-
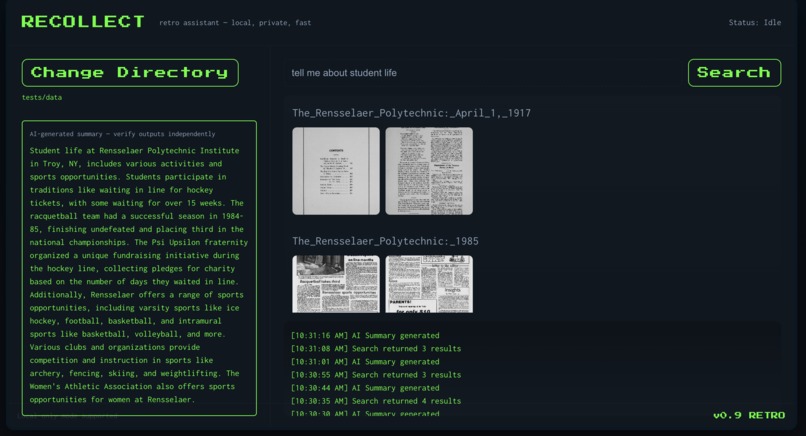
AI generated summary and semantic search results for a sample query.
-

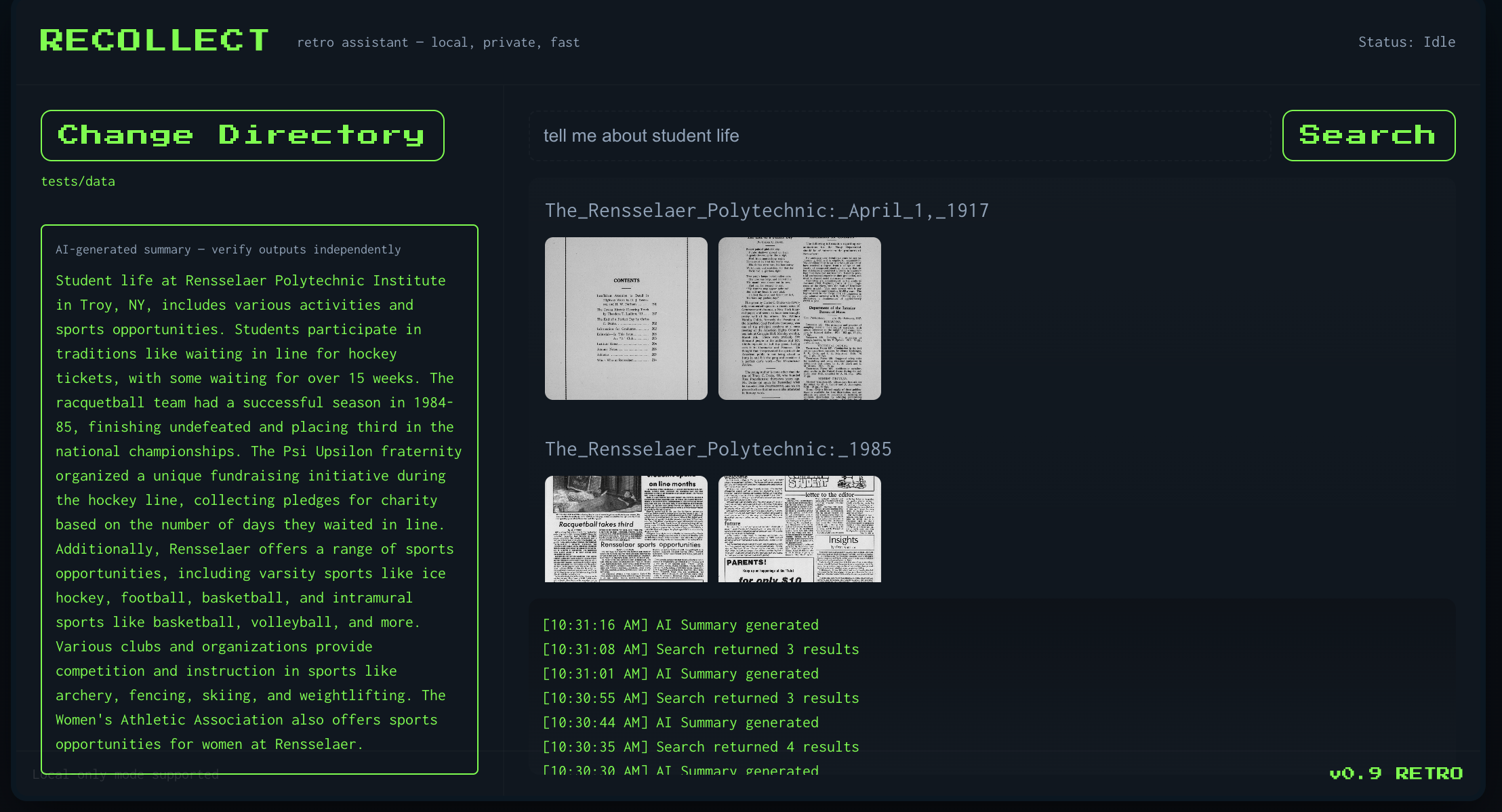
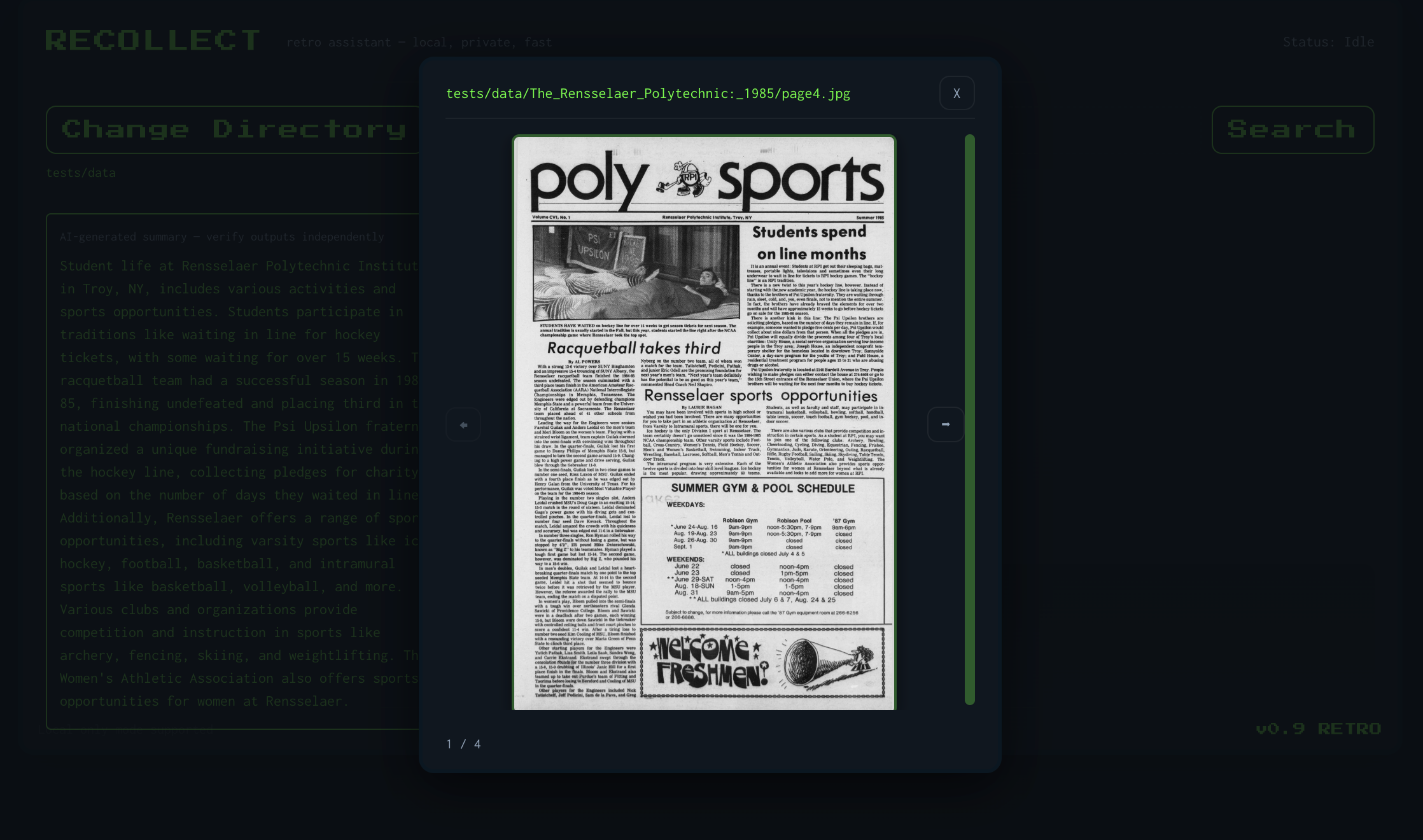
Document viewer for the same query.
Inspiration
We began with a simple question: What if RPI’s 200 years of history were as searchable and interactive as the modern web? HackRPI’s theme, “Retro vs. Modern,” pushed us toward this idea immediately. When we opened The Polytechnic’s archives, consisting of scanned issues dating back to 1869, and expected to browse them the way we explore any digital library. Instead, we found over 2,800 publications locked inside images with no text search, no image search, and no practical way to explore decades of student life or major events. The history was digitized, but not accessible.
It soon became clear that this wasn’t just an RPI problem. Around the world, universities, libraries, museums, newspapers, and historical societies have scanned millions of pages of old documents. Novels, scientific papers, posters, letters, and newspapers sit preserved as images, but without structure or searchability. The result is a paradox: more information has been digitized than ever before, yet much of it is effectively unusable.
This is where modern technologies, such as OCR, vector search, and agentic AI, can make a meaningful impact. Our goal became to show how these tools can turn static scans into interactive, searchable knowledge. Using RPI’s archives as a proof of concept, we demonstrate a pipeline that could scale to any historical collection. Academic researchers could instantly surface forgotten insights, local communities could rediscover regional history, and institutions could unlock vast stores of cultural memory that have remained hidden in plain sight.
