-
-
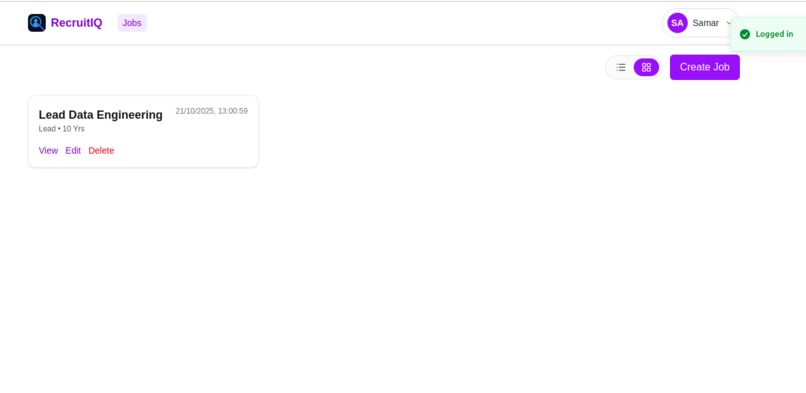
Jobs/Home
-
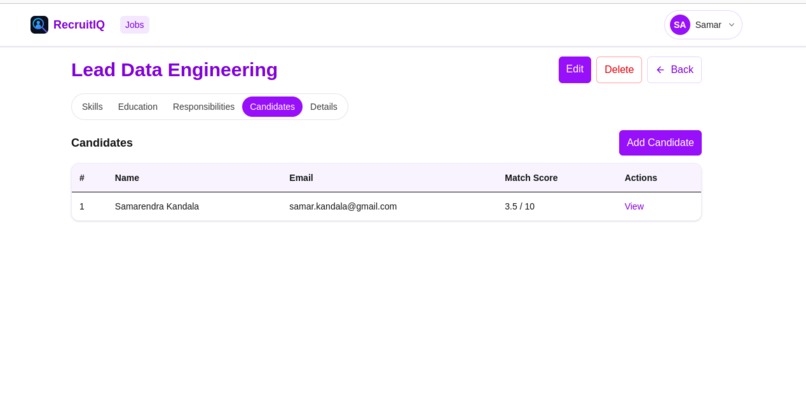
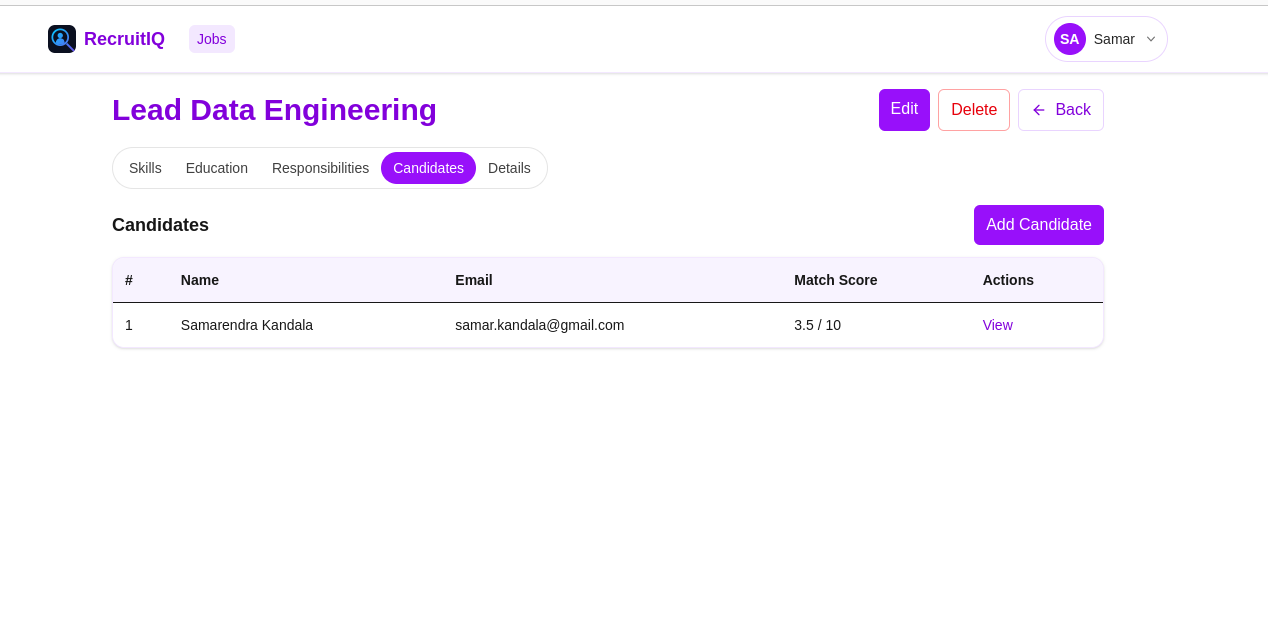
Candidates
-
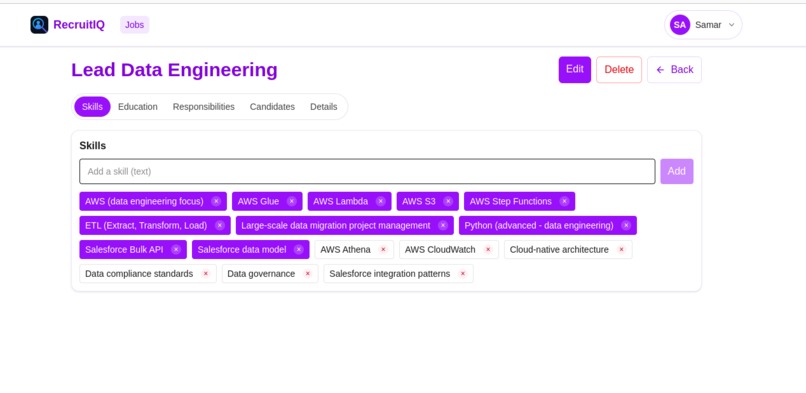
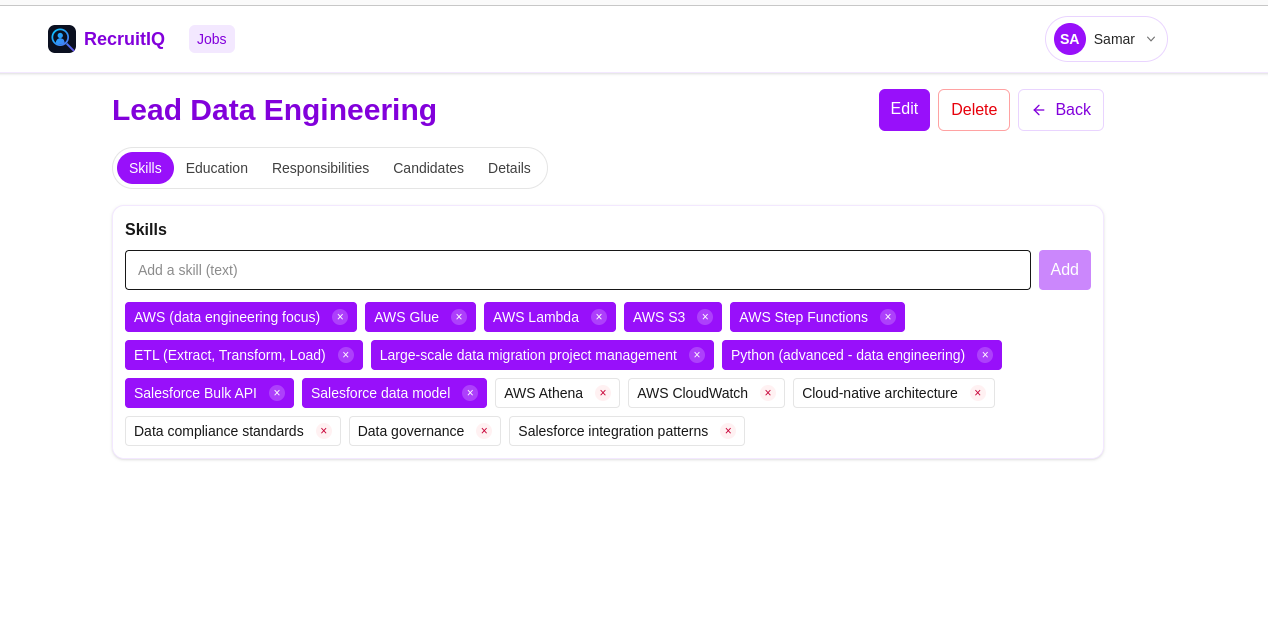
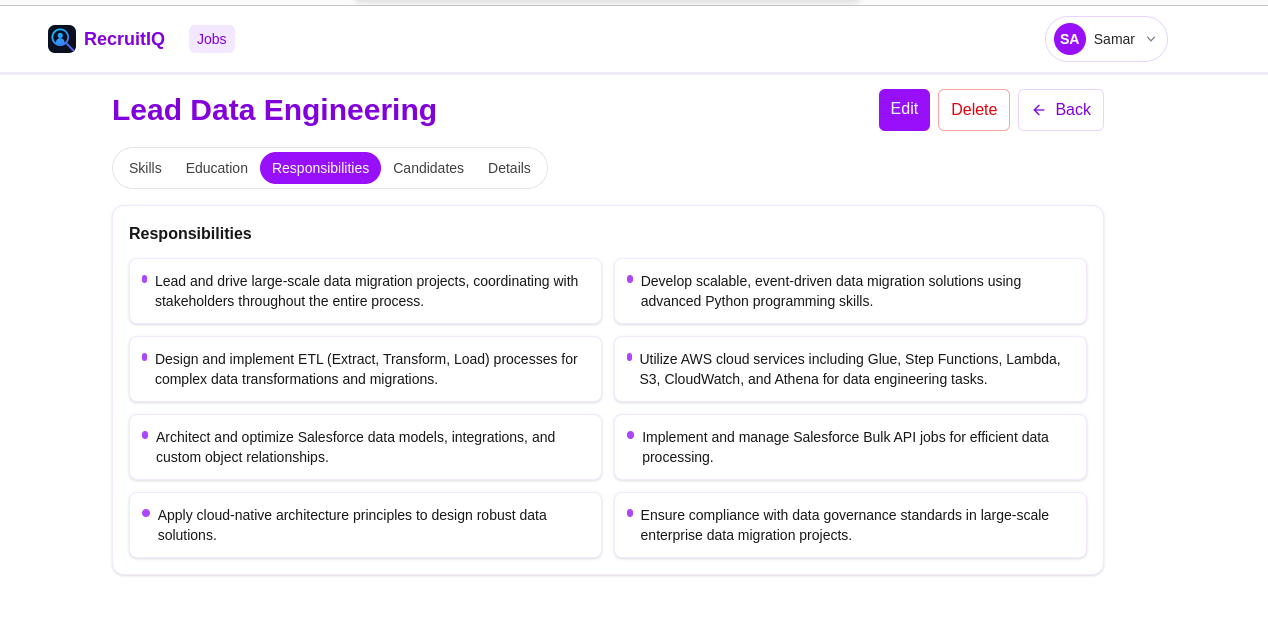
