-
-
landing page
-
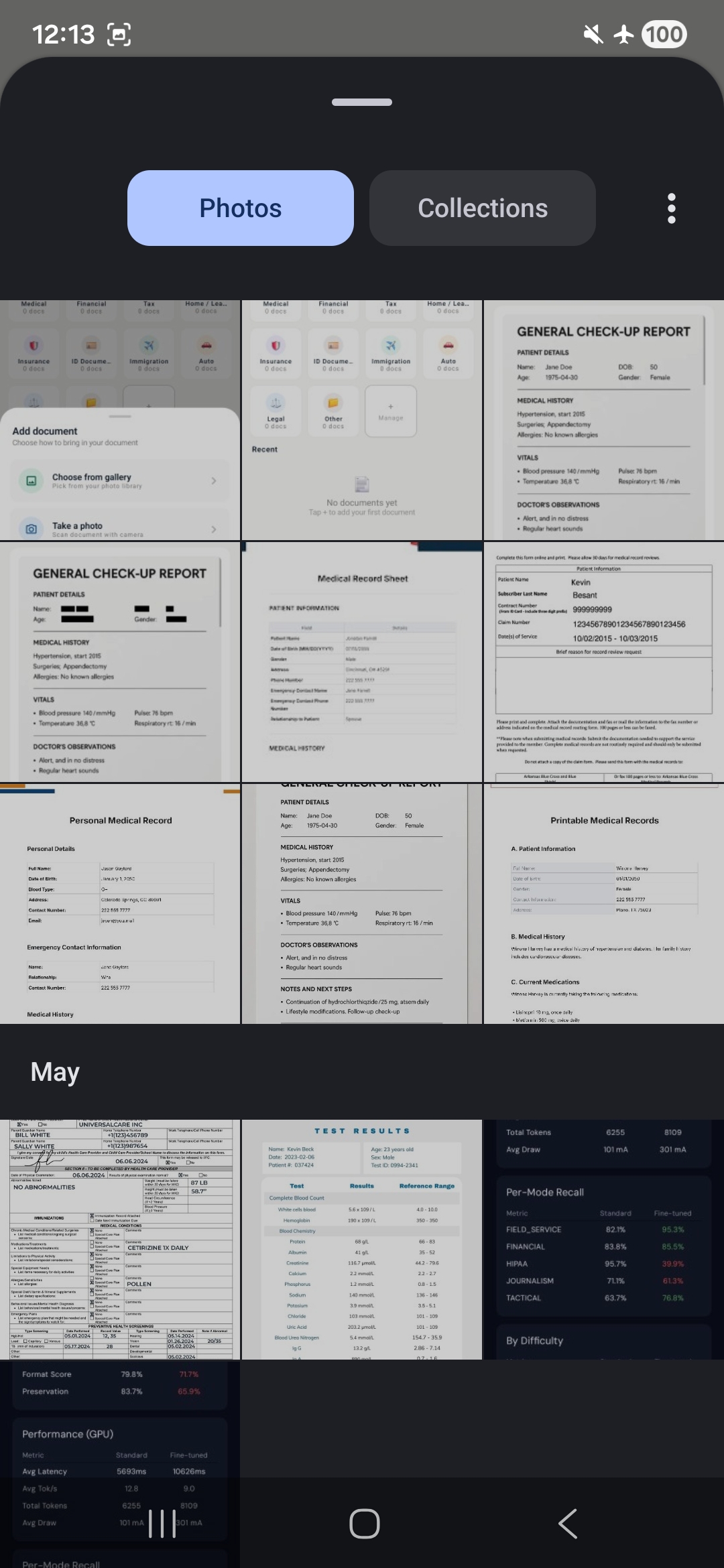
sample doc
-
upload doc
-
-
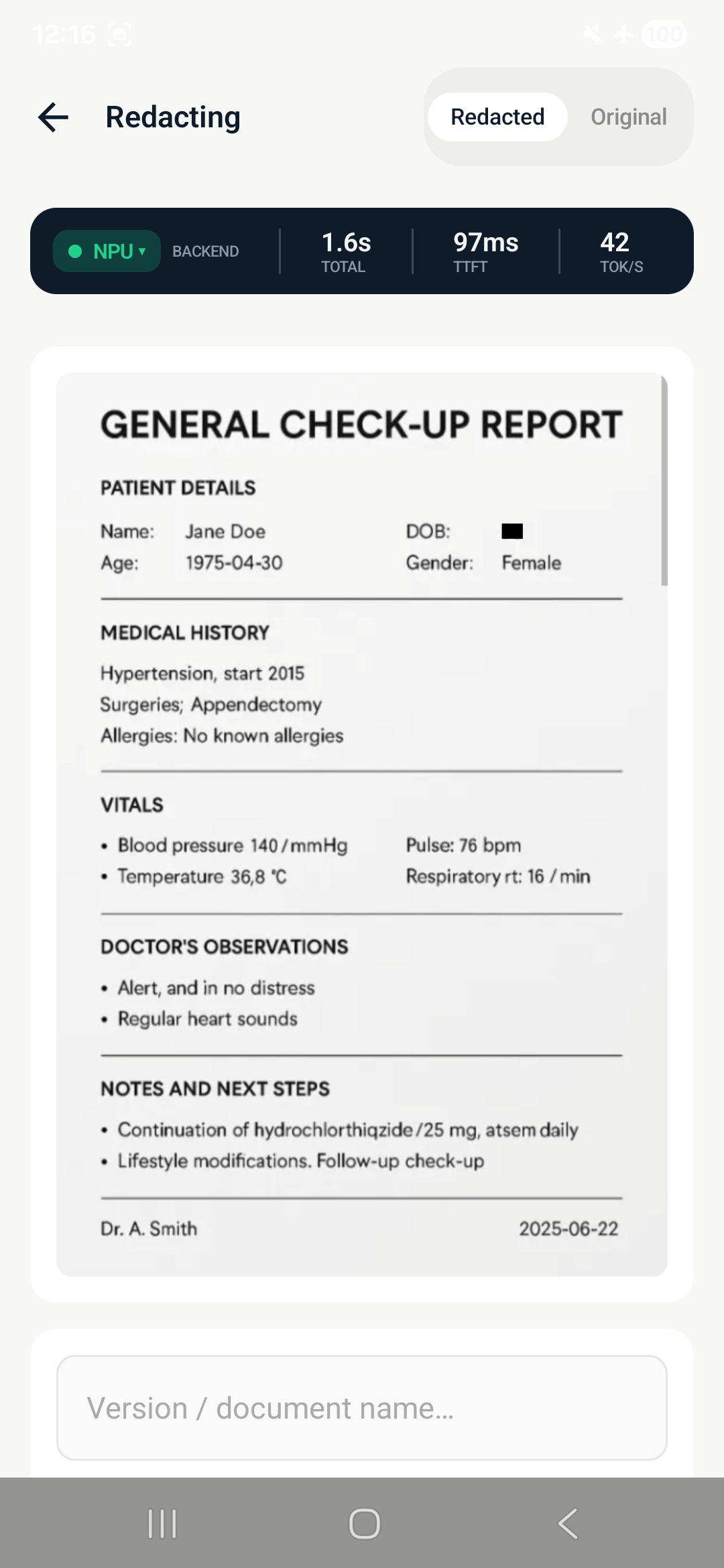
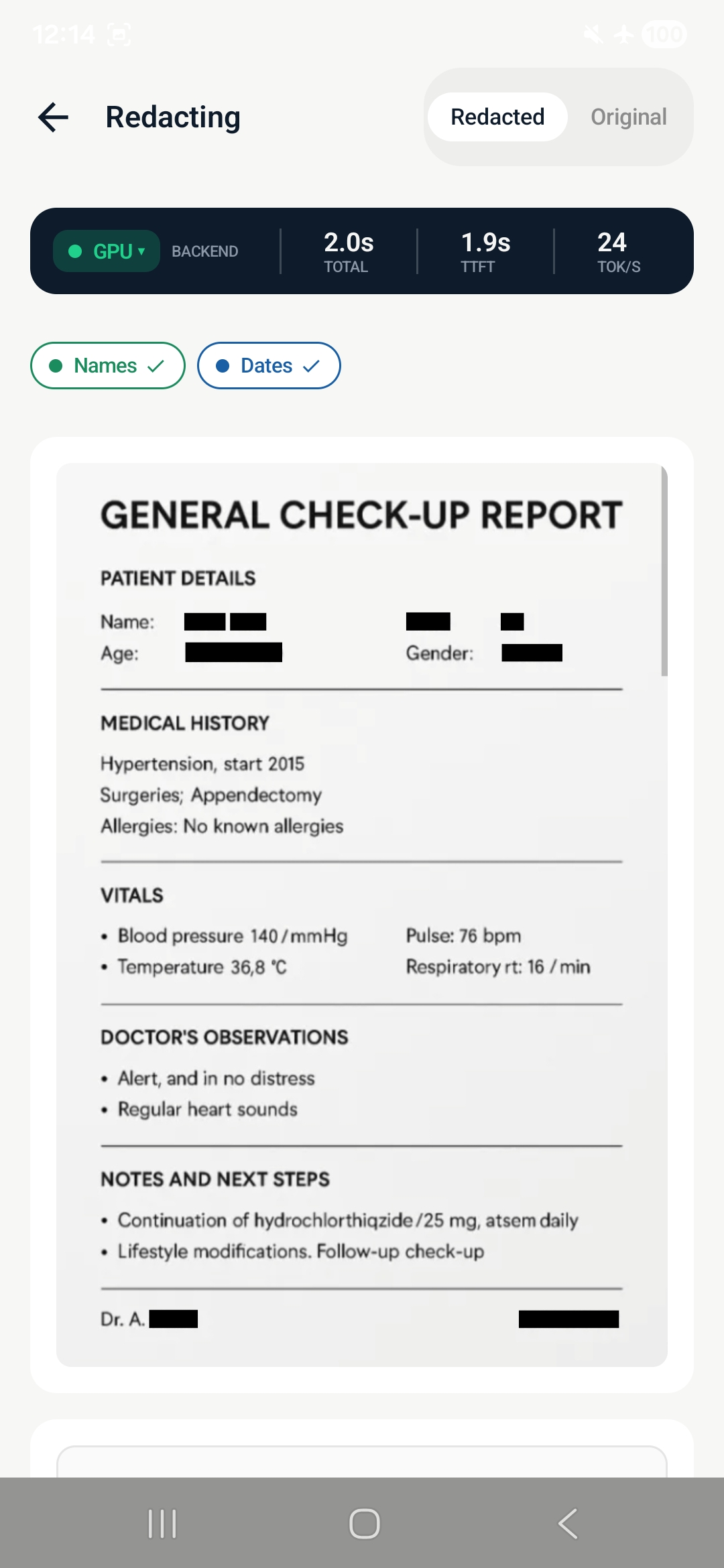
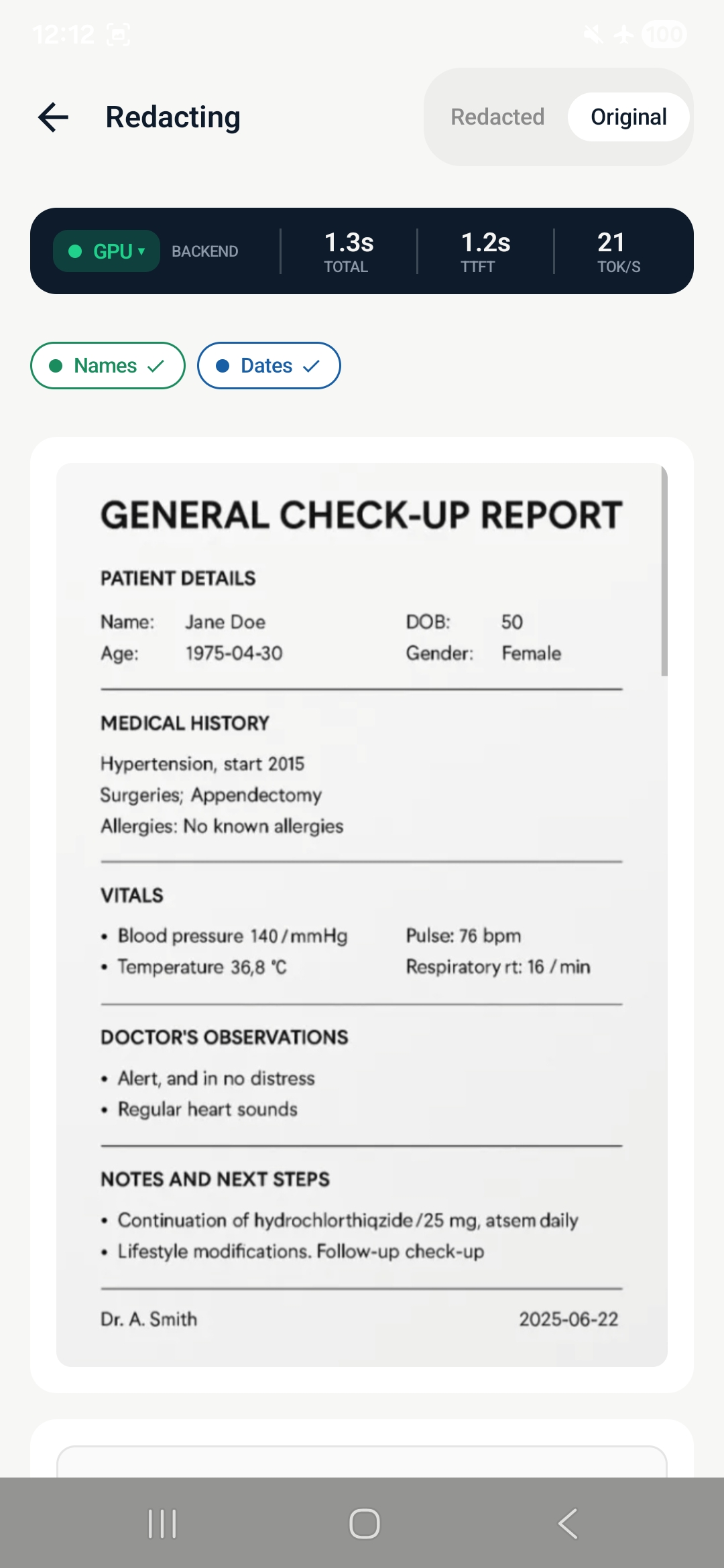
redacted version
-
-
-
text redaction
-

Inspiration
Every day, frontline professionals — nurses copying patient summaries, paralegals sharing case notes, journalists protecting sources — face the same impossible tradeoff: communicate efficiently or protect sensitive data. Existing solutions either require uploading documents to the cloud (breaking privacy) or are too cumbersome for real workflows.
We asked: what if every smartphone could act as an intelligent, zero-trust privacy layer? No cloud. No API keys. No data ever leaving the device. That question became Redacto.
