-
-
Landing Page
-
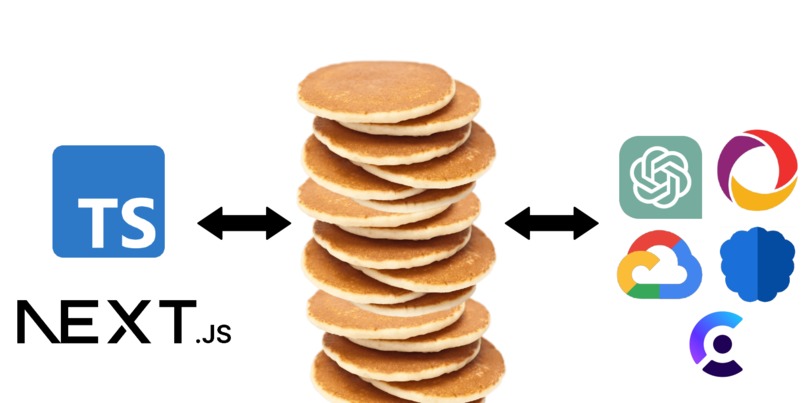
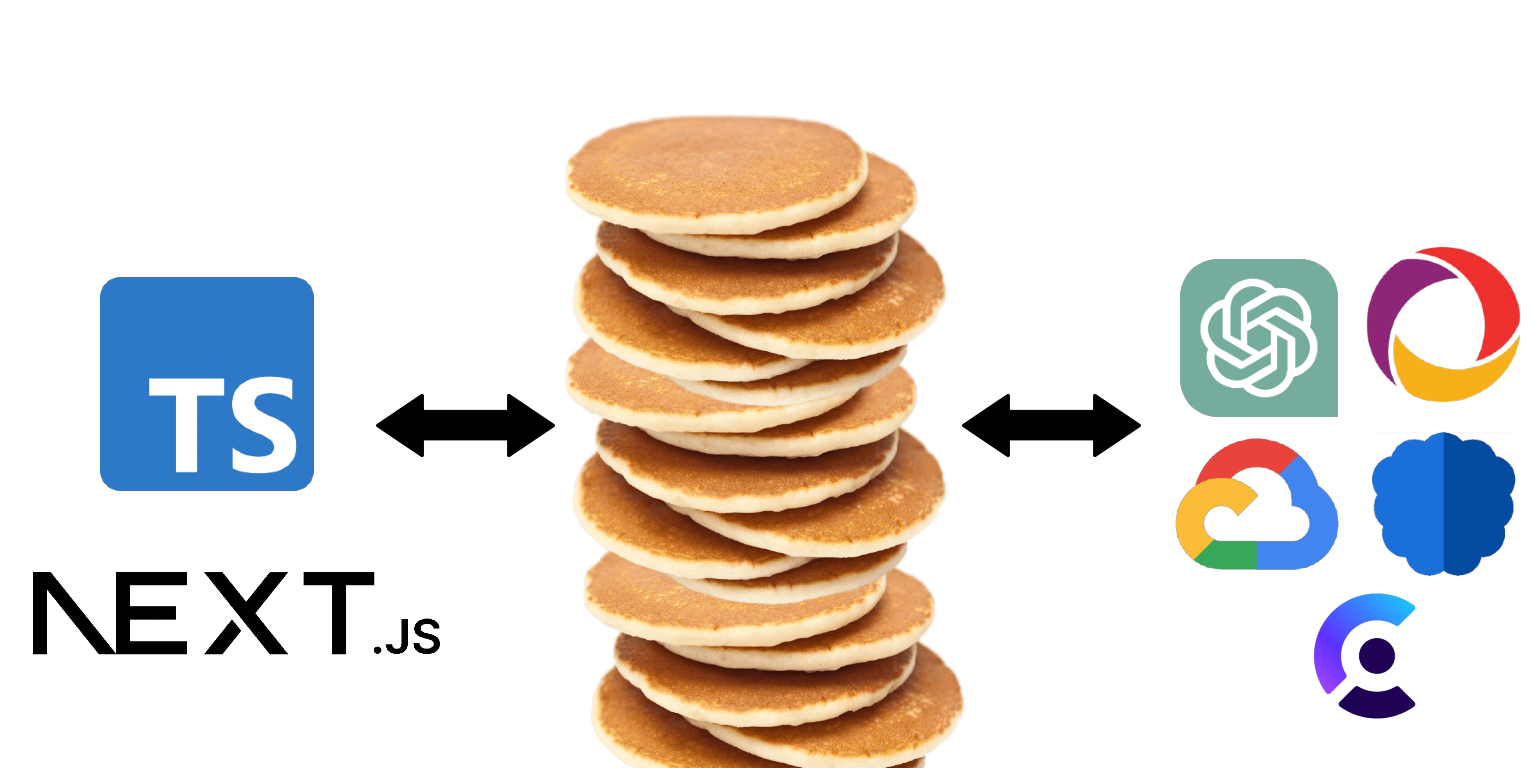
THE STACK (next13/ts frontend, clerk for auth, convex for crud + db, open ai api, google cloud text to speech, newsdata api)
-
Funnier Landing Page
-
Clerk Auth (thx Convex! <33)
-
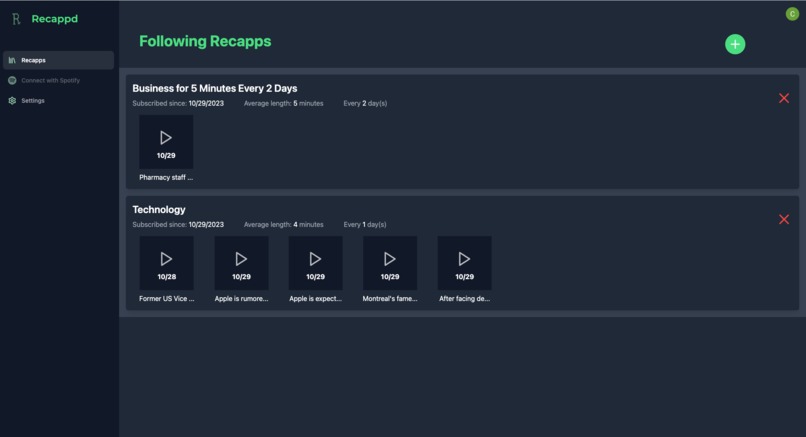
Main dashboard (this is where everything happens)
-

Step 1 to Create a new template to get podcasts -- pick your category
-
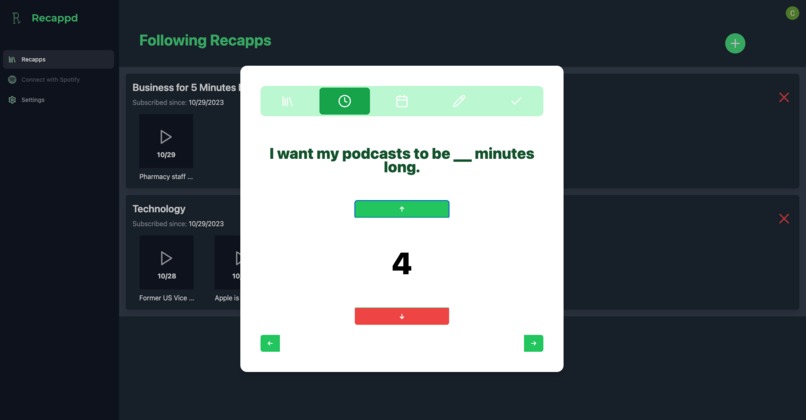
Step 2 -- pick your ideal podcast length
-
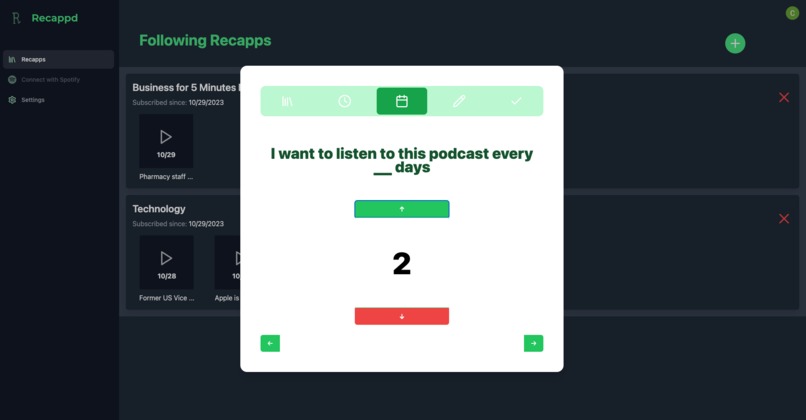
Step 3 - pick how frequently you want the database to create a new podcast
