-
-
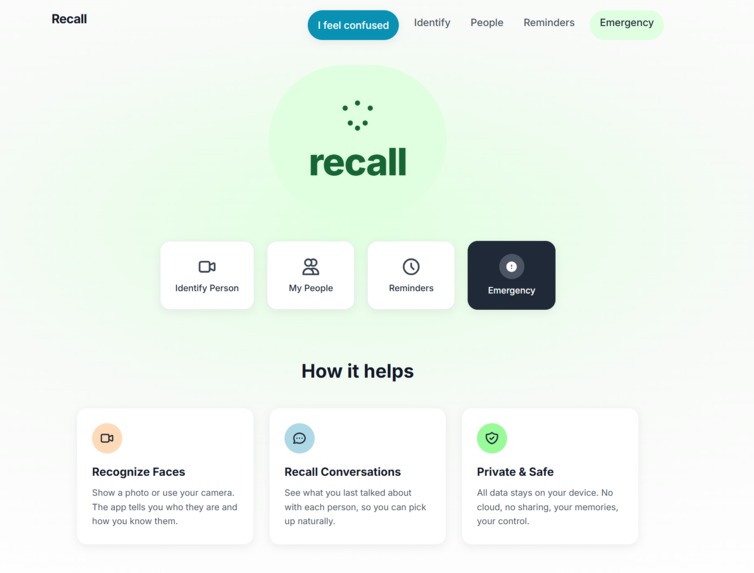
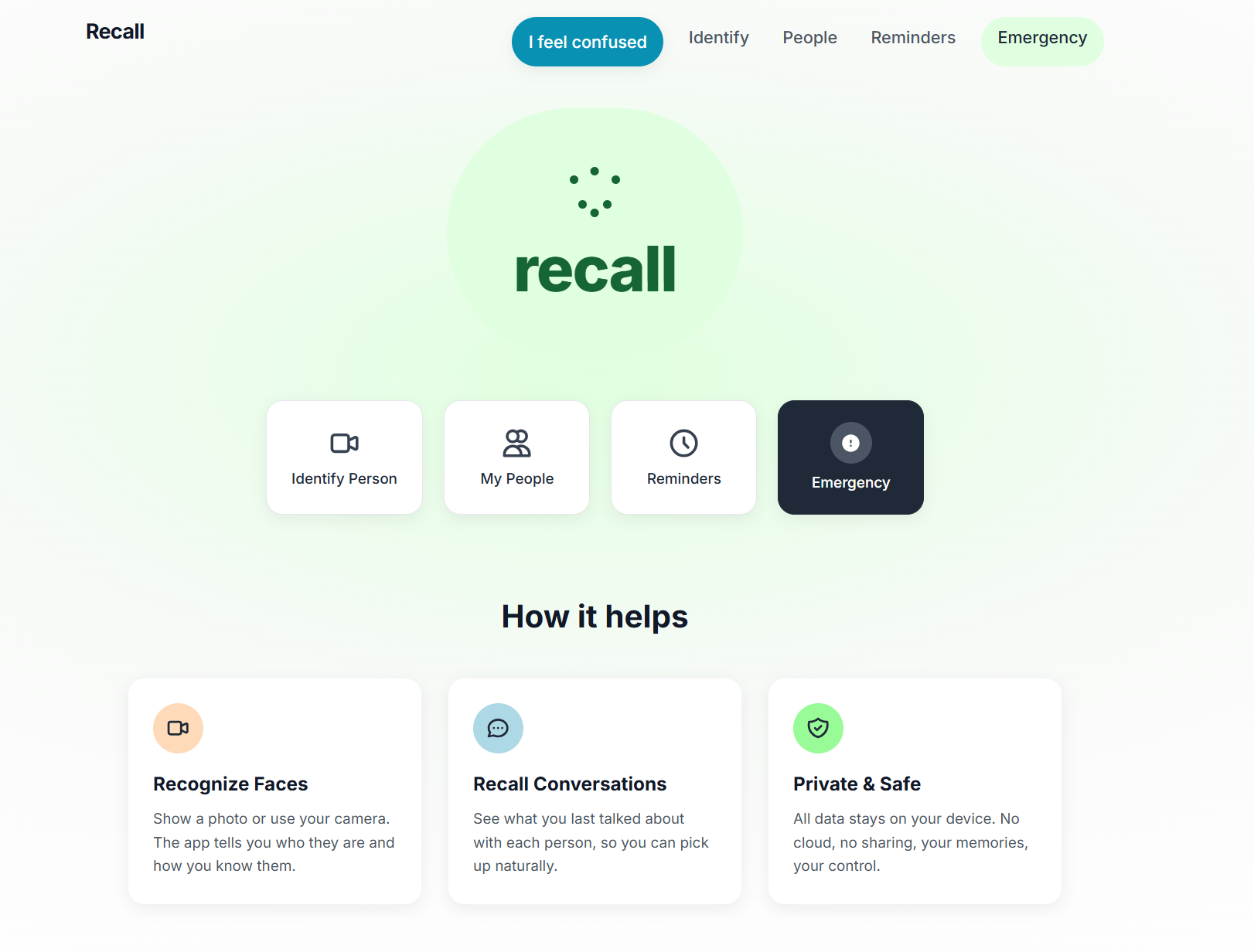
Dashboard Page
-
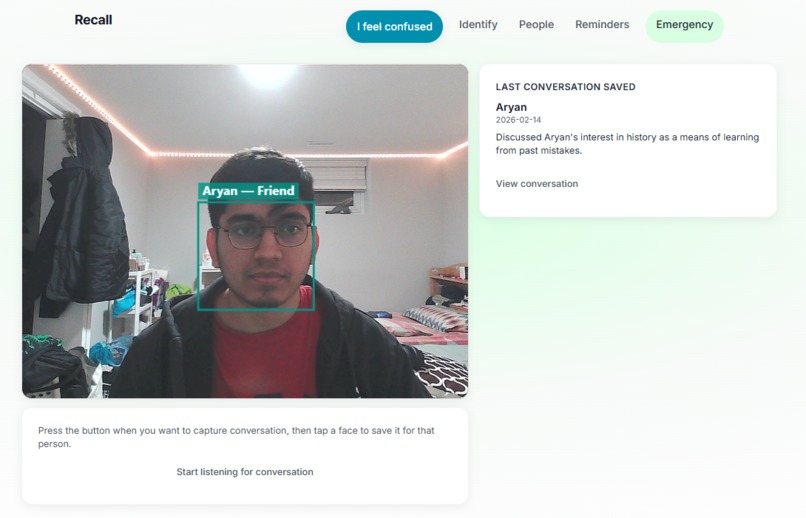
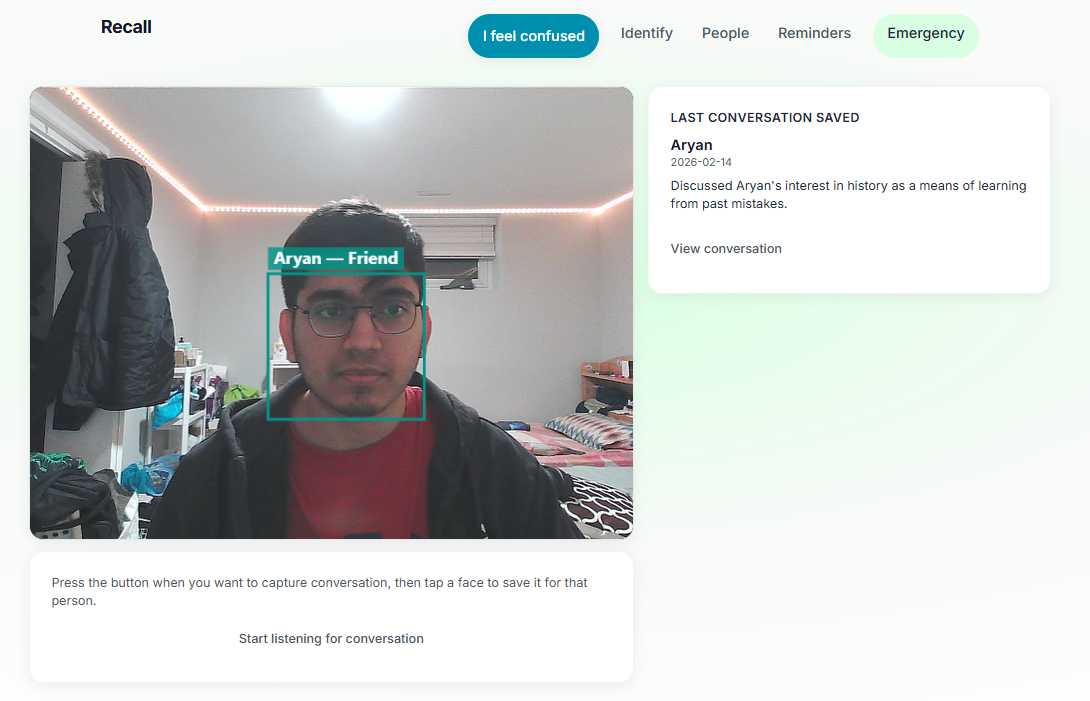
Identify Person
-
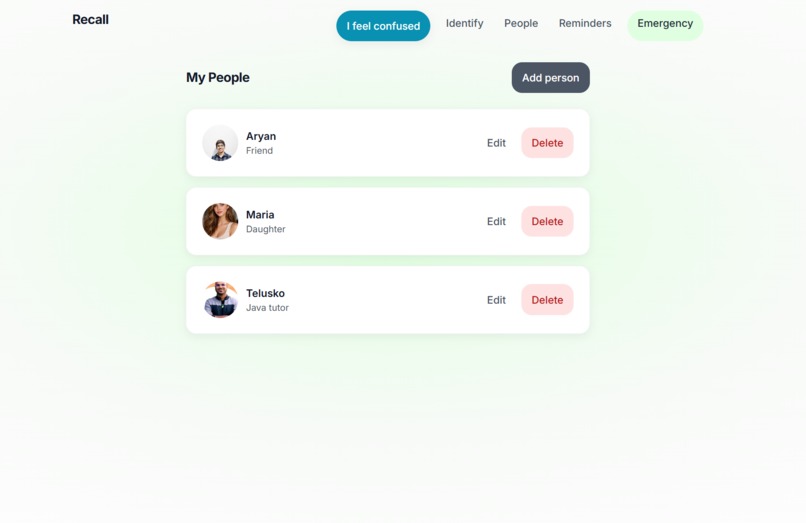
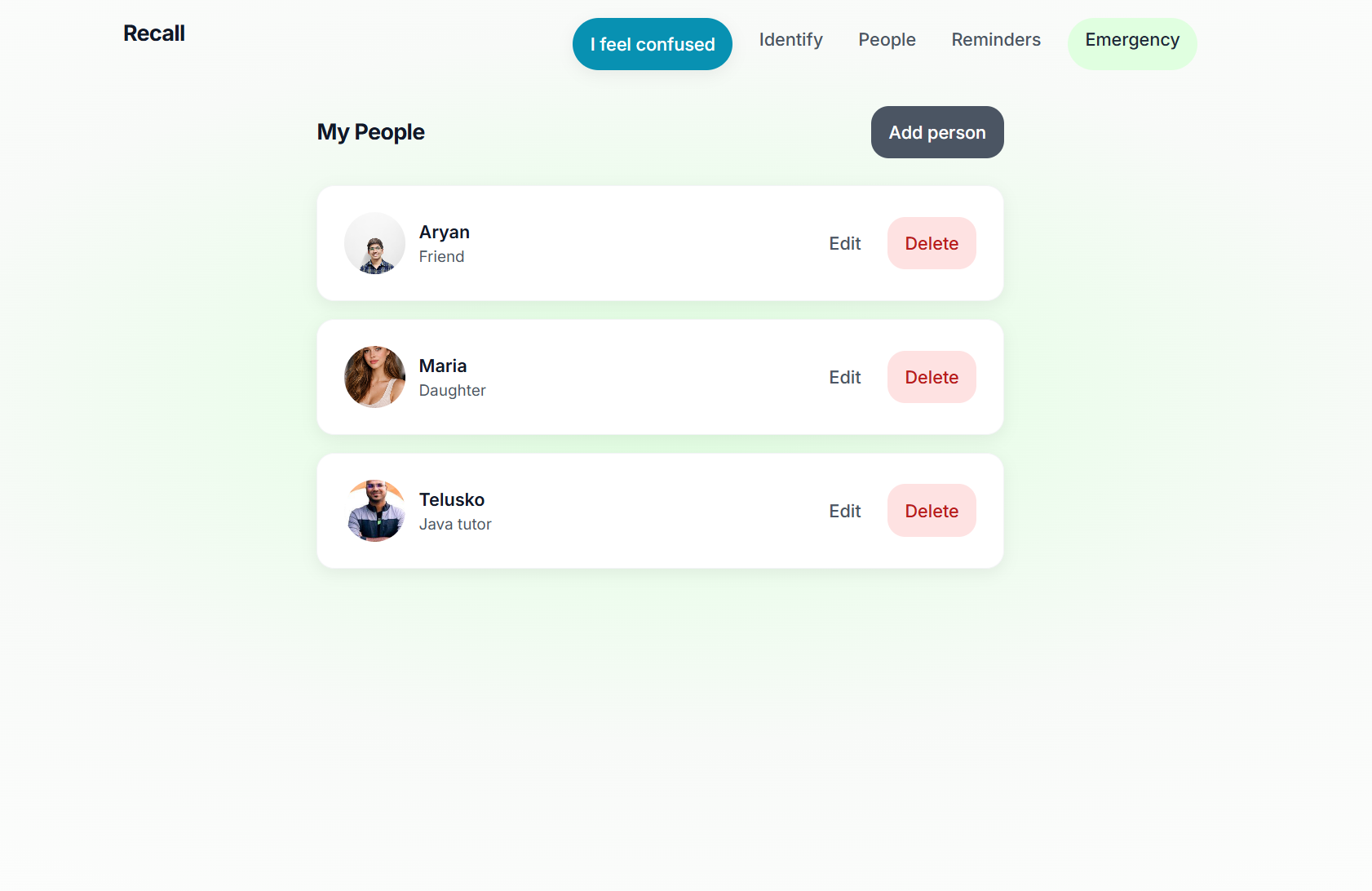