Job View - Skills
-
Login
-
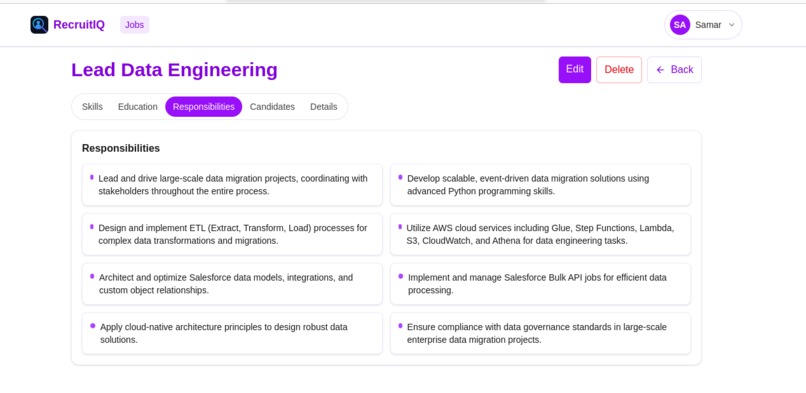
Job View - Education and Experience
-
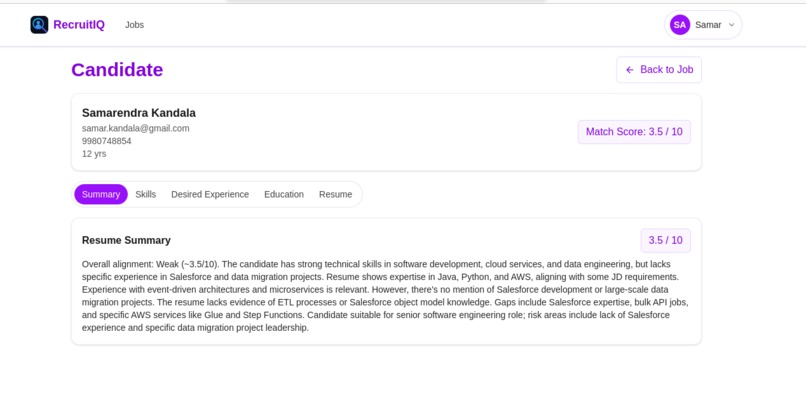
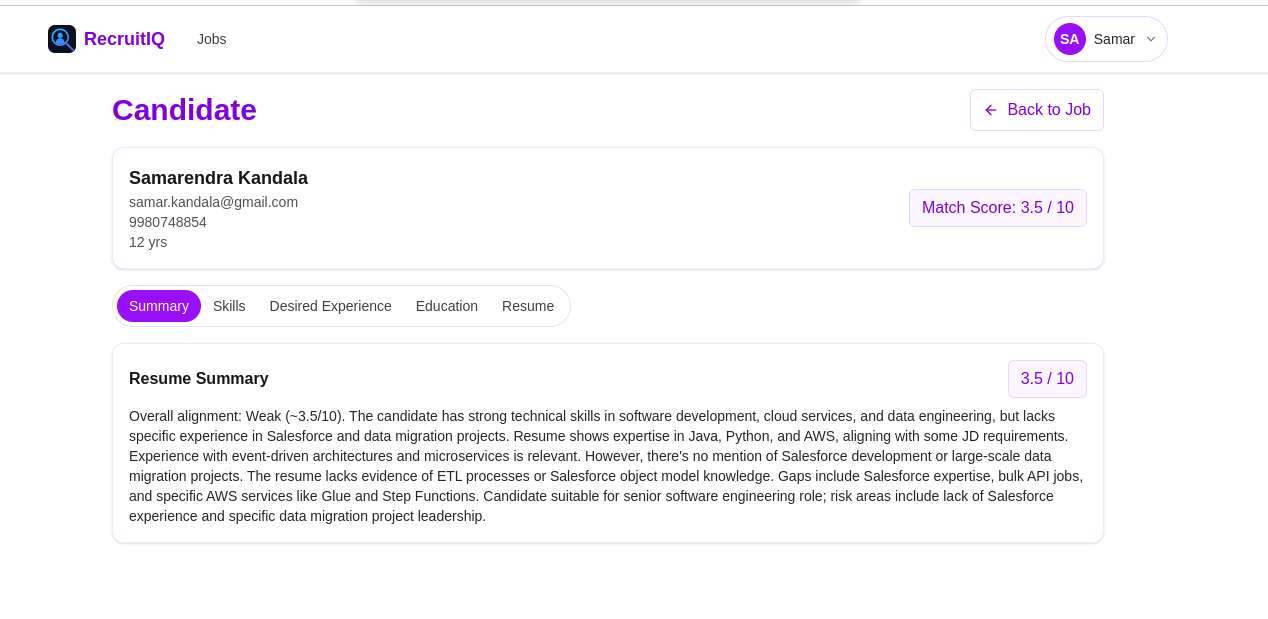
Candidate View
-
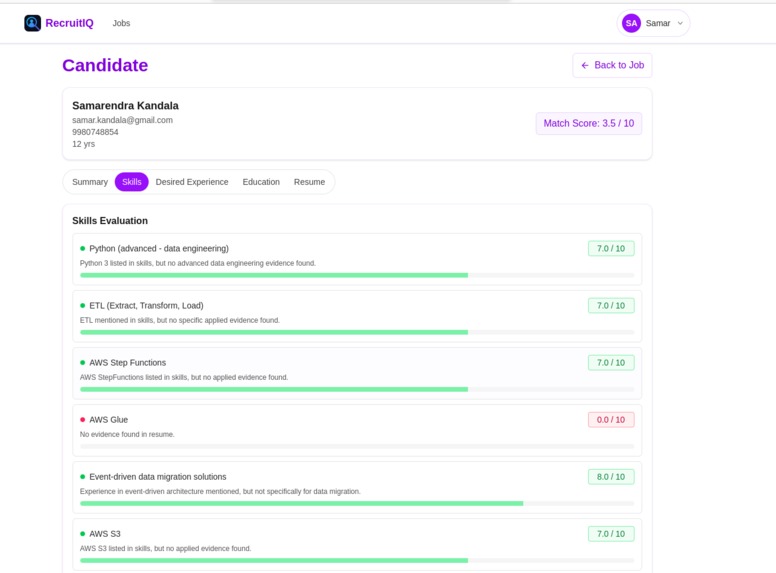
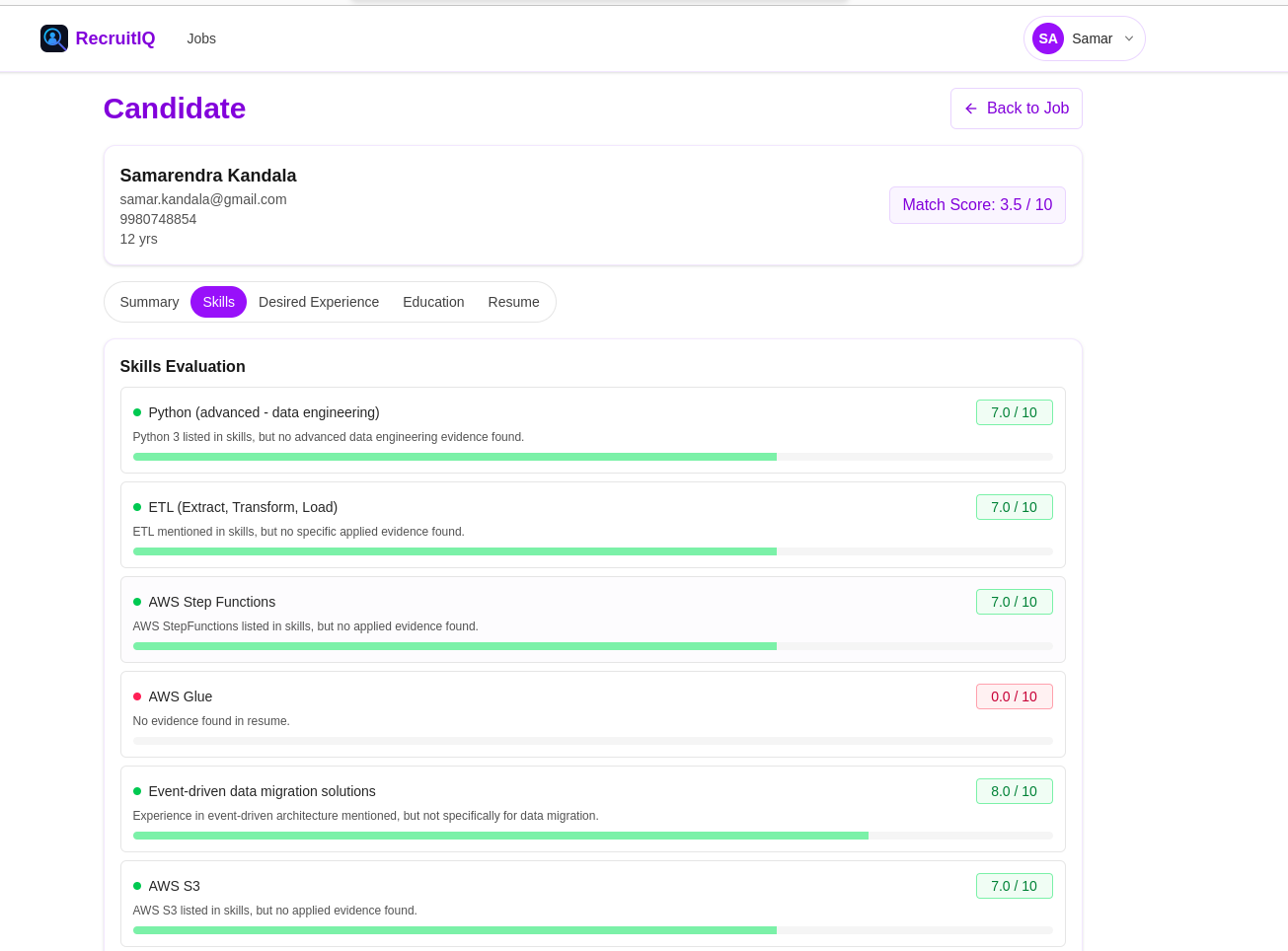
