-
-
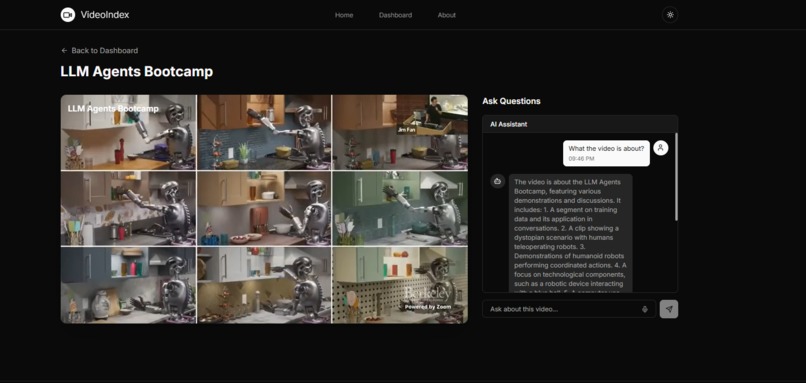
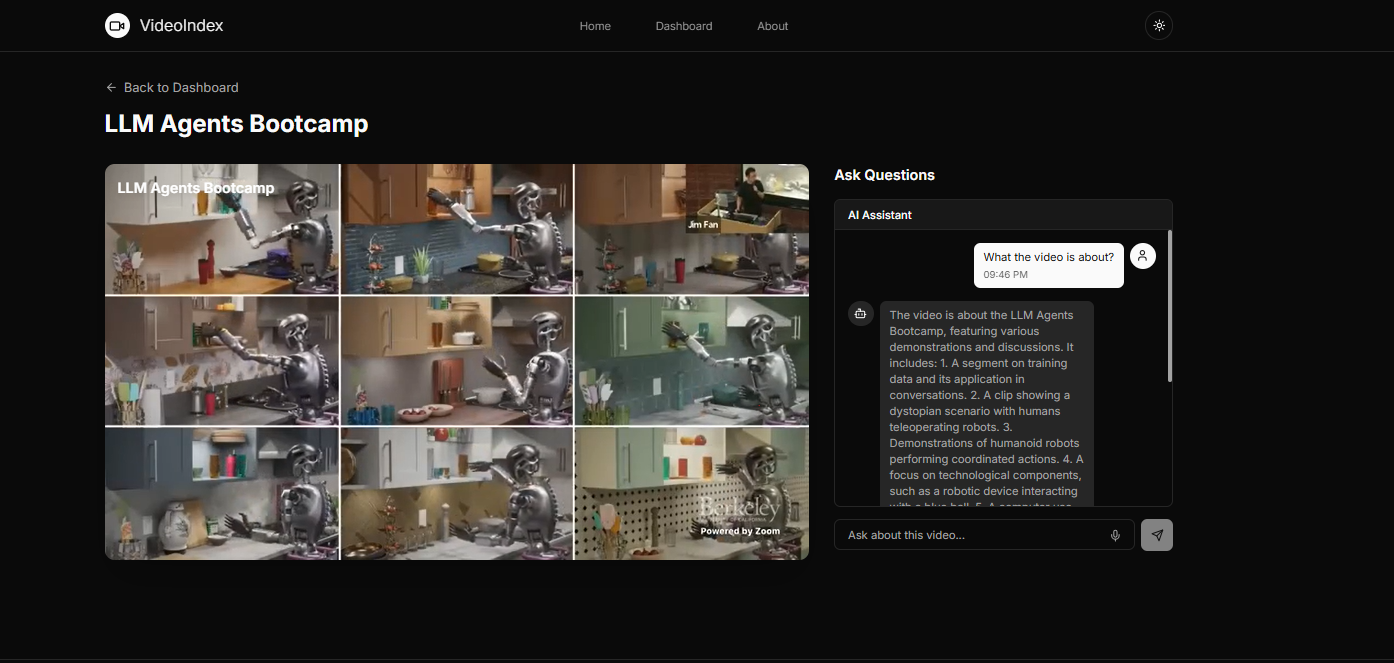
Chat Interface
-
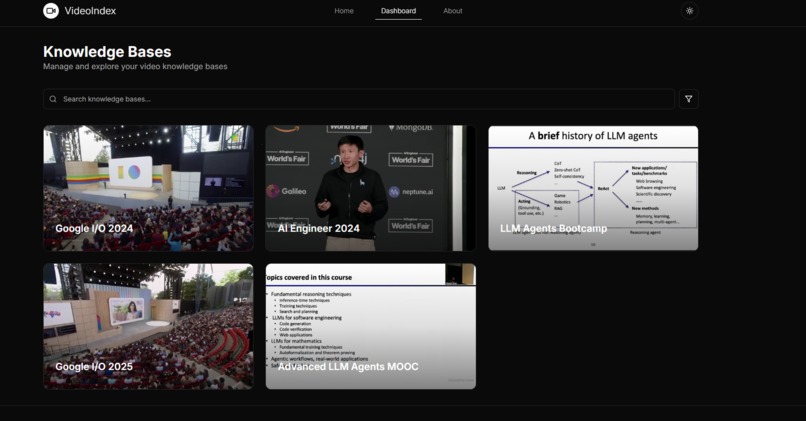
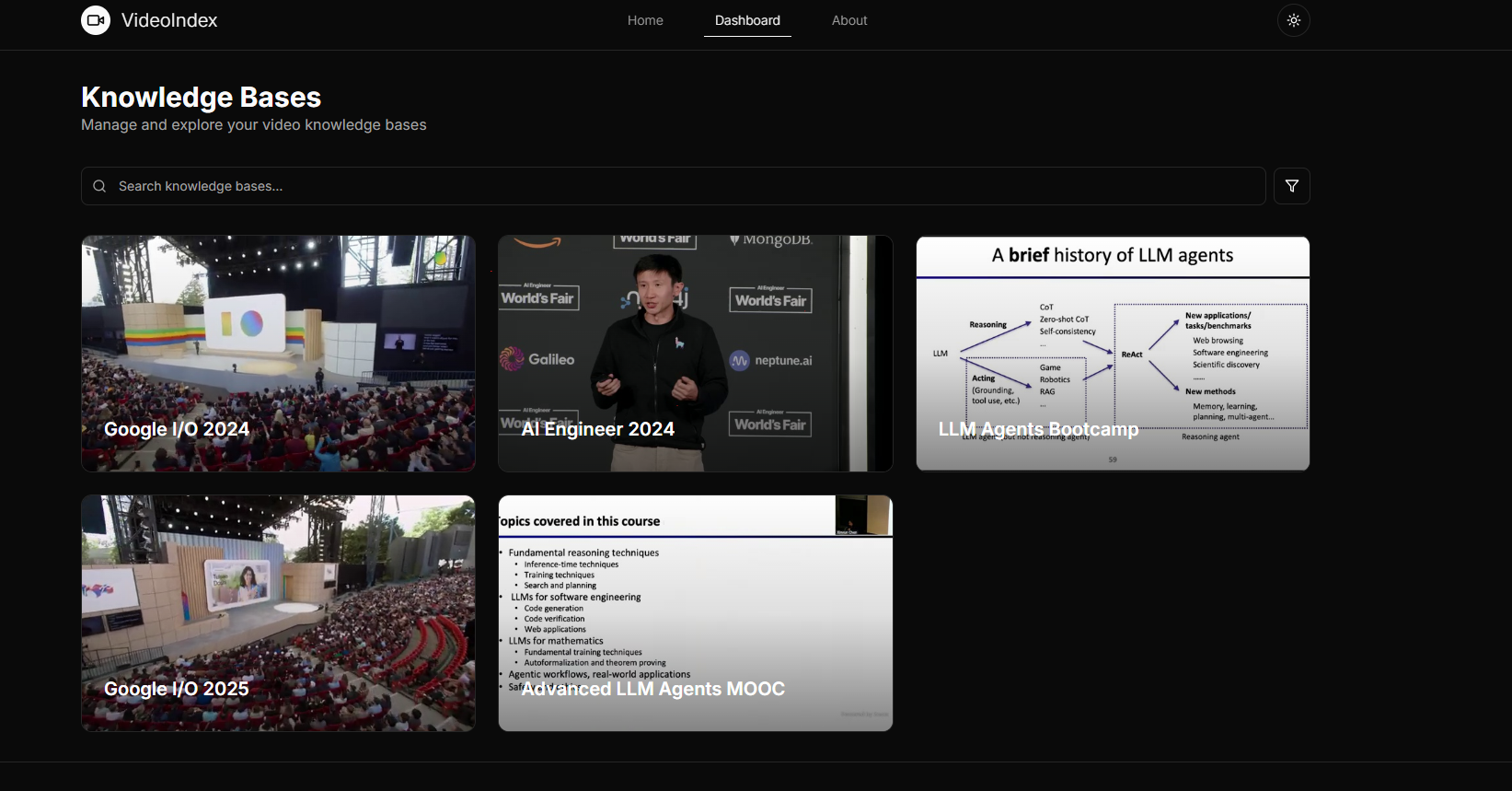
Dashboard
-
Homepage
My Journey Building a Video Indexing RAG System
The Spark of Inspiration
The idea for this project, a video indexing system that allows conversational interaction, was born out of a common frustration: passively consuming long video lectures or tech talks. While videos are incredibly rich sources of information, extracting specific details, getting quick summaries, or finding the exact moment a concept is discussed can be incredibly tedious. I envisioned a world where videos aren't just played, but chatted with. A system where you could ask a question and instantly get a concise answer, complete with the relevant video snippet and timestamp. This desire to transform passive viewing into active, intelligent learning was the core inspiration behind diving into Retrieval Augmented Generation (RAG) and building this interactive video indexing solution.
What I Learned Along the Way
This project was a deep dive into the practical applications of Large Language Models (LLMs) and the surrounding ecosystem. Here are some key learnings:
- The Power of RAG: I learned that RAG is a game-changer for grounding LLMs in specific, up-to-date, and factual knowledge. It mitigates hallucinations and allows LLMs to answer questions based on a private knowledge base, which is crucial for domain-specific applications like video indexing.
