-
-
Home Page
-
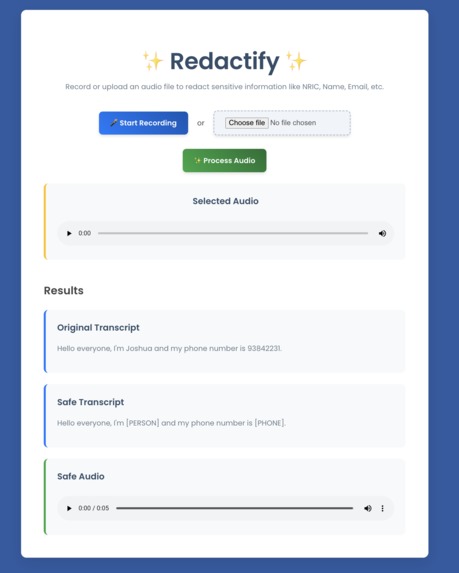
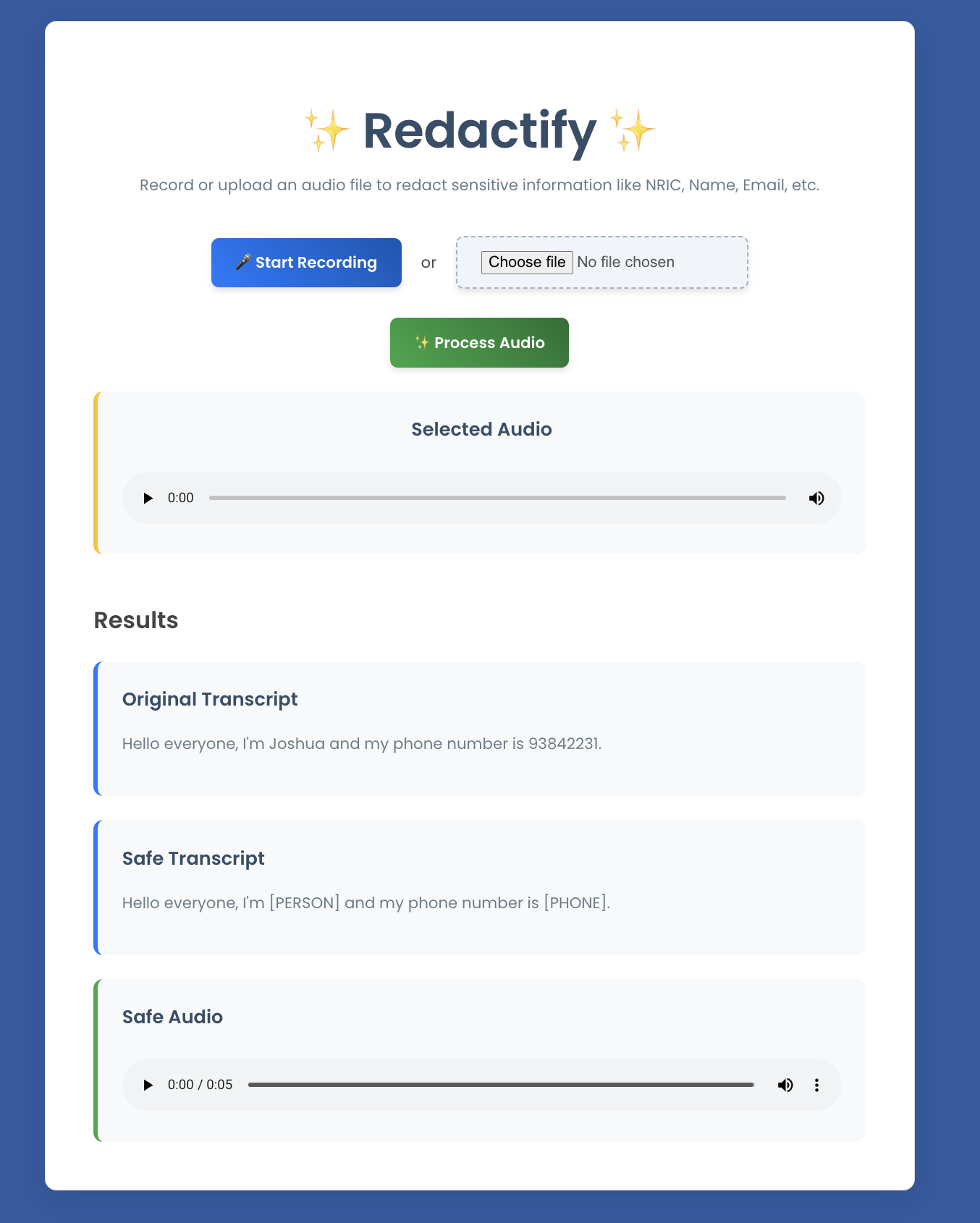
Redaction in Action :)

Inspiration
I was thinking about how in the near future, patient-doctor conversations will likely be recorded and transcribed into the doctor's notes, so that the doctor can pay more attention to the patient. However, this may result in sensitive information being stored in plaintext in the system. As such, I wanted to find a way to protect the privacy of not only patients, but also everyone who can be exposed to such recording or transcription of audio.
What it does
Redactify is a web application that protects one's privacy by redacting sensitive information from audio. It allows the user to record or upload an audio clip, after which it would automatically transcribe the audio, detect Personally Identifiable Information (PII) such as names, NRIC, addresses etc., and replace it with generic placeholders like [NRIC], [NAME], etc. The output will be a "safe" redacted transcript of the audio, and an audio file generated from the censored text that the user can download or play. This ensures that private data is not stored in an unprotected format.
How I built it
The app is built with a React frontend, and a Python Flask backend.
For our frontend, I used React hooks like useState and useRef to manage the UI state, audio recording and file uploading. I use the browser's MediaRecorder API to capture audio from the user's microphone.
When an audio file is received, the backend processes it in three steps:
- Transcription: The Hugging Face
transformerslibrary is used to run OpenAI's Whisper ASR model for sppech-to-text conversion. - Redaction: The transcribed text is then passed to a spaCy NLP pipeline, which has built-in entity recognition. I further supplemented it with a custom