Candidate Skills Score
-
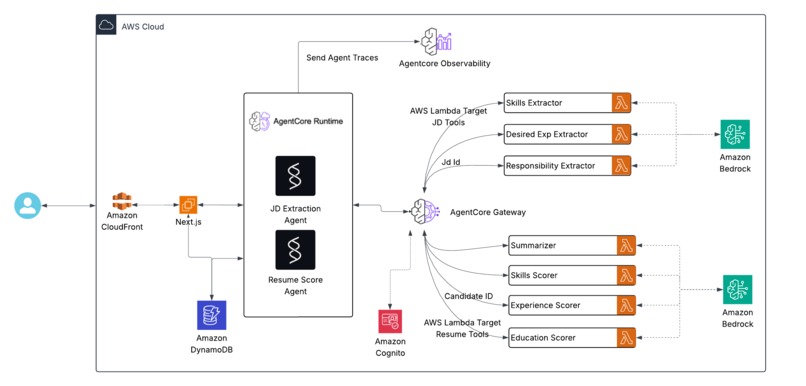
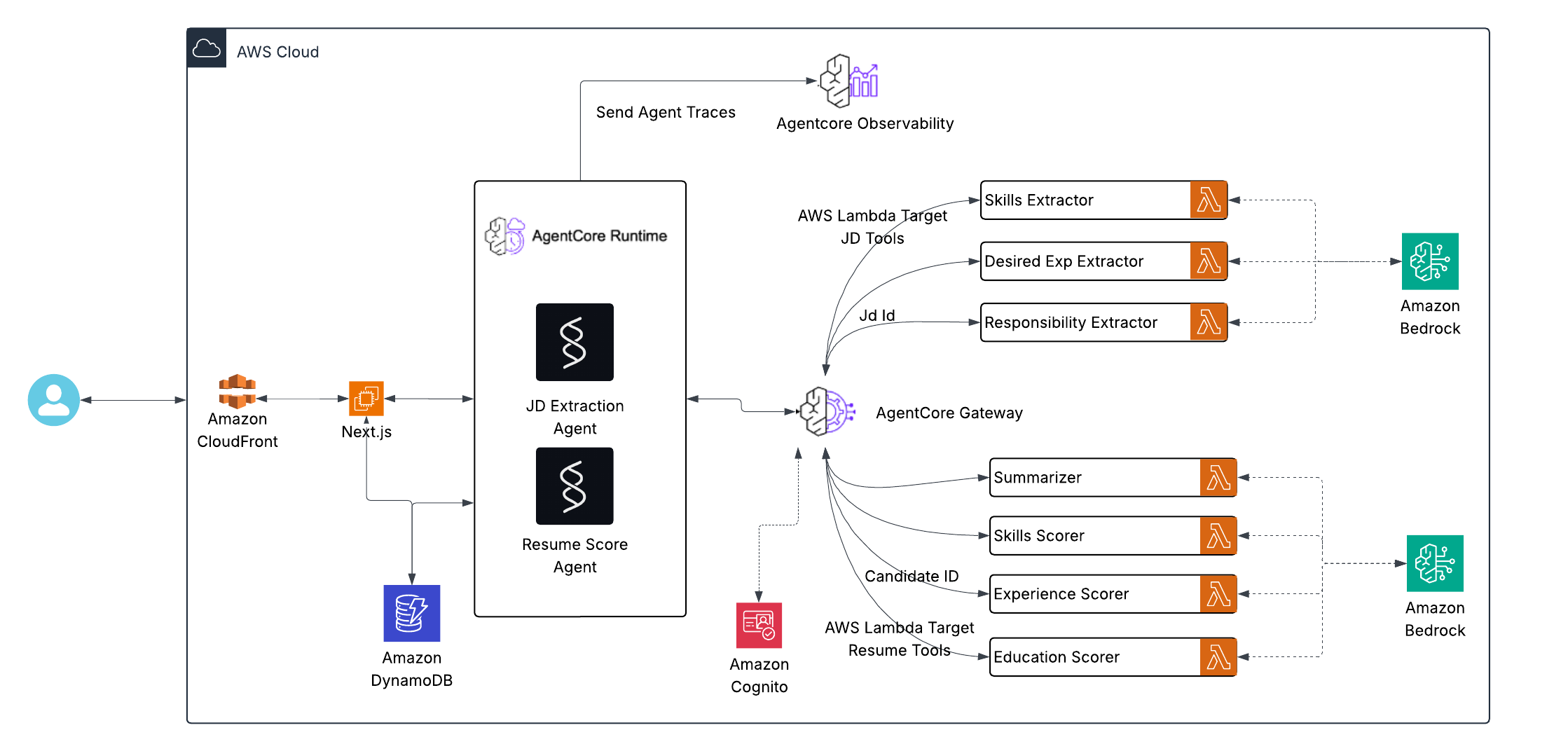
Architecture Diagram
🚀 RecruitIQ — AI-Powered Insight for Every Hire
Inspiration
As a Lead Architect and Fullstack Center of Excellence (CoE) Lead, I work closely with our recruiting team to evaluate and hire top engineering talent.
Over time, I noticed that a significant amount of recruiter effort went into initial (L1) screening — manually reading through resumes, mapping them against job descriptions, and identifying candidates who might be a good fit.
This process was time-consuming, inconsistent, and highly dependent on individual judgment.
Even with detailed JDs and skill matrices, the outcomes varied across recruiters and hiring cycles.
We needed a system that could:
- 🧠 Reduce manual L1 screening effort
- ⚖️ Ensure consistency and fairness across evaluations
- ⚡ Accelerate decision-making while maintaining quality
- 🔍 Provide explainable insights into candidate–role matching
That’s when the idea for RecruitIQ was born — an AI-powered hiring assistant that brings intelligence, consistency, and automation to every step of the recruitment process.
What it does
RecruitIQ reads job descriptions, resumes, and candidate data to extract skills, experience, and education, then matches them intelligently using explainable, structured insights.