-
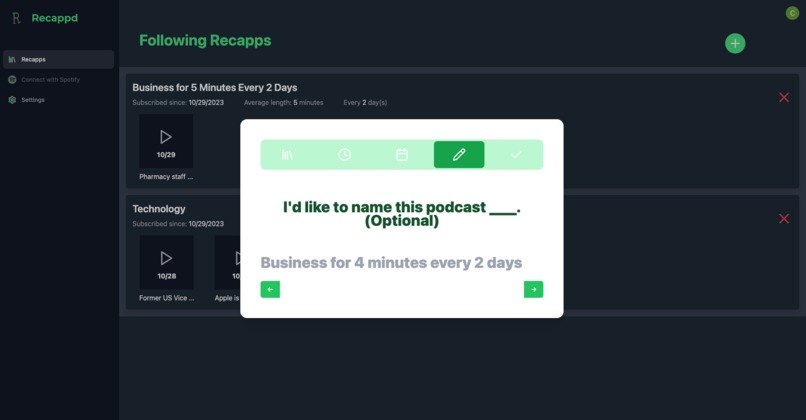
Step 3 - give it a fun name or use our default
-
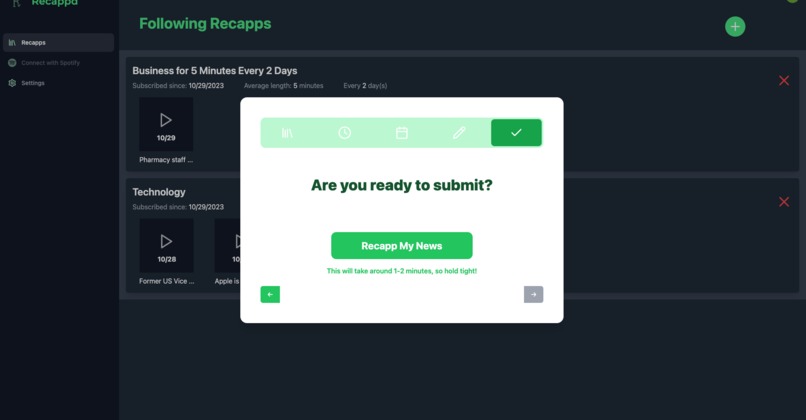
Step 5 - submit and watch the magic happen (did you notice i skipped step 4 :p)
-
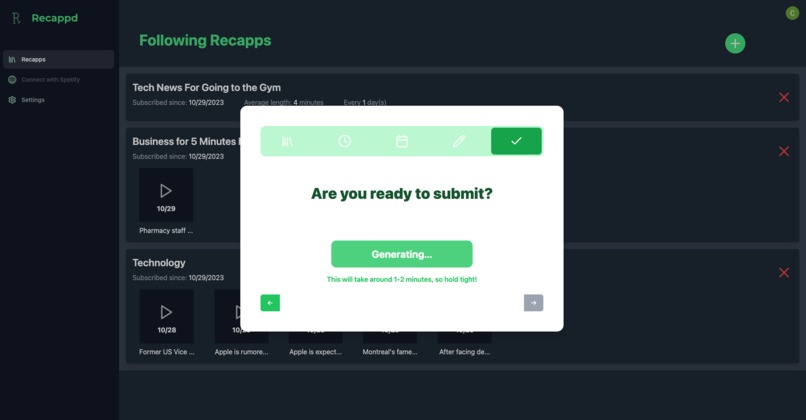
Generating ....
-
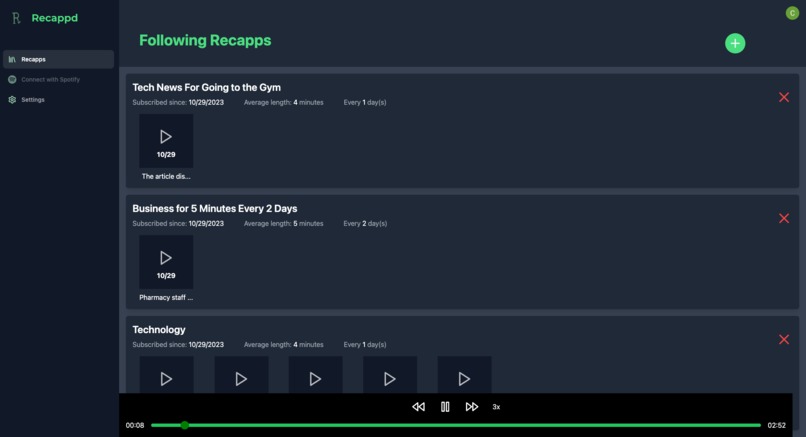
All generated! Just hit play, adjust the speed, etc. UI look familiar??
-
More auth stuff ... thanks clerk and convex x2
Inspiration
Deployed on Vercel **See the code
One of our teammates Cameron White is famous at our college, both for being busy, and for being a bit of a klutz. He's Grandmaster in League of Legends, has over 50k followers on Twitch, and is VERY often distracted by the latest in tech.
Although we all admire how passionately he lives his life, this passion does not come without cost. Cameron does not know who the governor of California is and was very recently shocked to learn that Leonardo Da Vinci had already died.
Poor Cameron!
With the rise of the internet, faster communication, and long-distance transportation, you would think that people would know more about each other than ever, but that's just not true. Just like our buddy Cameron, people all around the world don't know what's NEW (get it, like the NEWs??).