- Vector Databases are Essential: Understanding how embeddings transform text into numerical representations and how vector databases efficiently store and retrieve these embeddings based on semantic similarity was fundamental.
- FastAPI for Production-Ready APIs: FastAPI proved to be an incredibly efficient and robust framework for building asynchronous API endpoints, perfect for serving the RAG pipeline. Its speed and automatic documentation (Swagger UI) were invaluable.
- Nuances of Information Retrieval: It's not just about getting any information, but relevant and accurate information. This involved experimenting with chunking strategies, embedding models, and retrieval algorithms.
- The Importance of Metadata: Attaching crucial metadata like video timestamps and source video IDs to text chunks was critical for linking retrieved text back to the original video content.
How I Built the Project
The RAG Architecture
At the heart of the system is a RAG pipeline designed to bridge the gap between user queries and the vast amount of information contained within videos.
- Video Transcription: First, every video ingested into the system is automatically transcribed into text. This forms the raw data for our knowledge base.
- Text Chunking: The long transcriptions are then divided into smaller, manageable "chunks." The size of these chunks is a critical parameter, as it affects both retrieval accuracy and the LLM's ability to process the retrieved context. I experimented with various chunk sizes, aiming for chunks that were large enough to contain sufficient context but small enough to be highly relevant to a specific query.
- Embedding Generation: Each text chunk is then converted into a numerical vector (an embedding) using a pre-trained embedding model. These embeddings capture the semantic meaning of the text.
- Vector Database Storage: These embeddings, along with their associated metadata (original text, video ID, start timestamp, end timestamp), are stored in a vector database. This database allows for very fast similarity searches.
- Retrieval: When a user asks a question, the question itself is first converted into an embedding. This query embedding is then used to perform a similarity search in the vector database, retrieving the top 'N' most semantically similar text chunks from the video transcripts.
- Augmentation: The retrieved text chunks are then combined with the user's original query to form a new, augmented prompt.
- Generation: This augmented prompt is fed into a powerful LLM (like Gemini 2.5 Pro). The LLM then generates a concise and accurate answer, grounded in the retrieved context.
Creating FastAPI Endpoints
FastAPI was chosen for its performance and ease of use in building robust APIs. I created several key endpoints:
/query: This was the primary endpoint for handling user questions. It accepts a text query (or a voice input that is then transcribed to text).- Input:
{"query": "What was demoed in Gemini 2.5 Pro?"} - Process:
- Embed the user query.