It automates the L1 screening process and provides recruiters with:
- Smart candidate–job matches with confidence scores
- Transparent reasoning on why a candidate is a good fit
- Structured, exportable data for analytics or ATS integration
- A consistent and fair screening mechanism
How we built it
RecruitIQ is built on top of AgentCore and Strands, leveraging AWS-native modular agents for each specialized task.
🧩 Architecture Overview
Next.js → AgentCore Runtime → AgentCore Gateway Tools -> DynamoDB
- Document Ingestion:
Job Descriptions (JDs) and resumes are ingested and stored in DynamoDB, along with metadata such as upload time, source, and processing status. - Skill & Experience Extraction:
- A Skill Extractor Tool maps skills to a frozen taxonomy.
- A Desired Experience Tool captures role expectations.
- An Education Extractor Tool identifies academic qualifications.
- A Skill Extractor Tool maps skills to a frozen taxonomy.
- Resume Processing:
- Sparse ResumeChecker: Validates structure, completeness, and readability of resumes.
- Resume Skills Scorer: Evaluates extracted skills and computes a Skill Match Score.
- Resume Summarizer: Generates concise summaries with a relevance score for the JD.
- Desired Experience Scorer: Compares resume experience with JD expectations to produce an Experience Fit Score.
- Resume PI Extractor (Personal Information): Identifies and structures key attributes like name, contact info, and location.
- Sparse ResumeChecker: Validates structure, completeness, and readability of resumes.
- Planner Agents:
Built with Strands and Agentcore Runtime, JD Extraction Agent and Resume Processing Agent decides which tools to invoke and in what order — based on task, and context. - Orchestration & Processing:
AWS Lambda functions coordinate with Bedrock models for reasoning and scoring, while AgentCore Gateway manages authenticated tool invocations. - Output:
The system produces deterministic JSON outputs containing extracted entities, scores, and metadata — suitable for ingestion into downstream systems such as DynamoDB
Challenges we ran into
- Maintaining deterministic LLM outputs without hallucinations.
- Optimizing Lambda runtime performance for chained tool execution.
- Designing explainable matching logic that recruiters can trust.
- Configuring the AgentCore Gateway with custom tools, managing inbound authentication
Accomplishments that we're proud of
- Fully modular, agent-based architecture running natively in AWS.
- Consistent structured extraction for JDs and resumes across multiple formats.
- Seamless orchestration through AgentCore Gateway with no manual intervention.
- End-to-end explainable matching system ready for production use.
- Reduced L1 screening effort drastically — from hours to under 60 seconds per JD.
What we learned
Building RecruitIQ deepened our understanding of:
- AgentCore + Strands is Powerful The combination of AgentCore runtime and Strands SDK made it surprisingly easy to build a production-ready agent. The tool-calling pattern with @tool decorators is elegant, and the event hooks provided excellent observability.
- Stateless Architecture Scales Initially considered using AgentCore Memory for conversation history, but realized a stateless approach was better for this use case. Each request gets fresh data from APIs, and there's no user-specific context to maintain. This makes the system more reliable and easier to scale.
- Designing prompt-driven deterministic pipelines for reliable LLM outputs.
- Configuring AgentCore Gateway with custom tools, inbound authentication, and secure tool registry.
- Deploying and managing AgentCore Runtime in AWS for modular, serverless AI execution.
- Implementing structured output validation and schema enforcement for explainable and consistent responses.
- Tools Should Be Atomic Each tool does one thing well. Rather than a single "optimize everything" tool, we created seven focused tools that the agent can combine intelligently
What's next for RecruitIQ
- Integration with existing Applicant Tracking Systems (ATS) for real-world use.
- Continuous learning from recruiter feedback loops.
- Bias detection and ethical AI scoring enhancements.
- Adding semantic candidate–role ranking with Bedrock embeddings.
RecruitIQ represents the next step in intelligent hiring — bringing explainability, automation, and precision into the recruitment process.
Built With
- agentcore
- amazon-web-services
- cognito
- dynamodb
- lambda
- nextjs
- python
- strands

Log in or sign up for Devpost to join the conversation.