Recappd was designed to help people who struggle to find the time to keep up with the news. Real-time and powered by AI, Recappd allows users to create custom podcasts on the latest news that interests them, as frequently as they'd like, and as long as they'd like.
What it does
Recappd was designed to be intuitive. Just authenticate with Clerk using your Google or Github account, select a category of news that interests you (finance, tech, politics, etc), decide how long you want your podcasts to be, and how often you'd like to receive them, and that's it.
Recappd will take your interests, query the world wide web for the latest news in these categories using dynamic REST API endpoints, utilize LLMs to accurately identify the most important and consistent points from the aggregate of these articles, and spin up a report in the form of an mp3 audiofile, saved in real-time on our Convex database.
We've connected with cron workers via Convex to asynchronously schedule tasks and update your databases at regularly scheduled interviews, and allowed for full CRUD capabilities with Convex.
How we built it
We used NextJS 13's app router for the frontend with Typescript. For the styling, we used TailwindCSS, shadCN, and HeadlessUI. For authentication, we used Clerk, although it was largelyintegrated with Convex already. For the backend, we used Convex for our real-time database, including file storage and asynchronous, scheduled tasks via cron jobs. For the speech-to-text functionality, we used Google Cloud Platform. For the AI component, we used Open AI's GPT 3.5 model via their API. To get popular news sites, we used Newsdata's public API.
Challenges we ran into
Technically, utilizing any of the technologies offered at this hackathon proved to be quite difficult considering that we were working with audio files. As it turns out, it is rather challenging to upload audio files into databases, and even more troublesome to try and process and parse them. It took us many an hour at the Convex booth to figure out how we could get the audio files stored in our database for use later, which was a core functionality of the project. At the end of the day, it didn't actually end up being a challenging bytes/bits issue that we initially thought -- just a mismatch between the specific types of audio files used by Google and Convex. I could not give a bigger shoutout to the Convex team if I tried. They saved this project many times over.
Another challenge we ran into was the input and output limits for both GPT 3.5 and Google Cloud Platform's Speech to Text API. There is a very thin rope to walk between trying to ambitiously grab too much data and have way too much output to reasonably convert and store into an mp3 audiofile, and having way too little input, resulting in podcasts that are either missing information or much shorter than they needed to be. We solved this by utilizing our own chunking solution, which JUST barely managed to keep us under the limit for ChatGPT to give us an output that would fit within both our information and time constraints.
Another massive technical challenge was trying to upload our mp3's onto Youtube. Ffmpeg, the most popular library for converting mp3s to mp4s, was severely lacking in configuration information for Next JS and Typescript, and many other options online weren't APIs at all and required you manually insert them. No doubt this was a result of the difficulty of storing audio files in databases and the relative lack of utility for doing so in most other cases.
Finally, likely the biggest challenge was not even a technical one. Wifi at this hackathon was extremely slow -- to the point that Cameron and Roy had to pivot out a few hours in due to their models not being able to train themselves with the limited internet capacities at the venue.
Accomplishments that we're proud of
Undeniably the most impressive part about the project is our integration with Google Cloud Platform's Speech to Text API and Convex's real-time database. It took almost six hours of us swaying between believing it was possible and impossible, and it took another few hours for us to actually get to the concrete implementation. Thankfully, as a result, we can have audiofiles that are generated AND read by the client faster than it would have taken to read them outloud -- thanks to Convex's real-time database.
We're also quite proud of our frontend and the styling. Though we didn't quite have the time to build out a fully responsive frontend, the styling was quite the challenge, particularly given that none of us had any prior expertise in this sort of UI/UX design. The design went through a few iterations to get to the finished product, and we really did finish right in the nick of time.
I am also quite proud of our custom chunking system to allow ChatGPT to process these rather massive bits of data. By figuring out EXACTLY where our limit was in terms of GPT's inputs and carefully staying right below it, we're able to get the most accurate results possible from the model, with the least amount of hallucinations.
What we learned
As this was most of our members' first hackathon, it was really a great learning experience. It was very interesting to see that hackathons weren't as competitive as I made them out to be in my head and that it was oftentimes just a fun, collaborative place to be.
It was also a truly eye-opening experience into the startup world, what with co-founders and founding engineers representing all the impressive booths and sponsors. It was a great chance to get to talk to people who were living my dream.
What's next for Recappd
The one feature that I am quite regretful we didn't get to was integrating with an external API to host our audio files on. We started out hoping Spotify would have something, but they don't have a public API for something like that. As our choices grew smaller and smaller and our deadline continued to draw near, we decided to leave that as first up on our to-do list for the future.
Built With
- chatgpt
- convex
- gcp
- googlecloudplatform
- headless
- newsdata
- next
- openai
- shadcn
- tailwind








Log in or sign up for Devpost to join the conversation.