

Inspiration🌟 Inspiration
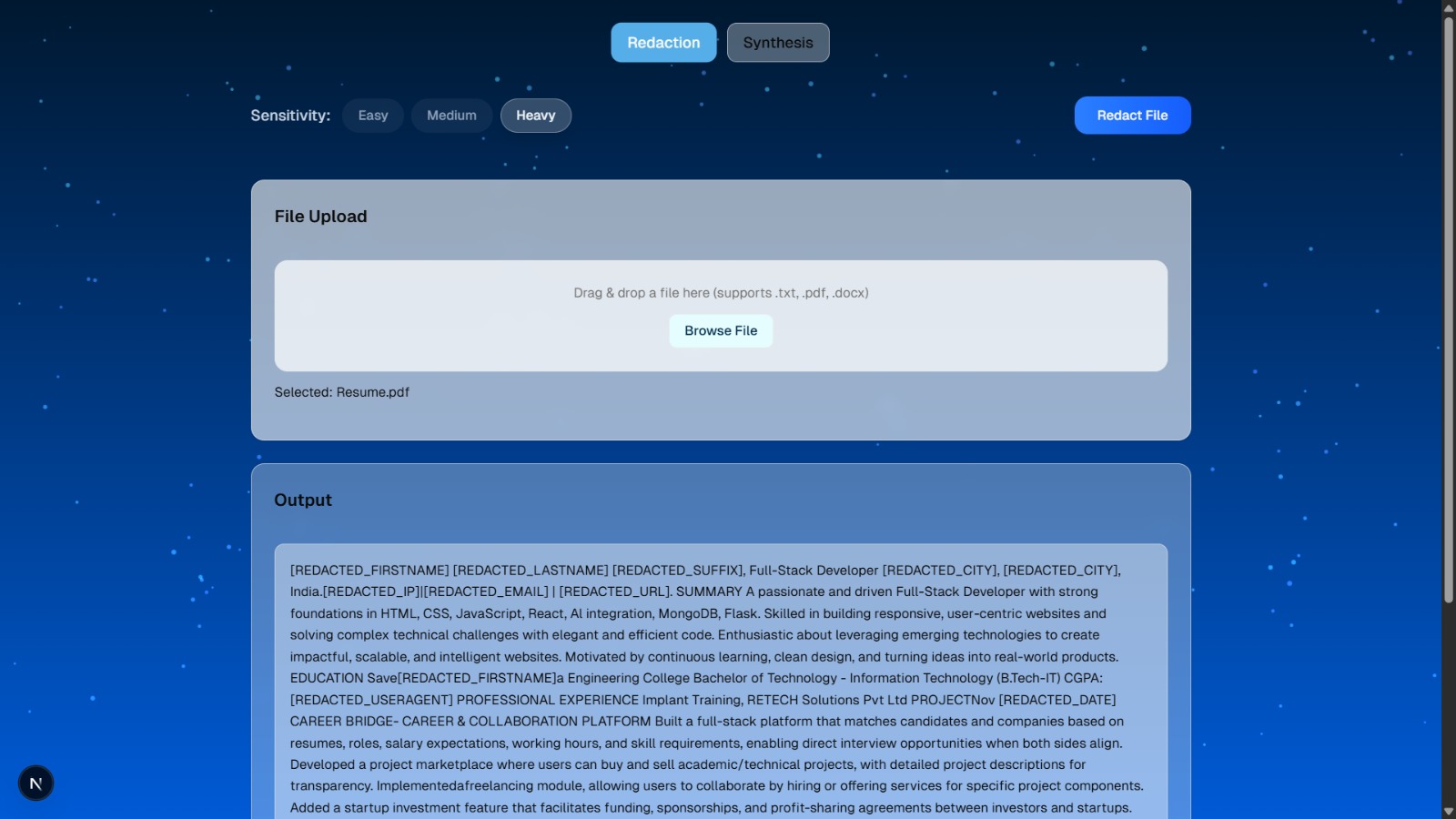
In an era where organizations handle enormous volumes of sensitive data, we noticed that manual redaction remains the default — slow, inconsistent, and risky. A single missed field like a name or ID can lead to privacy breaches and compliance failures. This inspired us to build RedactLess, an AI-powered solution that ensures privacy is automated, accurate, and effortless.
💡 What It Does
RedactLess detects and redacts personally identifiable information (PII) across text files, documents, and datasets using Natural Language Processing and a fine-tuned LLM. It offers three redaction levels — Light, Medium, and Heavy — allowing users to control how much data is masked. It also generates realistic synthetic datasets for safe testing and analysis, preserving usability while protecting privacy.
🛠 How We Built It
We trained and fine-tuned a Hugging Face Transformer model on a labeled PII dataset. The backend was developed with Flask, integrated into a mainframe-compatible architecture, and connected to a responsive web interface for real-time text redaction and synthetic data generation.
🚀 Challenges & Learnings
We faced dependency conflicts, multi-format data handling, and latency optimization during inference. Through this, we learned to deploy transformer-based NLP pipelines efficiently, connect AI to secure backend systems, and maintain performance across environments.
Built With
- api
- flask
- natural-language-processing
- python
- react
- tensorflow
- typecript

Log in or sign up for Devpost to join the conversation.