- Perform a vector search to retrieve relevant text chunks and their metadata (including
video_id,start_timestamp,end_timestamp). - Construct the augmented prompt for the LLM.
- Call the LLM to generate the answer.
- Format the response to include the text answer, relevant video ID, and timestamp.
- Output:
{"answer": "...", "video_id": "...", "start_time": "...", "end_time": "..."}
- Input:
Accuracy of Retrieving Information from the Knowledge Base
The accuracy of retrieval was paramount. An LLM, no matter how powerful, can only generate good answers if it receives good context. My focus was on:
- Embedding Model Selection: Choosing a high-quality embedding model that accurately captures semantic meaning was crucial. I experimented with various models, evaluating their performance on domain-specific text.
- Chunking Strategy: This was an iterative process. Too small, and context is lost; too large, and irrelevant information dilutes the signal. I found that a balance, often around 200-500 tokens per chunk with some overlap, worked best for video transcripts. This ensured that a single chunk often contained enough information to answer a specific question.
- Top-K Retrieval: Determining the optimal number of top-K (most similar) chunks to retrieve was also important. Retrieving too few might miss relevant information, while retrieving too many could introduce noise and increase LLM inference costs.
Improving the Retrieved Information
Beyond initial retrieval, I implemented strategies to refine the information passed to the LLM:
- Re-ranking: After initial retrieval, I explored re-ranking the retrieved chunks. This involved using a smaller, more specialized model or even the main LLM itself to score the relevance of the retrieved chunks to the query, ensuring the most pertinent information was at the top.
- Contextual Compression: In some cases, even relevant chunks might contain extraneous information. Techniques like
LLMChainExtractor(from LangChain, for example) can be used to extract only the most relevant sentences or phrases from the retrieved chunks before passing them to the final LLM. - Handling Ambiguity: For ambiguous queries, the system was designed to potentially retrieve multiple relevant snippets and present them, or even ask clarifying questions to the user.
Retrieving Relevant Timestamp Video and Text
This was a critical feature for the "chat with video" experience. The solution involved:
- Metadata Association: During the initial processing (transcription, chunking, embedding), I meticulously stored the
start_timestampandend_timestampfor each text chunk. This meant that when a chunk was retrieved, its corresponding video segment information was immediately available. - Mapping to Video Player: The FastAPI endpoint's response included these timestamps. On the front-end (not part of this specific prompt, but conceptually), a video player would then use these timestamps to jump directly to the relevant part of the video, providing a seamless user experience.
- Highlighting Text: The retrieved text snippets were also highlighted or presented alongside the video, reinforcing the connection between the generated answer and its source in the video.
Challenges Faced
Building this system wasn't without its hurdles:
- Transcription Accuracy: Initial transcriptions, especially for technical talks or videos with poor audio quality, could have errors. This directly impacted the quality of embeddings and subsequent retrieval. I addressed this by exploring different transcription services and considering post-processing steps for error correction.
- Optimal Chunking: As mentioned, finding the "just right" chunk size and overlap was an iterative challenge. It required extensive testing and evaluation to balance context preservation with retrieval precision.
- Embedding Model Performance: While general-purpose embedding models are good, finding or fine-tuning a model specifically for video transcript content (which can be very conversational and domain-specific) could further boost performance. This was a potential area for future improvement.
- Latency: Combining retrieval and generation steps can introduce latency. Optimizing the vector database queries, choosing efficient LLMs, and implementing asynchronous processing in FastAPI were key to keeping response times low.
- Scalability: Handling a large volume of videos and concurrent user queries required careful consideration of infrastructure and database choices. While the prototype worked well, scaling to millions of videos would necessitate distributed systems and more robust database solutions.
- "Grounding" the LLM: Despite RAG, LLMs can sometimes still "drift" or introduce minor inaccuracies. Continuously refining the prompt engineering and possibly adding a final "fact-checking" layer (though not implemented in this version) was a constant thought.
Overall, this project was an incredibly rewarding experience, demonstrating the practical power of RAG to unlock the knowledge hidden within video content and create truly interactive learning experiences.
Built With
- bolt
- fastapi
- python
- rag
- vite




Log in or sign up for Devpost to join the conversation.