What it does
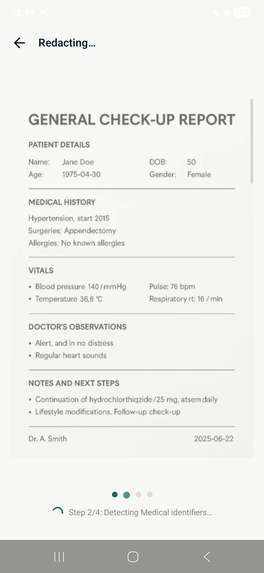
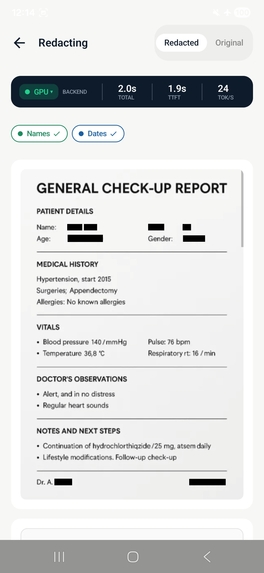
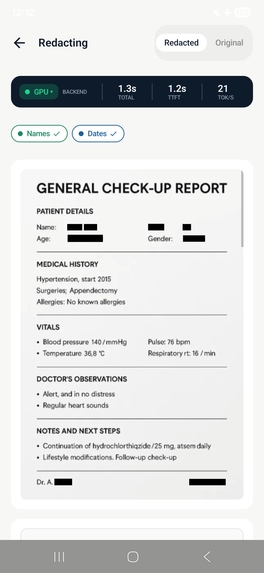
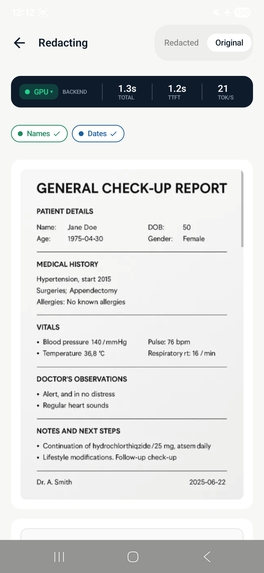
Redacto is a zero-trust privacy document vault for Android. It uses on-device AI to redact PII and PHI from documents, photos, and text — entirely on the Snapdragon 8 Elite NPU, with no internet permission.
Core capabilities:
- Scan documents via camera, gallery, PDF, or typed text
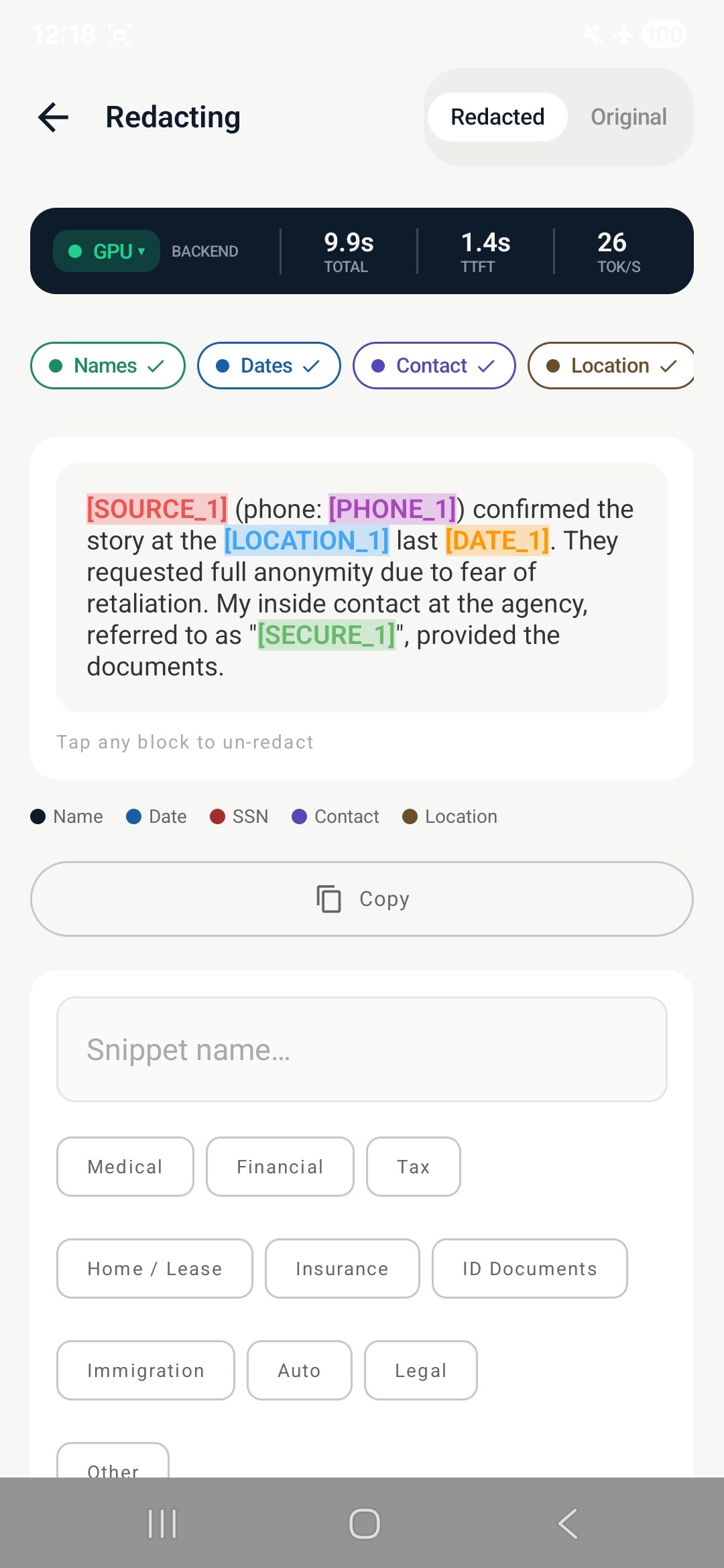
- Redact sensitive fields using a 4-step multi-pass LLM pipeline
- Share any either original or redacted copy safely via the system share sheet
- Organize across categories: Medical, Financial, Legal, Immigration, Auto, Home, ID Documents
The app intentionally has no INTERNET permission. Every byte of inference runs locally on the device.
