-
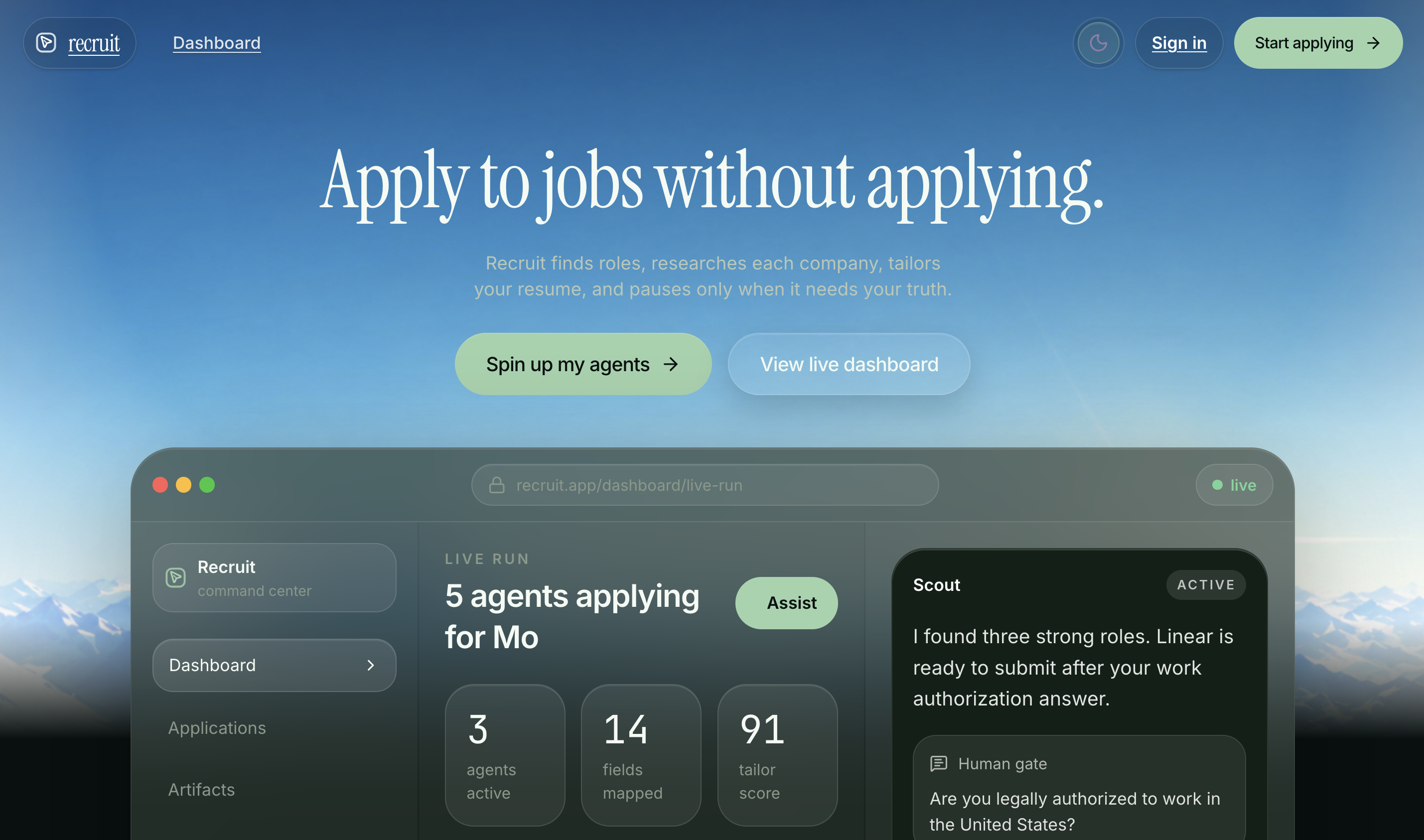
landing page
-
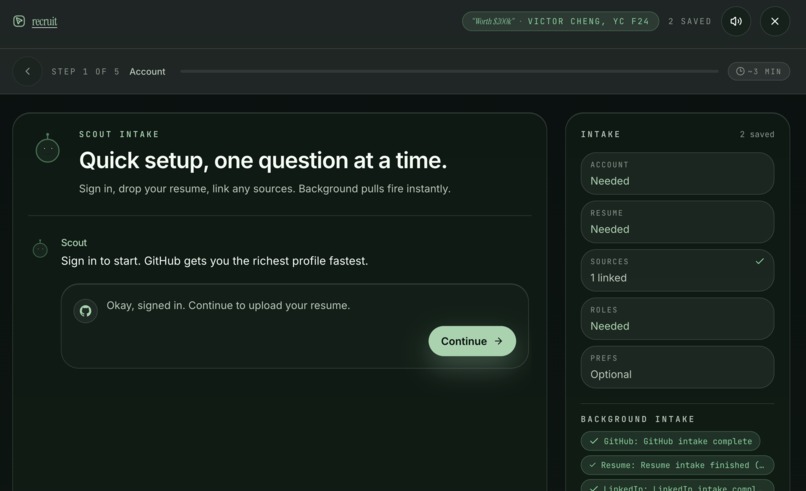
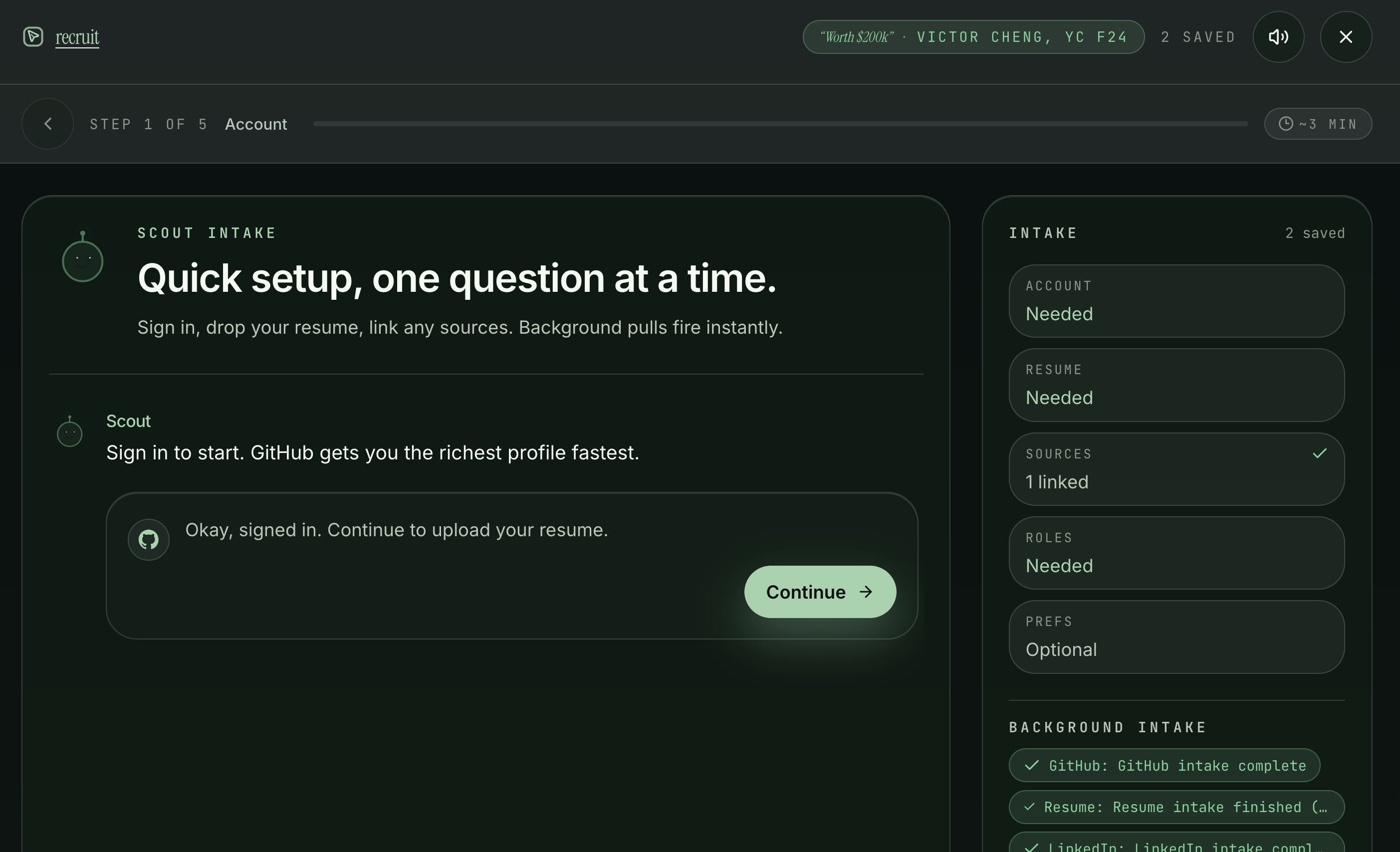
set-up page and ringing endorsement page
-
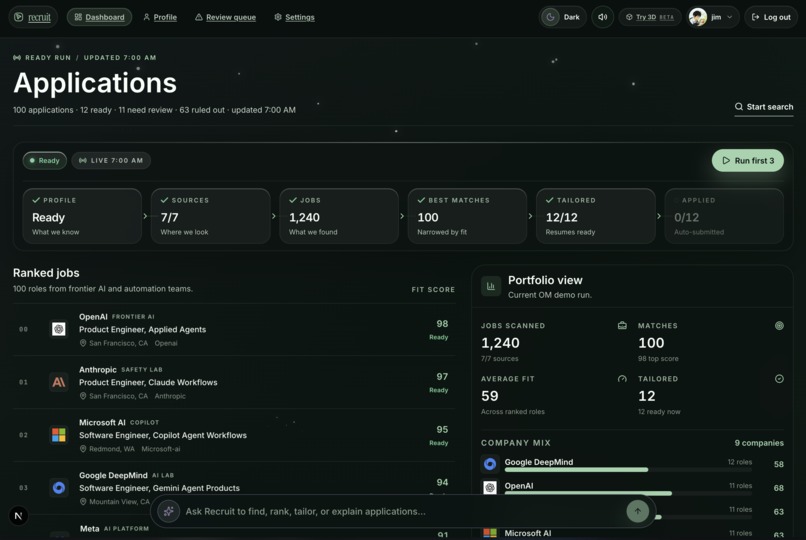
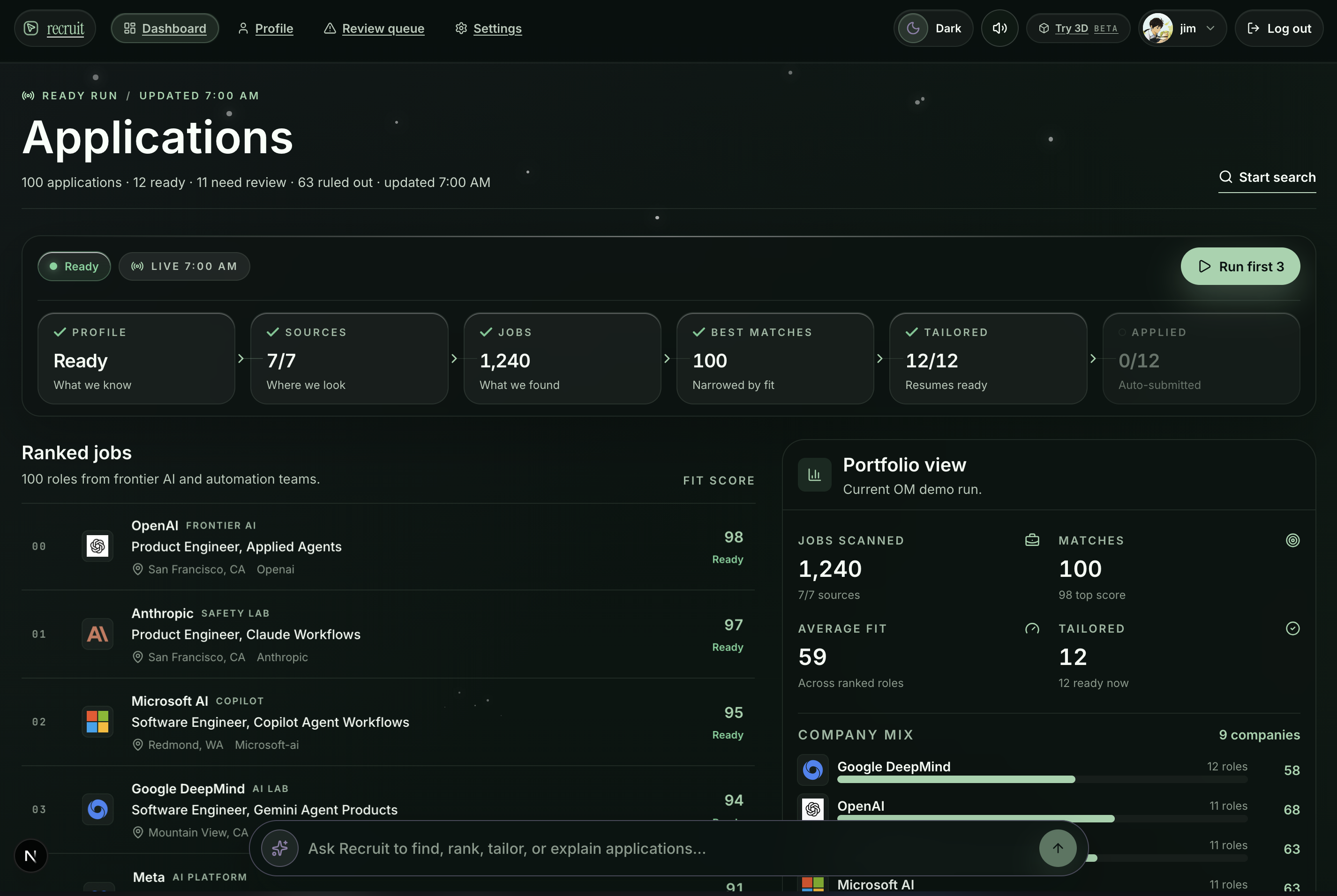
dashboard page
-
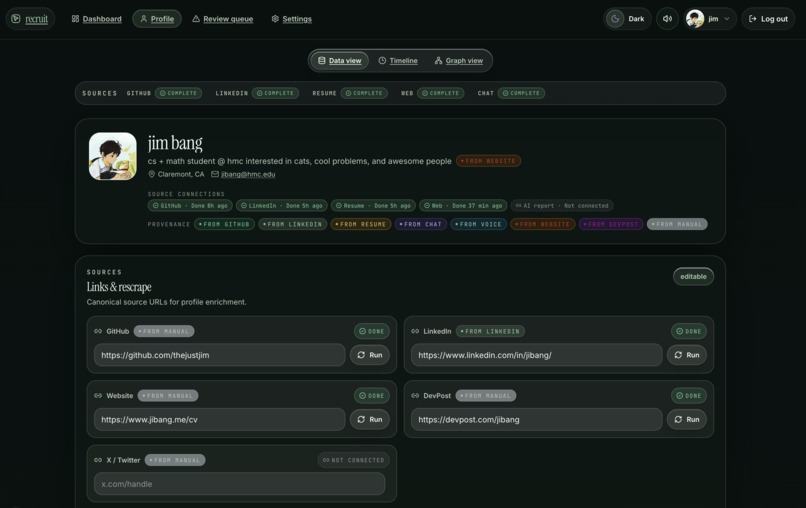
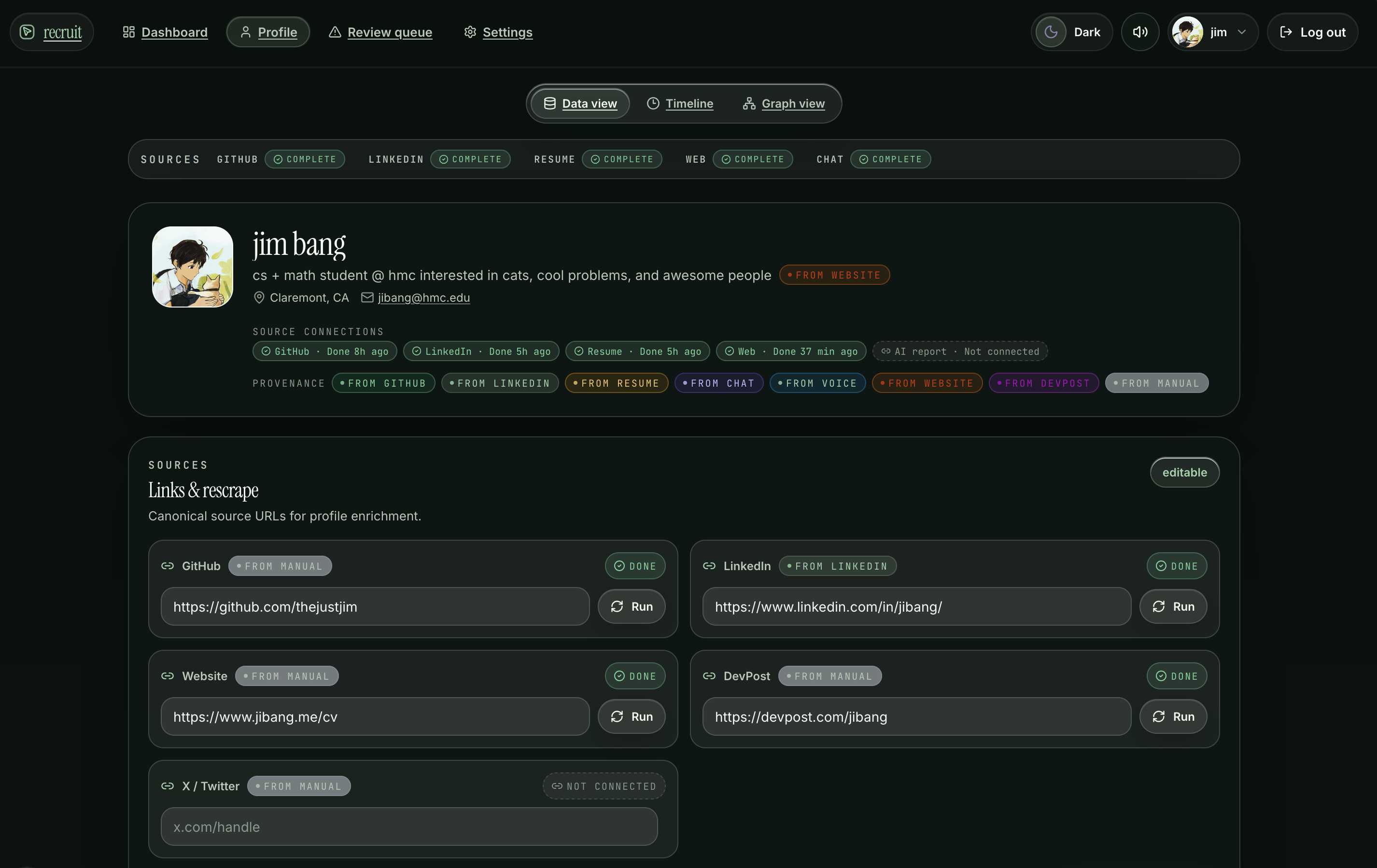
sample profile page
-
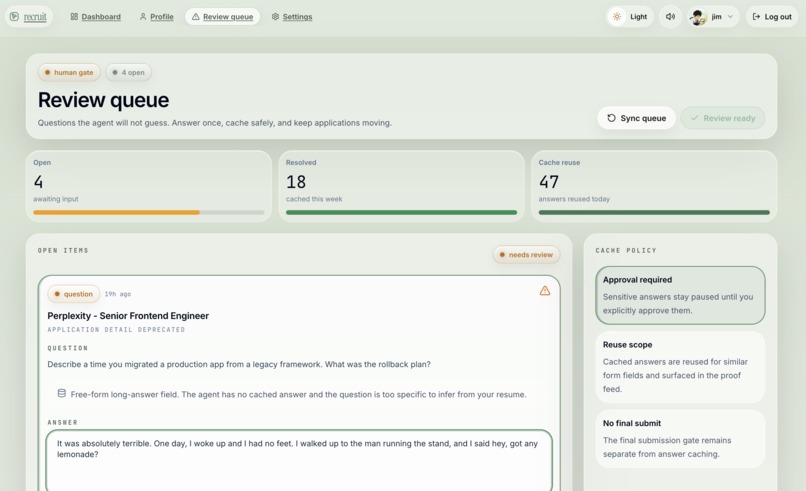
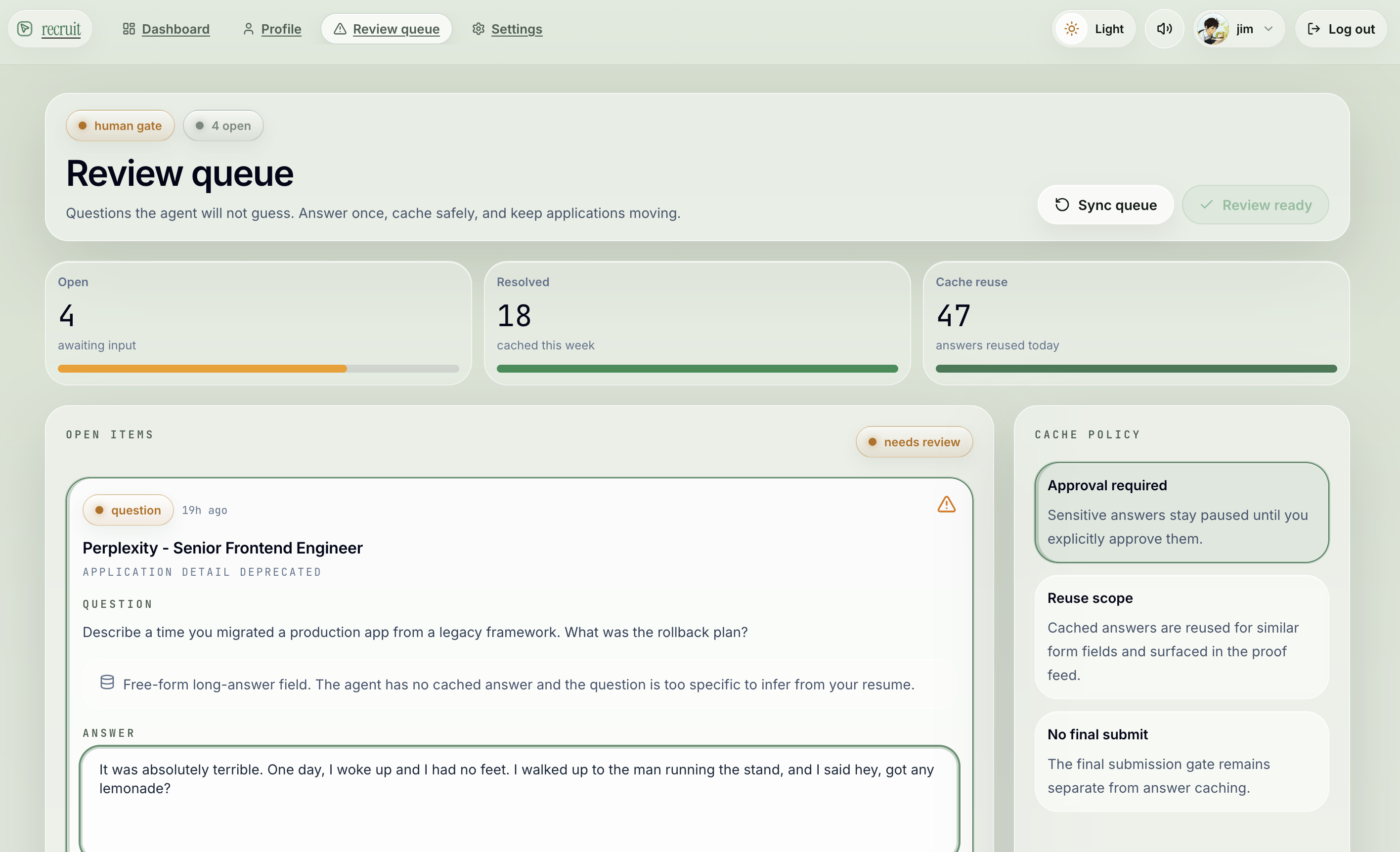
review queue page
Recruitt.tech: AI Agents that apply for you. Without making stuff up.
Inspiration
We're college students. We (unfortunately) know what the job hunt actually looks like.
