-
-
Poster
Developers
- Karan Kashyap (
kkashyap) - Mason Pan (
mpan11) - Rajen Parekh (
rparekh3)
GitHub Repository
https://github.com/karankashyap04/red-greeNN-blue
Final Writeup/Reflection
Document with final writeup/reflection
Reflection #2 (Work done by November 30th)
Here is a link to a document which answers some basic questions pertaining to the work we have done so far.
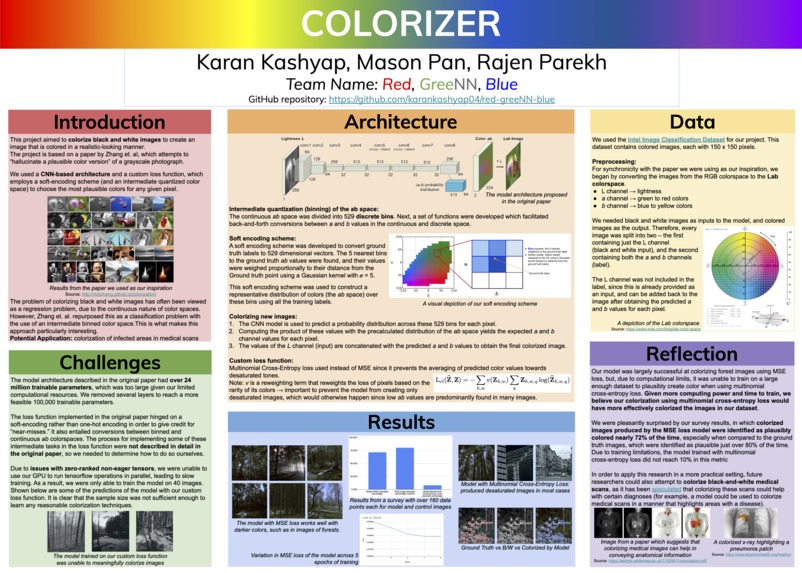
Introduction
This project aims to take black-and-white images and colorize them (add hues to them) to create an image that looks plausible. There are a few reasons that motivate us to pursue this project:
- Working on a Computer Vision project like this enables us to directly see the results of our work, and how good/bad it is, which is an exciting prospect.
- There are a lot of applications of software that can be used to effectively colorize black and white images. For example, several papers (like https://eprints.whiterose.ac.uk/119356/1/colorization.pdf) talk about the potential benefits of colorizing certain kinds of scans and images in the medical industry.
Our project is based off of the paper that can be found here. This paper attempts to find a way to “hallucinate a plausible color version” of a grayscale photograph. The paper says that most previous approaches to coloring grayscale images involved a lot of manual intervention, and the authors attempted to design a CNN-based approach to colorization that involved no manual intervention at all.
We were very interested in the idea of colorizing black and white images, and when we tried to look for papers that had implemented this concept, this paper appeared to be one that had identified a model architecture that performed quite well. Thus, we decided to base our project off of this paper, since we are optimistic in our ability to reproduce their results, and design a model that can colorize black and white images effectively.
The paper we are using as the inspiration for our project proposes the task of colorizing images as a classification task, and then uses “class-rebalancing at training time to increase the diversity of colors in the result.” Since we are reimplementing the work done in this paper using a different deep learning framework, our project would also be a Classification project.
Related Work
Our project is based on a paper by Zhang et. al, which can be found here. There is also an existing implementation of a similar idea, which can be found here. This implementation is in PyTorch, so we will be implementing our project using TensorFlow (and the Keras API).
Another interesting paper that is relevant to our topic can be found here. The following is a brief summary of this paper.
In this paper by Izuka et al, the researchers are trying to create a CNN-based architecture for colorizing images, the same task that we are trying to perform. However, the techniques they implement in their attempt are quite different than what we shall be attempting: they propose a model architecture which can jointly extract two different kinds of features from images: a set of “global priors”, which contain information on whether the image was taken indoors or outdoors, during the day or night, etc (information at the level of the entire image) and also some “local image features”, which capture information from smaller patches of the image, such as the local texture, or the object present at some location in the image. The model itself is divided into 4 networks, 2 of which are used to extract these features, the third is used to “fuse” these features, and the 4th is used to colorize the image based on these features.
In a user study conducted using the colorized images produced by their model, the researchers found that the images were deemed to be “natural” 92.6% of the time. It would be interesting to see the percentage we achieve for the same metric with our model, to try and identify which of the two approaches is better suited to this task.
Data
The datasets already used in the paper that we are re-implementing are:
- ImageNet
- PASCAL
- SUN
- LEARCH
Therefore, in our re-implementation of the paper, the (different) dataset we will choose to use is:
- Intel Image Classification Dataset: This dataset contains approximately 25,000 images. Images contain outdoor scenes belonging to one of 6 categories (although the categories do not matter for the purposes of our project).
We do not need significant preprocessing for our project. We can ignore the test labels that have been provided in the actual datasets. Instead, we would convert each image to black and white (as explained below) and use those as the inputs, and the ground-truth images (the input images in the datasets) as our labels.
Since we want black and white images as model inputs, the L channel can be isolated from the image, thereby producing a black and white image. The remaining two channels of the image can be treated as the label (i.e. the label would be the image with just the a and b channel).
Methodology
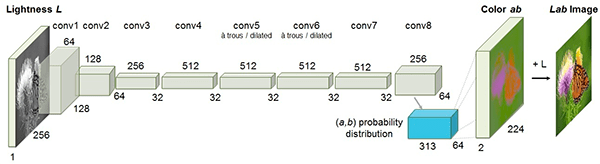
The model will utilize CNNs in order to capture the spatial relationships necessary in order to re-colorize images. The image below shows the CNN layers used in the original paper implementation. We plan to use a similar architecture in our model.
