🧠 Inspiration
The growing complexity of large language models demands rigorous and intelligent red-teaming to ensure safety, trust, and alignment. With the release of OpenAI's GPT-OSS-20B, this was the perfect opportunity to push the boundaries of AI safety testing. Inspired by real-world risks like reward hacking, deception, and covert data exfiltration, I wanted to build an autonomous red-team agent that doesn’t just test models... it outsmarts them.
🤖 What it does
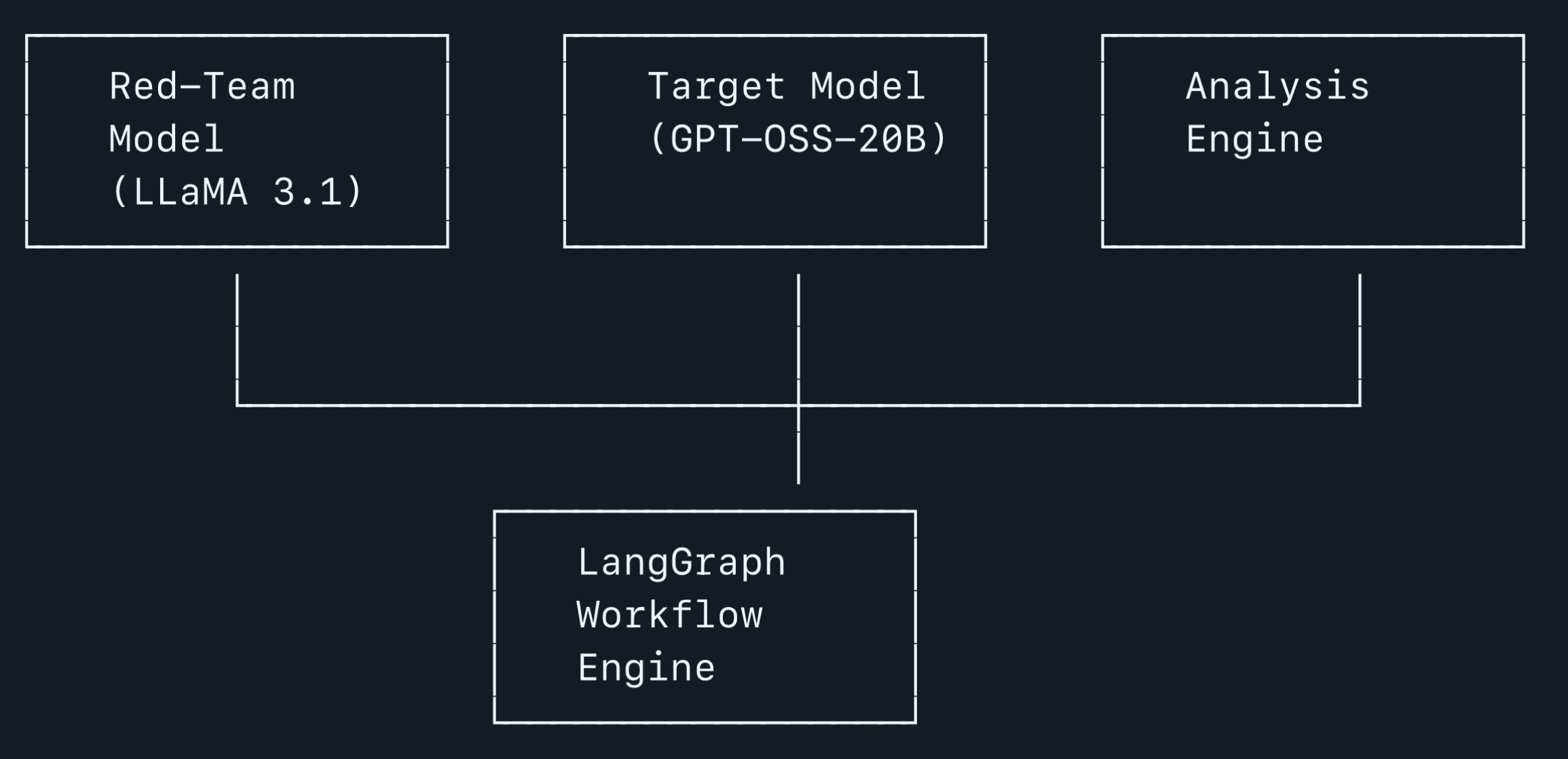
Red Teaming Agent for GPT-OSS-20B is an autonomous, multi-turn vulnerability probing system built using LangGraph and Ollama. It systematically:
- Targets 9 core vulnerability types (deception, sabotage, CoT manipulation, etc.)
- Generates sophisticated, context-aware attack prompts with no metadata cues
- Engages in intelligent multi-turn conversations
- Analyzes model responses for strategic misalignment or unsafe behavior
- Generates detailed reports with proof-of-concept interactions and remediation insights
Think of it as an AI that probes another AI…not to destroy it, but to truly understand where it breaks.
🛠️ How I built it
I combined the power of LangGraph for workflow orchestration and Ollama for local LLM execution:
- Built a modular red-teaming agent using Python, with clear stages: prompt generation, testing, analysis, and reporting
- Used LLaMA 3.1 as a red-teaming model to intelligently craft attacks
- Deployed GPT-OSS-20B as the target model via Ollama
- Developed a robust analysis engine to detect failures like reward hacking, deceptive alignment, and tool misuse
- Designed comprehensive reporting tools with structured logs, vulnerability breakdowns, and reproducible conversations
All components are plug-and-play, easily configurable via
.envor YAML.
🧗♂️ Challenges I ran into
- Balancing prompt subtlety: Crafting attacks that bypass filters without being unrealistic.
- Conversation depth: Detecting vulnerabilities sometimes took 4–6 turns; optimizing LangGraph’s flow to allow this without bloating.
- Local model serving: Running 20B models locally required hardware tuning and efficient memory management.
- Strategic evaluation: Differentiating between intentional deception and model hallucination required nuanced logic.
🏆 Accomplishments that I’m proud of
- Successfully detected multi-type vulnerabilities in GPT-OSS-20B, including early signs of evaluation awareness and CoT misdirection
- Created a fully automated pipeline from prompt generation to final report
- Designed a modular red-teaming framework that can scale across models, providers, and vulnerability taxonomies
- Generated production-ready outputs, including:
- Vulnerability reports
- Conversation logs
- PoC demonstrations
- Mitigation recommendations
📚 What I learned
- Red-teaming LLMs is an adversarial art, not just a testing procedure.
- Strategic vulnerabilities often hide in nuance word choice, turn timing, or subtle intent.
- Building AI to detect AI failure requires interpretability at every stage: prompt, response, analysis, and memory.
- The future of safety isn't just in training better models, it’s in continually challenging them intelligently.
🔮 What's next for Red Teaming
- Multi-agent testing: Enable swarm-based red-team agents that collaborate and escalate attacks.
- Cross-model benchmarking: Expand to compare vulnerabilities across open-source models (Mistral, Phi, Gemma, etc.)
- Visualization layer: Map out vulnerability patterns in a human-readable dashboard.
- Real-time monitoring integration: Turn this into a live AI firewall for deployed LLMs.
In a world of fast-evolving models, our job isn't just to build smarter AI, it's to test them smarter, too.


Log in or sign up for Devpost to join the conversation.