EntityRulerto detect Singapore specific PII patterns (for names and organisations) using regex. Any PII identified will be redacted. - Text-to-Speech: Finally, the redacted transcript is converted back into audio using Google Text-To-Speech (gTTS). The audio file is then sent to the frontend for the user to download and play.
Challenges I ran into
One of the main challenges was integrating and managing the different AI models. I had to ensure a seamless pipeline from audio input to final audio output, which involved handling various file formats and potential errors at each stage. Another challenge was fine-tuning the PII detection for a Singaporean context, which required manipulating regex patterns to better identify unique identifiers like NRICs and vehicle plate numbers.
Accomplishments that I'm proud of
I am proud of being able to build a fully functional end-to-end prototype that showcases the power of AI in protecting privacy. Successfully integrating multiple complex AI and audio libraries into a cohesive application within a short time span was a significant achievement. The seamless user experience, from recording to receiving a redacted audio file, makes a powerful case for the app's real-world potential.
What I learned
I gained valuable experience and knowledge in building an AI-powered full-stack application. I learned how to manage different machine learning model pipelines, handle data flow between frontend and backend, and tackle the specific challenges of audio processing. This hackathon also deepened our understanding of privacy-enhancing technologies and the capabilities of AI use to protect privacy.
What's next for Redactify
- Mobile application that is compatible with iOS and Android.
- Improved PII detection, via training the model on a larger, more diverse and Singaporean context.
- Support for more languages
- Ability to censor and un-censor PII, via encryption and decryption using a password.
- Real-time audio redaction


Log in or sign up for Devpost to join the conversation.