-
-
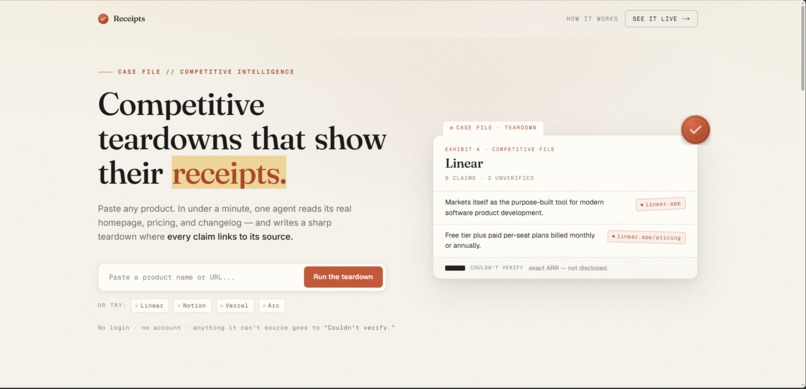
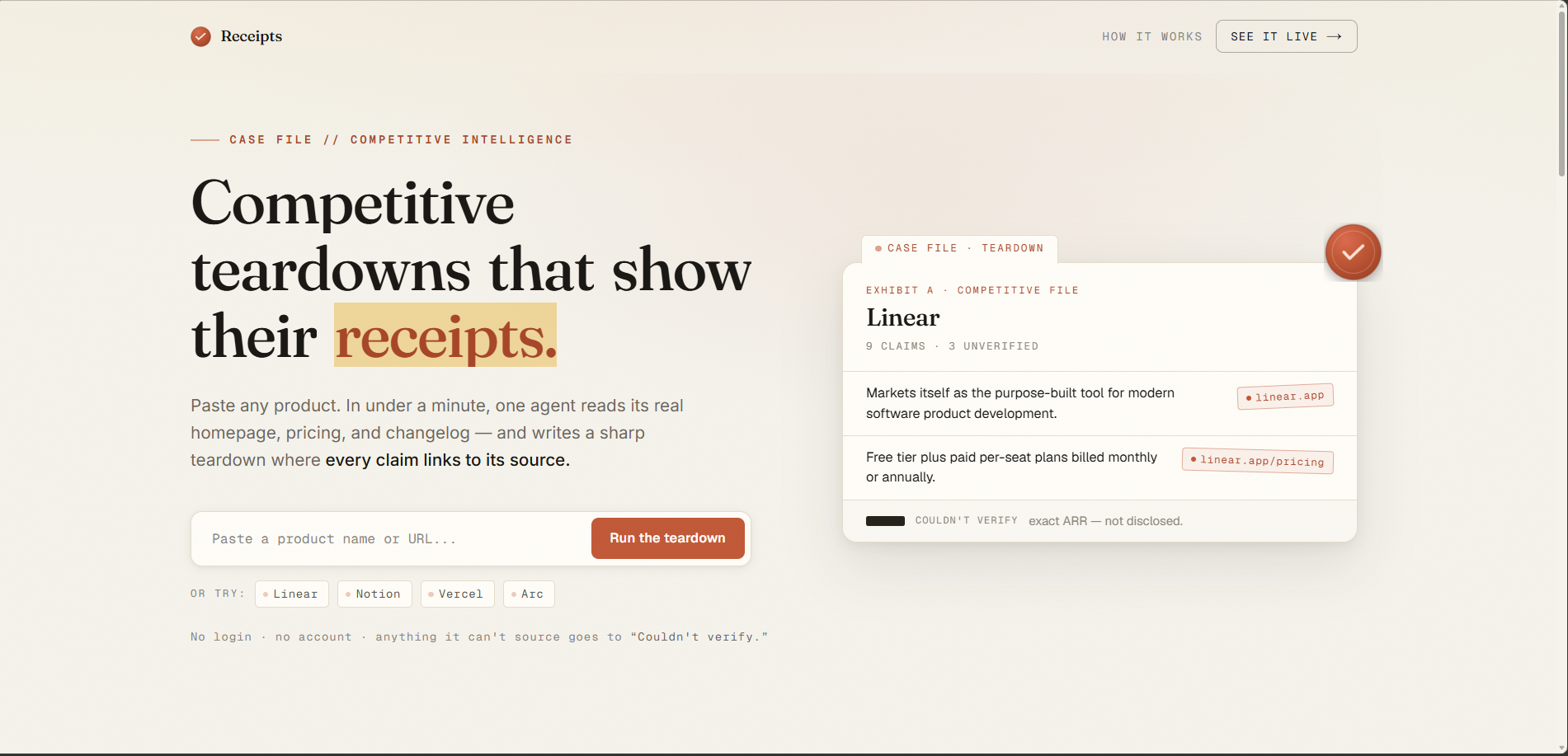
landing page
Inspiration Product managers have quietly stopped trusting AI for competitive analysis, and they say so plainly. One on r/ProductManagement called AI teardowns "confabulated fairy tales… certainty we don't really have." Another fed ChatGPT the actual release notes and still got hallucinations, then "went back to reading them all myself." The tool that promised to save time had turned them into its fact-checker. We wanted to build the opposite: an AI teardown you can trust, because it proves every word.
