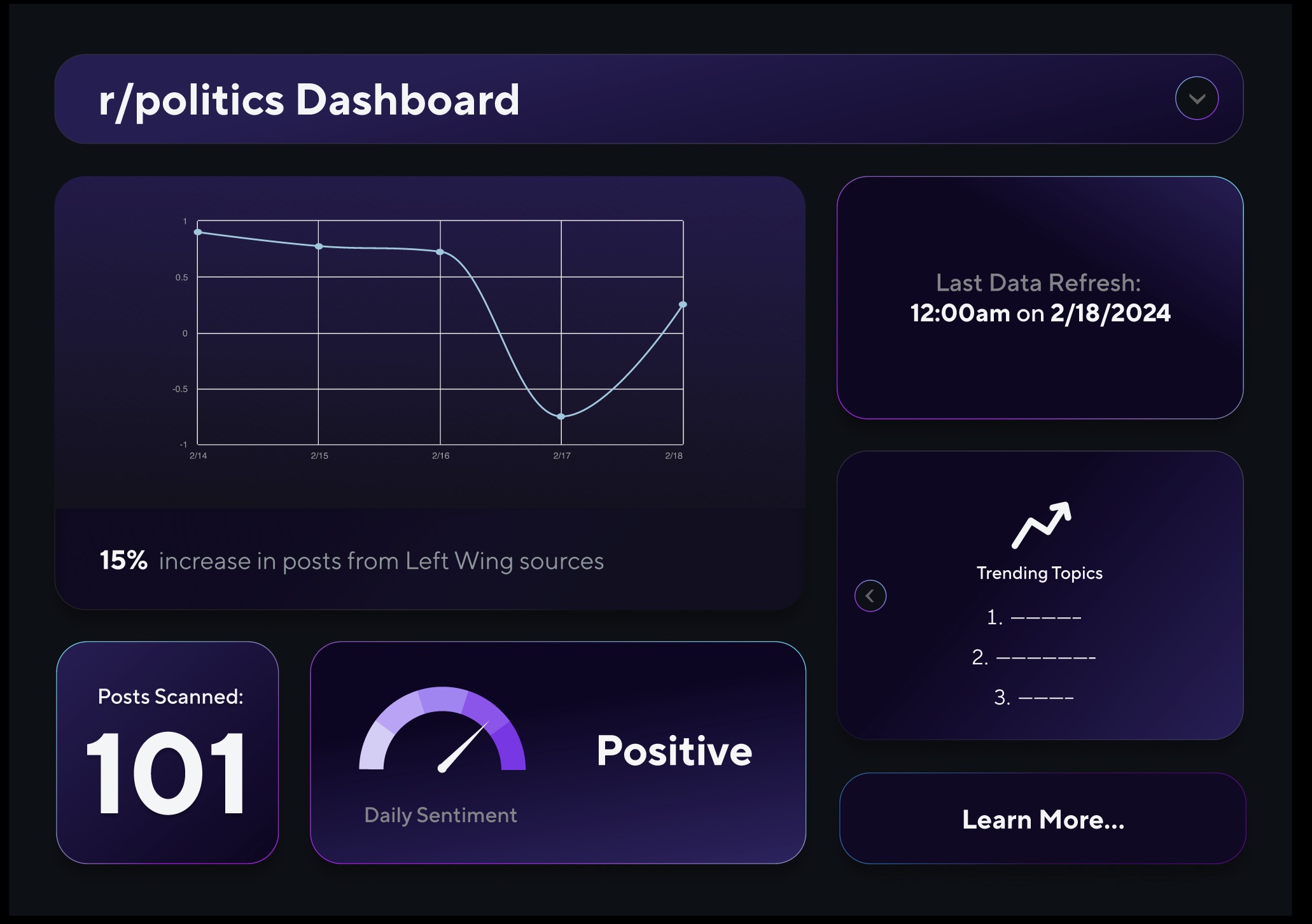
Figma Design for Website
Inspiration
As our access to news becomes increasingly reliant on algorithms designed to hold our attention, consumers become enthralled in what is known as “epistemic bubbles”, more commonly nicknamed “pipelines”, where users will only come across information that panders to them. The division between those on either side of the political compass is growing with each passing day, and often people are unaware of how much their/others’ ideologies are being spoken about.
What it does
Automatically gathers the titles for all news articles posted on a given day on several Reddit boards. Using the OpenAI API ML model gauges the level at which a post is associated with a political party, as well as the general sentiment to the idea. Displays this data to a dashboard including trends over time, graphs indicating the levels certain boards are saturated with certain ideas, and frequently occurring topics and figures. Collects and analyzes this data every 24 hours.
How we built it
Divided into 3 teams, for UI/UX, data scraping, and ML, we set out to accomplish the main tasks of gathering, analyzing, and displaying data. On the data scraping side, a Python script using Selenium is run to gather all titles of posts in the past 24 hours. We employ two different ML models with their own pros and cons. We use OpenAI to identify user sentiments in a particular community and create a “vibe meter” from positive to negative, using this value. Additionally, we used OpenAI to identify trending names in articles. Our other model, which we trained for this project, identifies whether a piece of text leans conservative or liberal, corresponding to a 1 or 0 value which we use to create an average political lean for a given day. Lastly, our web development team designed and implemented an interface that displays these as graphs and allows users to hover over and enlarge graphs for more info. Additionally, we implemented a menu to switch between analyzed communities.
Challenges we ran into
The Reddit API was shut down a year ago, making it extra difficult to scrape titles and comments from Reddit. The site also employs some tactics to prevent bots from scraping data, and working around this was difficult. Additionally, training an ML model in a short period of time was very difficult. The OpenAI API is very reluctant to speak on politics and is very slow and limited to user queries. Perhaps the most difficult task was to train an LLM using data that we scraped. Most of the time working on the ML model was focused on adapting the model to train with the data we provide it and gain useful metrics from it. Frontend development went very smoothly, with the only complaint being there was not enough time to implement all the desired smooth animations on the site.
Accomplishments that we're proud of
Adapting an LLM to our data that we scraped was very difficult and very rewarding. For our less experienced members, working around data scraping was a fun challenge, and gave us some insight into real applications for programming. It feels very powerful to have created a cohesive idea and implementation in such a short period of time.
What we learned
For some, this was our first foray into a team coding environment, and we learned the skills to delegate and work together on certain tasks. We also went through all the steps of designing and creating a product from scratch. For smaller victories, this was some people’s first foray into Python. Learning LLMs such as the OpenAI API was very rewarding, especially as this is a very budding field in the tech industry.
What's next for Reddit Politics Sentiment Analysis
We are planning to run the data every day to obtain a large database of daily sentiment and political leaning from Reddit. With this, we can turn our data into real graphs, and not display dummy data on the site. Additionally, the site is designed so we can explore other subreddits for analysis if we so wish.


Log in or sign up for Devpost to join the conversation.