You find a role on LinkedIn. You rewrite your resume for the third time this week. You open an Ashby form and type your name, email, phone, university, GPA, work authorization status — the same answers you gave yesterday, and the day before that. You attach a PDF. You write a cover letter you know nobody will read. You click submit and do it all again.
Multiply that by 100. That's what landing a job looks like right now.
It's just... paperwork. Repetitive, soul-crushing, high-stakes paperwork that every single person in this room will deal with in the next 12 months.
We built Recruitt.tech because we were drowning in applications and couldn't believe how much of the process was just copy-paste with anxiety. The resume rewriting, the form filling, the follow-up emails you forget to send... it's all mechanical, automatable. But the parts that actually matter — "Should I say I need sponsorship here?" "Is this role even a good fit?" Those require real judgment.
So we asked: what if an AI agent could handle the mechanical parts, but had the discipline to stop and ask you when the answer actually mattered?
What it does
Recruit turns one profile into a full job search.
You upload your resume, connect GitHub, link LinkedIn, maybe drop in your personal site.
Six intake adapters run in parallel, scraping repos, parsing PDFs, pulling work history, and everything merges into a single candidate profile with provenance tracking. The system knows where every fact about you came from.
From there, the agents take over:
They find jobs. Ashby boards get ingested. Roles get scored against your profile: BM25 keyword matching plus LLM confidence, and ranked. You see a leaderboard of your best-fit roles, not a mess of Workaday and other job boards.
They research companies. For each role worth pursuing, agents dig into three layers: what the job actually requires, what the company does, and what the culture looks like. K2 Think V2 reasons through this step by step. OpenAI does autonomous web search. Gemma handles extraction as a fallback.
They tailor your resume. This is the part we obsessed over. The agents produce a tailored single-page PDF for each role — but the doctrine is reformulation only, never fabrication. They'll rewrite "built LLM workflows with retrieval" as "RAG pipeline design" if the JD uses that language. They will never add a skill, employer, or project you don't have. A deterministic anti-fabrication validator checks every output, and fabricated content is a hard failure.
They fill the forms. Agents discover ATS fields, map questions to your profile facts and approved cached answers, upload the tailored resume, and stage submission evidence. Your name, email, phone? Auto-filled. Your salary expectations, work authorization, demographic info? Those go to the review queue.
They know when to stop. This is the feature we're proudest of. The dead letter queue catches every question the system can't answer safely. You approve once, and the answer gets cached for future forms. The system never guesses on truth it can't verify. Ever.
They follow up. Auto-scheduled at +5 business days (email) and +12 business days (LinkedIn), with drafts generated and manual triggers.