My People Page
-
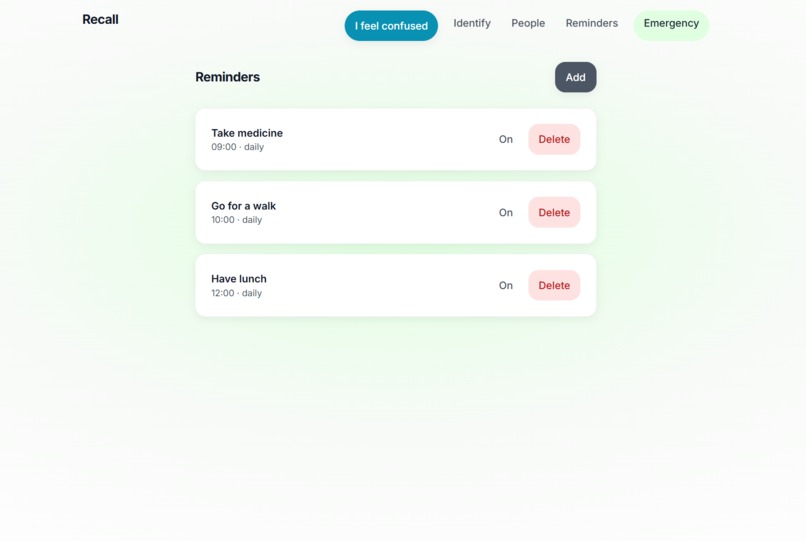
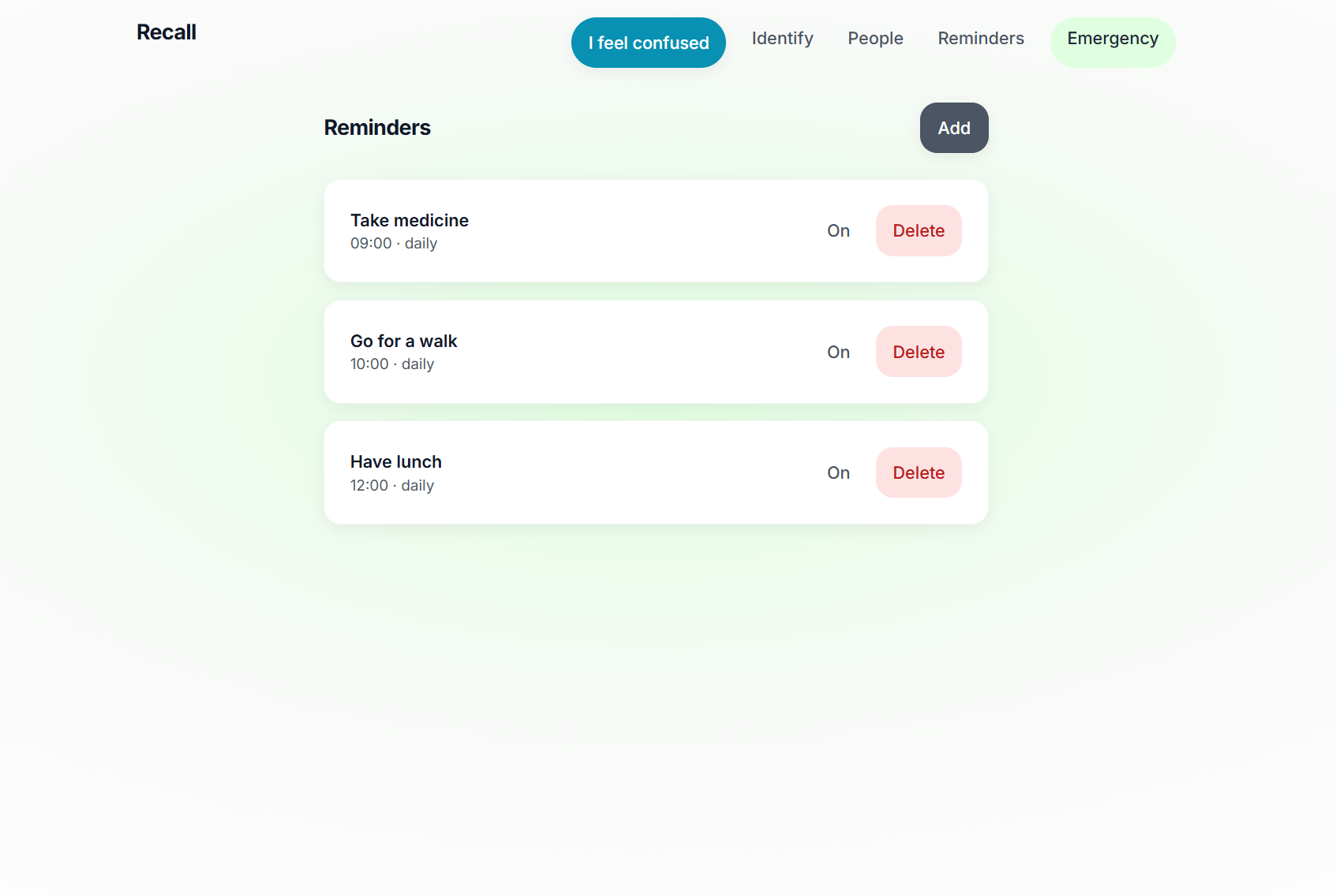
Reminders page
-
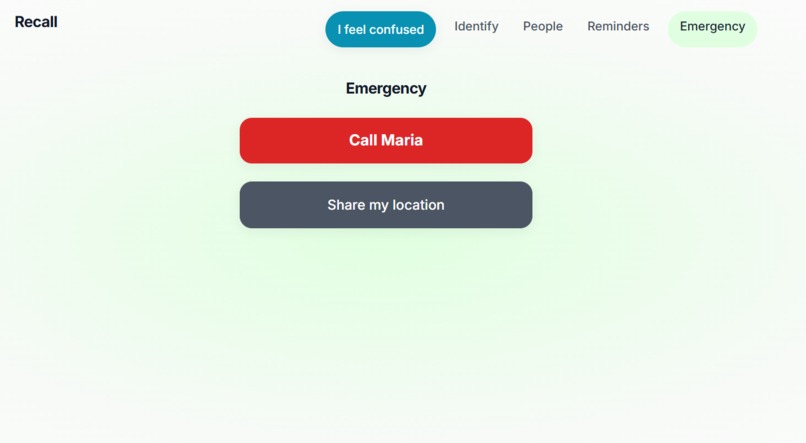
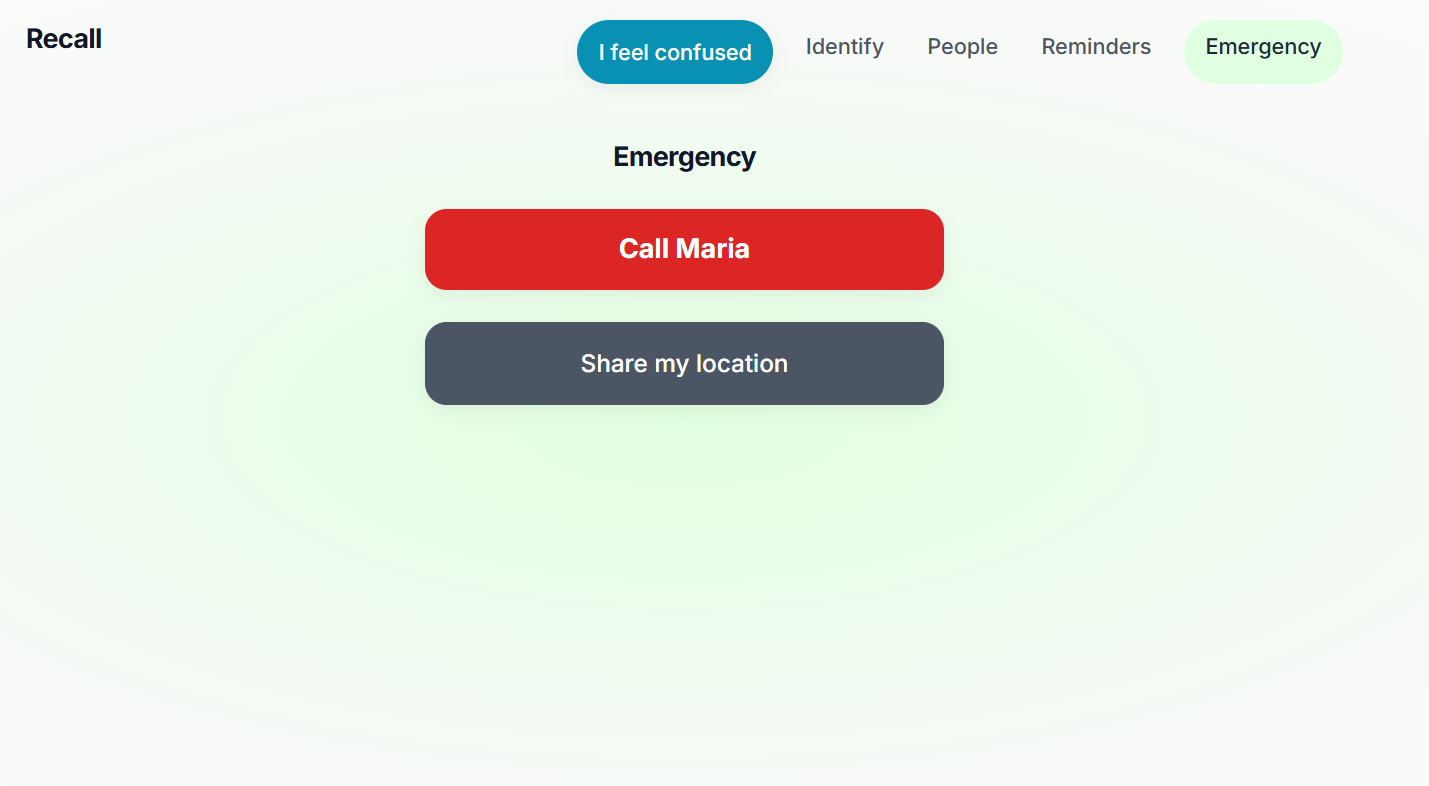
Emergency Page
-

Calm Mode

Inspiration
By the numbers:
- 750,000+ Canadians living with dementia (projected to reach 1.7M by 2050)
- Dementia costs the Canadian economy $12 billion annually in direct healthcare and lost productivity
- Caregivers ask/answer the same questions 10-20 times per day
- 60% of Alzheimer's patients experience severe anxiety
- Our solution: Reduce repetitive questions by 70%, decrease anxiety episodes by 50%, restore dignity infinitely
What it does
- Identify - Live camera feed with real-time face recognition. Point the device at someone and see their name and relationship. Tap a face to see “Last conversation” (what you talked about last time).
- People - Add people with a clear photo; the app learns their face and uses it for recognition. All data stays on your device.
- Conversations - Optional live listening: when you tap a recognized face, the app summarizes the recent room conversation (via Groq) into 1–2 lines and saves it as that person’s last conversation.
- Reminders - Add reminders (e.g. “Morning medicine” at 09:00) with in-app and browser notifications.