What it does Paste any product — a competitor, a hot startup, your own. In under a minute, one AI agent reads the product's real homepage, pricing page, changelog, and third-party reviews, then writes a sharp six-facet teardown — Positioning, ICP, Pricing, Recent moves, Strengths, Weaknesses — where every claim links to the exact source page it came from. Anything it can't back with a source isn't asserted; it goes into a visible "Couldn't verify" block. One rule governs everything: no source, no claim. No login, no account, free to use.
How we built it Next.js 16 (App Router) on Vercel, with one streaming API route over Server-Sent Events. A single server-side agent using a deliberately model-agnostic text protocol: the model replies one line at a time — SEARCH: or FETCH: — and the server runs the tool and streams results back. This sidesteps the native tool-call mis-formatting that open models hit on Groq. Two free models on Groq: Llama 3.3 70B gathers the evidence; GPT-OSS 120B writes the teardown. Jina (free, keyless) for web search and clean page reading. A cinematic "gathering evidence" loading state that streams the agent's real tool calls live, so you watch it read actual pages. Novus / Pendo Agent Analytics instruments every session — tool calls, models used, and goal completion. A "detective dossier" design system: receipt-stamp Exhibit chips, a wax-seal mark, and an amber highlighter that lands only on corroborated claims. 100% free AI stack, no credit card. Challenges we ran into Making the model admit uncertainty. LLMs would rather sound confident than say "I couldn't verify this." Enforcing no source, no claim took explicit prompt design and a hard rule that routes unsourced findings into the "Couldn't verify" block. Reliable fetching. JS-heavy and fetch-blocking sites make output target-dependent; we fall back to search snippets, lower the confidence badge, and still cite — never fabricate. Speed. 45 seconds feels fine; 90 feels broken. We trimmed round-trips and streamed progress so the wait reads as work being done. Polish under pressure. We caught and removed a smooth-scroll library that was capping page height and hiding the bottom of long teardowns — fixed before submission. Accomplishments that we're proud of A product whose entire thesis is honesty, that holds itself to the same bar — no fabricated metrics in our own pitch. The "Couldn't verify" block: the rare AI demo that brags about what it won't say. A coherent, hand-crafted design system that feels intentional, not template-generated. Genuinely free and instant — accessible to the solo and early-stage PMs that $15k–$30k/yr competitive-intelligence tools ignore. What we learned The future of useful AI isn't more confident output — it's more honest, grounded, citable output. Showing the gap is more valuable than filling it. And motion can be substance: making the agent's real searches and fetches visible is the product's core claim, made tangible.
What's next for Receipts Tracked competitors with diffs over time, scheduled re-runs, deeper third-party sourcing, and team sharing — every extension keeps the same rule: no source, no claim.
Built With
- framer-motion
- gpt-oss-120b
- groq
- jina
- llama-3.3-70b
- next.js
- pendo
- react
- server-sent-events
- tailwind-css
- typescript
- vercel