This isn't a resume generator with a chatbot on top. It's the full pipeline — discovery, ranking, research, tailoring, form filling, human review, submission staging, and follow-ups — built around one reusable candidate profile that gets smarter with every application.
How we built it
The short version: Next.js 16 + React 19 + Convex + three AI providers + a loooot of celsius.
The longer version:
The frontend is real time + ready for ur command. The dashboard has a leaderboard sorted by tailoring score, a detail panel with research and PDF preview, and a command palette for power users. The onboarding flow walks you through five steps — account, resume, connected sources, preferences, activation. You can even interact with your job listings in a 3d room.
The backend runs on Convex. Every intake event persists to intakeRuns for live UI streaming, then profile patches merge into the canonical userProfiles document. Convex's reactivity means the dashboard updates the instant an agent finishes tailoring or hits a DLQ item.
The AI architecture is where the headaches began. We built a provider-agnostic pipeline that routes through three model families:
- K2 Think V2 (IFM, 70B reasoning) — Chain-of-thought reasoning for job research and resume tailoring. The model thinks out loud about requirements, skill mapping, and gap analysis, then produces structured JSON. We parse out the reasoning from the
</think>delimiter. - OpenAI (GPT-5.4 Mini, GPT-4o Mini) — Default tailor and research models. The Responses API with web search handles deep company research.
- Gemini / Gemma (Gemma 4 26B/31B) — Structured extraction fallback.
Switching providers is one environment variable. All three share the same prompt templates, the same quality validator, and the same scoring formula.
The intake system uses six adapters — GitHub (Octokit + per-repo Haiku summaries), LinkedIn (Browserbase + Playwright), Resume (PDF extraction), Web (Firecrawl), Chat, and Voice — each implemented as an async generator yielding progress events with profile patches and provenance.
ATS form filling classifies every field by safety level. Safe facts (name, email, resume upload) get auto-filled. Derived profile data (skills, dates) get mapped. Sensitive questions (work auth, compensation, demographics) go to the DLQ. Essay questions get optional LLM drafts with mandatory review. Final submit is always gated — dry-run is the default.
Architecture
User -> Next.js 16 App Router
|-- /onboarding -> 5-step intake with 3D agent room
|-- /dashboard -> real-time command center + leaderboard
|-- /3d -> Three.js agent room (walk-around mode)
|-- /dlq -> human review queue + answer cache
\-- /profile -> data + graph views with provenance
Next.js Routes <-> Convex (real-time backend)
|-- intakeRuns -> streaming progress events
|-- userProfiles -> canonical profile + provenance
|-- jobs -> ingested + ranked roles
|-- tailoredResumes -> JSON + rendered PDFs
|-- applications -> staged submissions + evidence
|-- dlqItems -> review queue + cached answers
\-- followUps -> scheduled outreach drafts
AI Pipeline (provider-agnostic):
K2 Think V2 --\
OpenAI ---+-- research -> tailor -> validate -> score -> rank
Gemini/Gemma --/
ATS Layer:
Ashby (validated fill) -> Greenhouse / Lever / Workday (ingestion)
Resume + GitHub + LinkedIn + Web + Chat + Voice
| (6 parallel async generators)
v
Unified UserProfile (provenance-tracked)
|
v
Job Ingestion (Ashby API + public boards)
|
v
BM25 + LLM Ranking (top 40, cutoff 70)
|
v
Per-Job Research (K2 / OpenAI / Gemini)
|
v
Resume Tailoring (anti-fabrication validated)
|
v
ATS Form Fill (safe fields only)
|
v
DLQ <-- unsafe questions --> User approves --> Cache
|
v
Staged Submission (evidence captured, dry-run default)
|
v
Follow-ups (+5d email, +12d LinkedIn)
Challenges we ran into
ATS forms are a nightmare. Every company uses different field types, different labels, different validation. "Are you authorized to work in the United States?" shows up as a text field on one form, a radio group on another, and a dropdown with 47 options on a third. We had to build a field discovery engine that classifies by answerability, not HTML type.
Resumes kept lying. Early iterations would add employers the candidate never worked for, invent project metrics, and sprinkle in skills from the JD that the user didn't have. We waged war on this. The anti-fabrication validator cross-references every employer name, skill, and project against the verified profile. It checks for banned cliches ("spearheaded," "leveraged," "synergy"). It measures keyword coverage and penalizes the score if it's too low. If any hard check fails, the system retries at temperature 0 with a nudge. If it fails again, it gives up rather than submit a dishonest resume.
LinkedIn won't fit inside Convex. Playwright is too heavy to bundle as a Convex action. We ended up building a Next.js API route that streams SSE events and shims back into the same runIntake driver via a ConvexHttpClient adapter — so LinkedIn intake follows the exact same event/patch/provenance contract as every other source.