Our project ultimately asks: What if the past didn’t have to stay passive? By combining retro material with modern AI, we believe it can become alive, explorable, and genuinely useful again.
What it does
Recollect transforms 132 years of RPI’s student newspaper into a fully searchable and interactive historical archive. Instead of manually browsing thousands of scanned pages, users can type a question or phrase in natural language, just as they would on a modern search engine.
Recollect instantly returns the most relevant pages across all issues from 1869 to 2001, using both OCR-extracted text and semantic search over the page images. Each result is fully navigable, allowing users to open the complete issue the page came from and explore it as it originally appeared.
Recollect also includes an AI agent that reviews the database with every query and produces a clear and concise written answer. Whether the user is curious about a historical event, a campus tradition, or the evolution of student culture, the agent summarizes the most relevant information directly.
How we built it
We built Recollect in four major stages: scraping, infrastructure, search, and AI orchestration. Each transforms static scans into something progressively more alive.
1. Collecting 56,000+ pages from the archives Our journey started with a custom Selenium-based scraper built to navigate The Polytechnic’s archive system. It clicked through every issue, opened every scan, and downloaded over 56,000 newspaper pages spanning 132 years.
2. Building the platform (frontend + backend) With the raw data in hand, we spun up a lightweight but fast system:
- A React frontend with a retro-inspired interface for browsing issues and viewing results.
- A Flask backend that handles data retrieval, query routing, and AI agent requests.
- This gave us the foundation to stitch new AI capabilities onto classic material.
3. Making historical scans searchable (OCR + embeddings)
- We ran OCR across every page to extract whatever text we could from decades of varying print quality.
- We generated semantic text embeddings for each page so we could search by meaning, not just exact keywords.
- We also computed image embeddings and mapped them into the same embedding space as the text. This gave us cross-modal search: text queries can retrieve relevant images, and image features can surface contextually similar pages.
All of this is indexed inside a KNN similarity search engine, letting Recollect surface the best matches instantly.
4. Adding an AI agent When a user submits a question, the agent:
- Independently decides how to interpret the query,
- Formulates its own search request,
- Calls our vector engine to gather the most relevant documents,
- Reads, filters, and synthesizes the retrieved text,
- And finally produces a clear, well-reasoned explanation of its findings.
Challenges we ran into
Throughout the development of Recollect, we ran into several obstacles that shaped our final system. One of the earliest challenges was getting a consistent set of packages running across different machines, each with its own hardware configuration and operating system. Ensuring compatibility for OCR, embedding models, and the agent pipeline required careful troubleshooting.
Experimenting with different OCR models was another major hurdle. The quality of historical newspaper scans varies significantly, so we spent time testing multiple approaches before settling on the one that produced the most reliable results. Scraping the full dataset also proved to be extremely time consuming, which pushed us to parallelize the process across multiple workers to make it manageable within the hackathon timeframe.
We also had to make thoughtful decisions about which language model to use and how to structure our AI agent. Designing a system that could interact seamlessly with the OCR output, search the dataset, and generate useful summaries introduced complexity we had not faced before. Integrating all these components into a unified workflow took time and problem solving, but working through these challenges ultimately strengthened the project.
Accomplishments that we're proud of
We are proud that Recollect makes parts of RPI’s history easier to access. The Polytechnic contains decades of work from students, faculty, and staff, and it feels meaningful to help surface material that was previously difficult to explore.
On the technical side, we are happy with how much we were able to accomplish in a short amount of time. Integrating OCR, semantic image search, natural-language querying, and an AI agent into one system was challenging, especially over such a large dataset, but the features came together to produce results that greatly exceeded our initial expectations. Achieving reliable search across both text and images was a highlight for us.
Overall, we feel good about what our team built and how well the components worked together by the end of the hackathon.
What we learned
Working on Recollect pushed us into several new technical areas. One major challenge was figuring out how to perform semantic search over both text and images using a single natural language query. Designing a unified workflow for two very different data types taught us a lot about embeddings, indexing strategies, and retrieval pipelines.
Several members of our team had no prior experience building AI agents, so developing a system that could search the dataset and generate concise summaries required a significant amount of learning and experimentation. We also had never applied OCR models before, especially on historical newspaper scans, so understanding how to process noisy or imperfect text was an important part of the process.
Another major area of growth was large scale image scraping and storage. Managing thousands of high resolution pages, handling long processing times, and structuring everything into a searchable resource gave us practical experience with data engineering challenges that none of us had dealt with previously.
Overall, the project introduced us to new tools, new concepts, and new problem solving approaches, and each part of the system taught us something valuable.
What's next for Recollect
Looking ahead, there are several enhancements we are excited to explore. One of our priorities is improving the user interface, including smoother navigation and the ability to zoom into individual pages for easier reading. We also plan to add the option to search by specific years or time periods and give the agent greater awareness of this context so it can produce even more accurate summaries. Beyond RPI’s archives, we hope to expand Recollect to additional datasets, demonstrating how this approach can uncover the hidden value within other historical collections.
We really appreciate your time and interest in our project!
Joel, Erik, Aiden

Log in or sign up for Devpost to join the conversation.