How we built it
Multi-Pass Redaction Pipeline
The core innovation is a 4-step pipeline powered by Gemma 4 E2B via Google LiteRT-LM on the Qualcomm Hexagon NPU:
Step 1 - Classify: Identify document type and applicable redaction categories
Step 2 - Detect: Find all PII/PHI instances and their locations
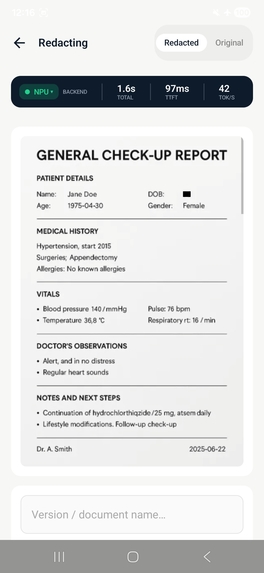
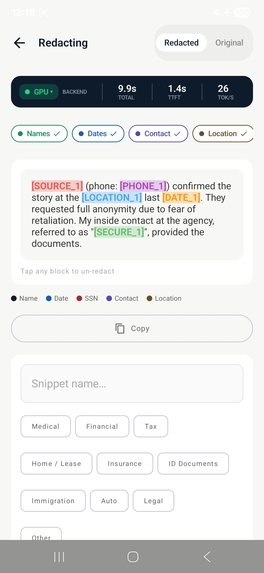
Step 3 - Redact: Replace fields with structured placeholders [NAME_1], [SSN_2]
Step 4 - Validate: Verify no PII leaked; retry loop up to 3 rounds
Each step uses a dedicated prompt with domain-specific few-shot examples across 7 redaction modes: Medical/HIPAA, Financial/Legal, Tactical, Journalism, Field Service, and General.
NPU Acceleration
We target the Snapdragon 8 Elite (SM8750) by using specially built runtime for sm8750 by Qualcomm AI hub team
The NPU model delivers results by utilizing least battery on board making it a smartest choice to run privacy redactor on.
Performance Benchmarking System
We built an ADB-triggered benchmarking pipeline using an 85-entry JSONL dataset with difficulty tiers (easy / medium / hard). Metrics collected per pass: TTFT, decode tok/s, end-to-end latency, peak RSS memory, and token count - summarized by redaction mode and backend (GPU vs NPU).
Stack
| Layer | Technology |
|---|---|
| Language | Kotlin |
| UI | Jetpack Compose + Material 3 |
| On-device LLM | Google LiteRT-LM |
| Model | Gemma 4 E2B (google/gemma-4-E2B-it) |
| NPU | Qualcomm QNN delegate |
| OCR | Google ML Kit Text Recognition v2 |
| Camera | CameraX |
| Storage | Room Database |
| Target device | Samsung Galaxy S25 Ultra |
Challenges we ran into
Backend cascade subtlety - Backend.NPU() construction succeeds even when the Snapdragon dispatch library is absent. The failure only surfaces at Engine.initialize(). This cost us hours before we wrapped the right call in try/catch.