Accomplishments that we're proud of
We didn't build a resume generator, or even just an automated form filler. We built the whooole loop.
One profile goes in, and the system handles discovery, ranking, research, tailoring, form filling, review, and follow-ups. The DLQ isn't an error handler — it's a first-class feature that makes the product trustworthy. The answer cache means every question you approve makes the system faster for the next application.
The multi-provider AI architecture means K2 Think V2, OpenAI, and Gemini are fully interchangeable — same prompts, same validation, same scoring. One env var swaps the reasoning backbone.
Five agents live in a 3D apartment with walk-around mode and per-agent job focus views.
The pipeline works end-to-end.
What we learned
The best version of autonomy is not "do everything." It's "do the boring parts perfectly, and ask before you touch anything that matters."
Job applications are boring. Nobody wants to do them. But they're also personal and high-stakes — one wrong answer on a work authorization question can disqualify you in an increasingly competitive job market, and one fabricated employer on a resume can get you blacklisted. The system has to be fast and honest, autonomous and careful to ensure user trust.
Once you have trusted candidate memory, with a profile where every field has provenance, everything compounds into bliss. Ranking gets more accurate. Tailoring matches real skills. Form filling draws from verified facts. The review queue shrinks as the cache grows. The profile is the product.
What's next for Recruit
- Expand ATS support beyond Ashby — Greenhouse and Lever are ingestion-only today, we want validated fill paths for both
- Replayable application traces so users can audit every agent decision
- Confidence-gated auto-submit for roles above a score threshold
- Recruiter outreach and follow-up scheduling as first-class workflows
- Launch the hosted product — the pricing tiers are already in the landing page
Built with
Next.js, React, TypeScript, Convex, K2 Think V2, OpenAI, Anthropic, Google Gemini, Tailwind CSS, Three.js, React Three Fiber, Zustand, Framer Motion, Playwright, Puppeteer, Browserbase, Better Auth, Octokit, Firecrawl, ElevenLabs, Vercel
Track Submissions
"Not so sexy" (Main Track)
Job applications are the least glamorous workflow in tech. Nobody posts their ATS form-filling strategy on Instagram. Nobody's pitching "I automated the part where you type your phone number into a text box for the 47th time" at demo day. But 200M+ people change jobs globally every year, each burning 10-20 hours a week on applications that are 90% copy-paste. That's a trillion-dollar problem wearing khakis. Recruit automates the mechanical parts — resume rewriting, form filling, follow-up scheduling — and keeps humans in control of the parts that actually matter: work authorization, compensation, legal questions, anything where a wrong answer has real consequences. It's boring. It's unglamorous. It's the thing everyone in this room will need in six months.
IFM x Hacktech: Best Use of K2 Think V2
K2 Think V2 is a core reasoning provider in Recruit's two most critical stages. For job research, K2 reasons step-by-step through hard requirements vs. nice-to-haves, company products, and culture signals — the chain-of-thought catches nuance that single-pass extraction misses. For resume tailoring, K2 reasons about skill-to-requirement mapping and calibrates an honest confidence score before the anti-fabrication validator runs. K2 is a first-class provider in our multi-provider architecture. RESEARCH_PROVIDER=k2 and TAILOR_PROVIDER=k2 routes both stages through the 70B reasoning model. The </think> chain-of-thought is where the real value lives.
YC x HackTech
We chose Lever (YC S12). Lever built the ATS from the employer's side, a system for companies to track candidates through their pipeline. If Lever were founded today, it wouldn't just track applicants. It would be the applicant. Recruit is Lever inverted: an AI-native system that runs the entire application workflow from the candidate's side, using the same structured data, profiles, job specs, form schemas, follow-up timelines — but automated with agent reasoning and honest-by-default safety.
Sideshift x HackTech
Every student understands "I spent 3 hours typing the same 30 fields into 6 different forms." The pain is immediate and universal. Recruit is a consumer product with a clean surface, onboarding, dashboard, 3D room, review queue, and a one-sentence value prop: your agents apply while you prep for interviews. Pricing is already designed: $0 for 5 apps/month, $10 for 100, $20 for unlimited with outreach and auto follow-ups.
Palohouse x HackTech
Recruit is a company, not just a project. The wedge is a repeated painful workflow with real demand from a massive user base. The moat is candidate memory, a profile with provenance that compounds over time as the answer cache grows and the system learns what you've already told it. Ashby integration is live. The pipeline works end-to-end. Pricing tiers are in the product. The path from applications into outreach, follow-ups, and interview prep is clear.







Log in or sign up for Devpost to join the conversation.