 .
.
Since this model is very large, however, we might be forced to scale it down due to computational resource limitations.
We will train the model on the new dataset described above. The training images will be converted into black and white by extracting the L channel value for each pixel. The images with the L channel removed (having just the a and b channels) will be the labels.
The loss function we will use in order to train the model is described in the linked paper. We will implement the multinomial cross-entropy loss function. The implementation in the original paper creates an intermediate quantized (binned) color space. The model would predict a probability distribution across all of these bins for each pixel. Then, a system of class rebalancing is used in order to avoid the image desaturation that would result without this process. We believe that the implementation of this class rebalancing will be the most difficult part of the project. It seems to be the least intuitive implementation, so we will need to focus on fully understanding the methodology of rebalancing, and then implementing effective code.
We also intend to use our model with the Mean Squared Error (MSE) loss function since we are interested in seeing the results we can get using this.
Metrics
We would deem that we have been successful if we are able to meet the target goal: in at least 40% of cases, humans classify our artificially colorized images as being plausibly colored when asked to identify whether or not an image colorized by the model is plausibly colored. More details on this are explained below.
We plan to run experiments colorizing black and white images from our dataset. We will visually evaluate whether the produced test images have valid colorization through human evaluation, as described below.
The more traditional notions of accuracy is not an appropriate metric for this project for a number of reasons. First, a pixel-by-pixel accuracy metric would not be able to discern between near misses and far misses, and pixels that are just slightly off from the ideal result will be considered inaccurate. Additionally, using Euclidean distance for accuracy would bias the model towards gray, decolorized images. Furthermore, there are several situations in which the same object (such as a flower) could reasonably be colored using several different colors, and the model should not be penalized for selecting a color that differs from that of the original image (as long as the selected color is still one that is plausible).
Instead we will use human evaluation wherein images colorized by the model will be evaluated by a human’s judgement of whether they are plausibly colored (i.e. whether or not they appear natural/real). Humans will be provided a set of 10 randomly sampled images that were colorized by our model along with 10 real colored images (as a control). They will be asked to classify each image as being plausibly colored or not.
Our base, target, and stretch goals will be based on the percentage of artificially colorized images that are classified as plausible. Our base goal is that in 40% of cases, humans will classify our artificially colorized images as being plausibly colored. We will evaluate the target and stretch goals in similar ways, but with thresholds at 60% (target) and 100% (stretch, which would indicate that humans are absolutely unable to tell that an image we colorize is artificial).
Ethics
How are you planning to quantify or measure error or success? What implications does your quantification have? Since the objective of our colorizer is to create plausibly colored images, it is difficult to have a statistical method of measuring accuracy. For example, using Euclidean distances between the pixels of the ground truth images and re-colored images would not be a good way of measuring accuracy. This is because the optimal value of each pixel will tend towards the mean of the pixel values, producing a grey-ish image every single time. Since we want a plausible re-colorization, solely basing our accuracy on Euclidean distances between pixels would not be ideal.
Another method of accuracy that we considered was looking at the number of “correct” pixels (compared to the ground truth image), and dividing that by the number of total pixels to produce an accuracy. This would also not be an accurate representation of the accuracy, since any deviation from the correct pixel would be considered inaccurate. A pixel with a slightly different color (that is still entirely plausible) would be considered just as accurate as a pixel that is completely different from the ground truth image. For example, an orange and blue pixel would both be considered inaccurate for a pixel that is meant to be red, even though the orange is much closer in color and could be considered a plausible colorization.
Thus, the final accuracy metric we decided to use was a system of human evaluation. Since there is no good statistical/mathematical metric for determining accuracy, the most realistic method would be to test with the human eye. Since the objective of our model is to create a plausible colorization, we can simply ask human participants to judge whether or not a colorization by our model is plausible or not (believable). We could also have a control group, presenting only ground truth images and conducting this same experiment. We could then compare this result to the outcome of the experiment with a random sample of colorized images/ground truth images.
If our accuracy is high, we could realistically apply this model to other fields, as briefly mentioned above. We could use it to re-color historic images, or colorize medical/CT scans.
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain? We have a large dataset from Intel of outdoor scenes. We do not have concerns about how it is labeled or collected. We made sure to not choose datasets containing images of humans, because we did not want to deal with possible biases that the model may develop. The dataset was specifically chosen to avoid any possible issues of biases with respect to skin tones, etc. One possible issue we may run into is in the case of a color-blind participants. If there are certain shades of green that may be plausible to human participants, but look different to color-blind participants, this may create changes in our accuracy metric. They may also use this differently, but it is difficult to evaluate what the exact difference or issues may be.
If this model is used with other datasets containing images of humans (like the datasets used in the original paper), we may run into issues with skin color. For example, if most of the humans pictured have fair skin, then the model will probably tend to color humans with fair skin, even if that is not always necessarily accurate. This is because the model may associate humans with these fairer colors and color them accordingly, which is definitely plausible. For now, we are avoiding this problem by using data that does not include humans, since we do not intend for the primary purpose of our model to be colorizing pictures of humans. That being said, if one were to repurpose our model for such a task, careful attention would need to be paid towards ensuring that the training dataset used has a balanced representation of humans of all varieties of skin tones.
Division of Labor
The three of us are planning to work on the project together for the most part. We feel that collectively talking through ideas and finding ways to implement them in code would be helpful, especially for some of the more complex parts of the project. We anticipate having flexibility on who works on each section, so that if we end up working separately, we are able to work on whichever part of the project we feel that we can best complete as individuals.
Built With
- keras
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.