Image over-redaction - Our initial word-diff heuristic flagged reformatted text as leaked PII. We rebuilt it as an indexed-element pipeline: OCR elements are indexed, the LLM returns indices to redact, and boxes are drawn from those indices directly - eliminating false positives entirely.
Validation loop false positives - The validation step flagged our own placeholders ([NAME_1], [SSN_2]) as leaked PII. Fixed with a parser filter and a prompt rewrite that explicitly instructs the model to treat bracketed placeholders as already-redacted.
Memory pressure - The 2.4 GB model plus tensor buffers caused OOM kills without largeHeap=true. Our benchmarking system initially created a second InferenceEngine, doubling memory consumption. Solved by reusing the app's engine via callback.
Camera orientation - ImageProxy.toBitmap() ignores EXIF rotation. Documents photographed in portrait came through rotated 90°. Fixed by reading imageInfo.rotationDegrees and applying a Matrix transform before OCR.
Blocked NPU AoT Compilation - after having fine-tuned quantized model, we ran into issues where currently its not easy and fast to compile a QC NPU ready AoT model
Accomplishments that we're proud of
- A genuinely zero-trust app - no INTERNET permission, no cloud fallback, no telemetry. Every privacy guarantee is enforced at the manifest level.
- 4-step multi-pass pipeline running entirely on a mobile NPU - Classify, Detect, Redact, Validate - with a retry loop and graceful single-pass fallback.
- ~40 tok/s on Snapdragon 8 Elite NPU - real-time redaction of a data heavy document in reasonable time
- Fine-tuned model - we trained a LoRA adapter on 3,000 domain-specific redaction examples on top of
google/gemma-4-E2B-itusing QLoRA via standard HuggingFace + PEFT tooling - Quantized model - we further quantized trained model to 4b_16a using litert-torch (nightly build)
- A real benchmarking system - 85-entry JSONL dataset with difficulty tiers, ADB-triggered, measuring TTFT, decode tok/s, latency, and memory across GPU and NPU backends that allowed us to have a feedback loop to improve the prompts in the skills per category systematically and data grounded
What we learned
- On-device LLMs are production-ready for structured extraction tasks when paired with well-engineered prompts. Gemma 4 E2B handles domain-specific redaction reliably at real-time speeds on consumer hardware.
- Prompt engineering matters more than model size for this use case. The 4-step pipeline dramatically outperformed single-pass redaction on complex, multi-category documents.
- NPU initialization ≠ NPU construction. The backend cascade must be handled at
Engine.initialize(), not at object construction time - a subtle but critical distinction in the LiteRT-LM API. - AOT compilation vs JIT For LM models, JIT is not practically useful and that's where QC AI Hub accelerates app development by providing full hub
- Zero-trust is achievable today. Removing the INTERNET permission entirely forced us to solve every problem locally. It made the app harder to build and more trustworthy to use.
What's next for Redacto
- Fine-tuned NPU ready compiled model - we have the LoRA adaptor fused quantized fine-tuned model (using litert-torch) that needs to be compiled for NOU AOT runtime [P0]
- Confidence scores per redacted field - visible to users, useful for audit trails in regulated industries [P0]
- PDF upload - deferred from v1 for demo stability [P1]
- In-app benchmark UI - spec is written; implementation follows [P2]
- Encrypted local backup - cross-device portability without cloud exposure
iOS port - the zero-trust use case is equally compelling on Apple's Neural Engine
https://youtu.be/mrGvSL8iGjc - Demo video
APK Download - https://drive.google.com/drive/folders/19PtvS9D_X3HcAyKNLHYKWhOjNdiojqev?usp=sharing
https://github.com/EdgeArtist/redacto - Github release (But APK is too big for that, so refer to the drive link for apk)
Built With
- androd-sdk
- colab
- google-litert-lm
- hf
- kotlin
- litert
- litert-lm
- snapdragon-8-elite-npu


Log in or sign up for Devpost to join the conversation.