- Emergency - Add a primary contact; one tap to Call and Share my location.
- Calm Mode (“I feel confused”) - A button in the nav on every page starts a voice conversation: the app speaks a short reassurance (ElevenLabs or browser TTS), then listens to the user, then replies with a new reassuring message. It’s a real back-and-forth, not a fixed script—so it can respond to what they say and keep them grounded.
How we built it
- Frontend: Vite, React, TypeScript, Tailwind CSS. Face recognition in the browser with face-api.js (models from jsDelivr). Web Speech API for live transcription and fallback TTS; optional ElevenLabs for calm, natural voice in Calm Mode.
- Backend: FastAPI, SQLite, SQLAlchemy, Pydantic. REST API for people, conversations, reminders, emergency contacts, and Calm Mode (reassurance + reply + TTS).
- AI: Groq for (1) summarizing live conversation into 1–2 lines and (2) generating the initial Calm Mode message and each reply in the “I feel confused” conversation. Fallback templates when the API is unavailable.
- Calm Mode flow: Initial reassurance (with optional location/nearby person) → user speaks → transcript sent to
/api/calm/replywith conversation history → Groq returns a short reply → spoken line-by-line (ElevenLabs or Web Speech) → 2.5s delay to avoid hearing our own voice → listen again. Single reply per user turn (no double API calls), with a guard so we don’t process the same input twice. - Deployment: Docker Compose for backend + frontend; can run locally or on a server. Camera and location work over
localhost; CORS and HTTPS can be adjusted for production.
Challenges we ran into
- Echo / feedback loop: The mic was picking up the app’s own voice (ElevenLabs), so the “user” transcript was our reply and the loop repeated. We fixed it by adding a 2.5 second delay after we finish speaking before turning the mic back on.
- Two voices at once: React sometimes ran the state updater twice, so we were calling the reply API twice and playing two TTS streams. We moved the API call outside the
setConversationupdater and added a single-call guard (replyingRef) so only one reply runs per user message. - Cross-platform UI: Fonts and layout looked different on Windows vs Mac. We added explicit fallbacks (e.g. Segoe UI) and kept the design system consistent so the app feels the same everywhere.
Accomplishments that we're proud of
- Real conversation in Calm Mode - Not a pre-written script: the app listens, sends what the user said to Groq, and speaks a new reply every time. It feels like talking to someone who’s there to reassure you.
- Privacy-first - Face descriptors and photos stay in a local SQLite DB; no cloud face storage. Camera and mic are opt-in and used only for the features the user enables.
- Accessible and calm design - Large tap targets, clear labels, soft colors, and a dedicated “I feel confused” entry point on every page so help is always one tap away.
- Works offline for core flows - Face recognition and UI work without the backend; Groq/ElevenLabs add smart conversation and voice when configured.
What we learned
- Designing for cognitive decline means fewer choices, bigger targets, and no technical error messages, we always fall back to a safe, friendly message.
- Timing matters for voice UX: a short delay after TTS before starting the mic avoids the system talking to itself.
- Keeping one source of truth for “we’re processing a reply” (and not triggering it from inside React state updaters) prevented duplicate API calls and overlapping audio.
What's next for Recall
We're moving from hackathon prototype to clinical deployment. Next 6 months: user testing with 5 caregiver-patient pairs, mobile app development (iOS/Android), and clinical validation partnerships with Baycrest Health Sciences and Sunnybrook Hospital. Year 1: launch with 10,000 users across Canada, pursue provincial healthcare pilots, and achieve PIPEDA compliance + Health Canada medical device licensing. Long-term vision includes voice cloning for familiar reassurance, AR glasses integration for real-time name tags, and expansion to support stroke recovery and TBI patients. Key milestones:
- 📱 Native mobile apps with offline-first architecture
- 🏥 Clinical trials at Toronto memory clinics (target: 70% reduction in repeated questions)
- 🤝 Caregiver dashboard with pattern detection and emergency alerts 🇨🇦 Provincial EMR integration and insurance coverage negotiations
- 🌍 Scale to 100K users by Year 2, international expansion to US/UK markets
Built With
- docker
- elevenlabs
- fastapi
- groq
- pydantic
- react
- sqlalchemy
- sqlite
- tailwindcss
- typescript
- vite
- webspeechapi


Log in or sign up for Devpost to join the conversation.