-
-

ESP32 with Video Streaming (Left)
-

ESP32 with Audio Streaming (Right)
-

Audio Transcription
-
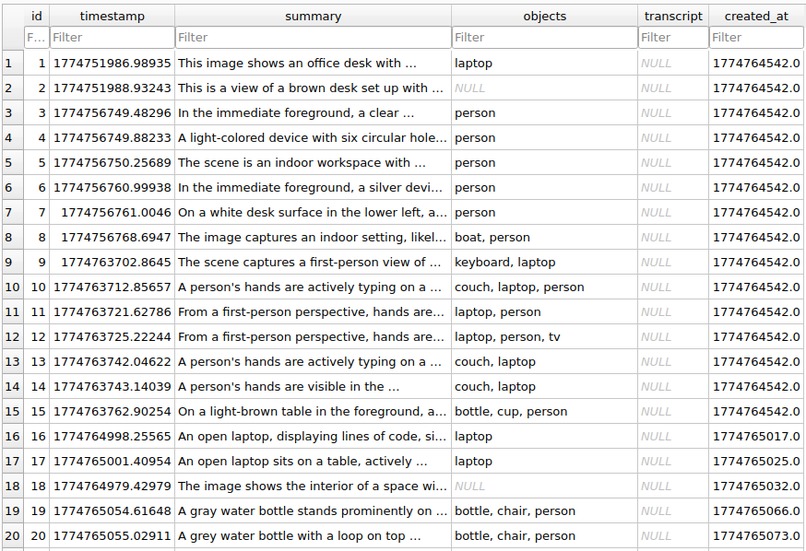
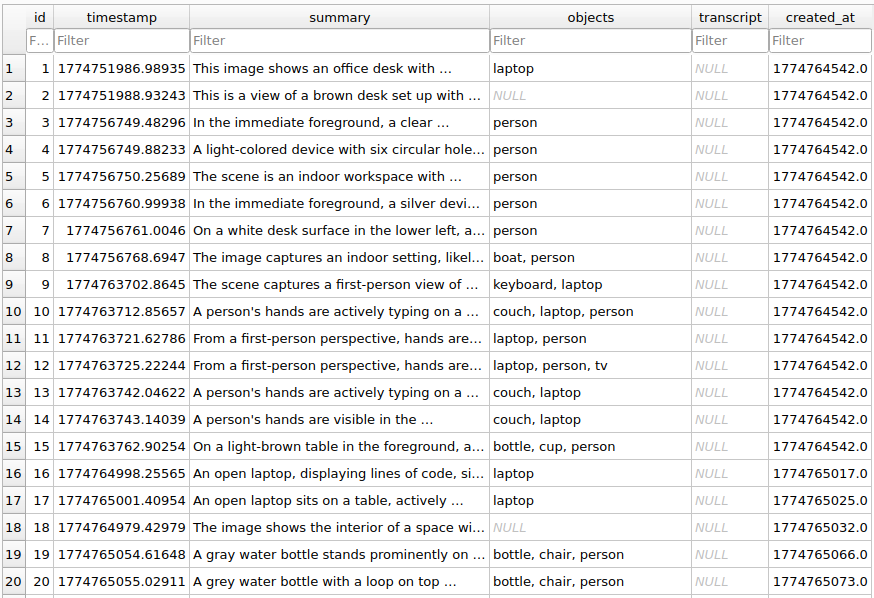
SQLite Database
-
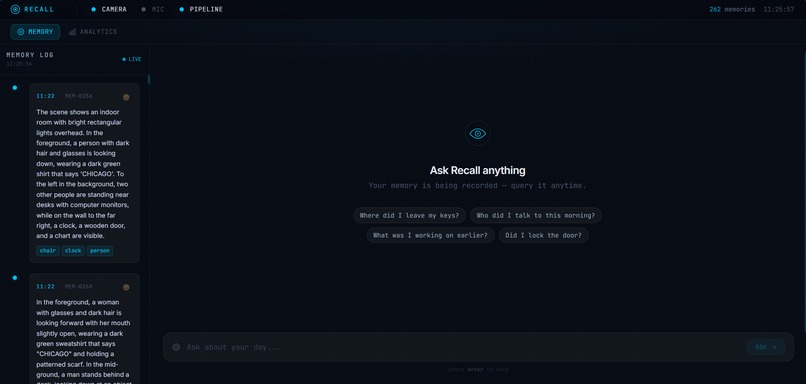
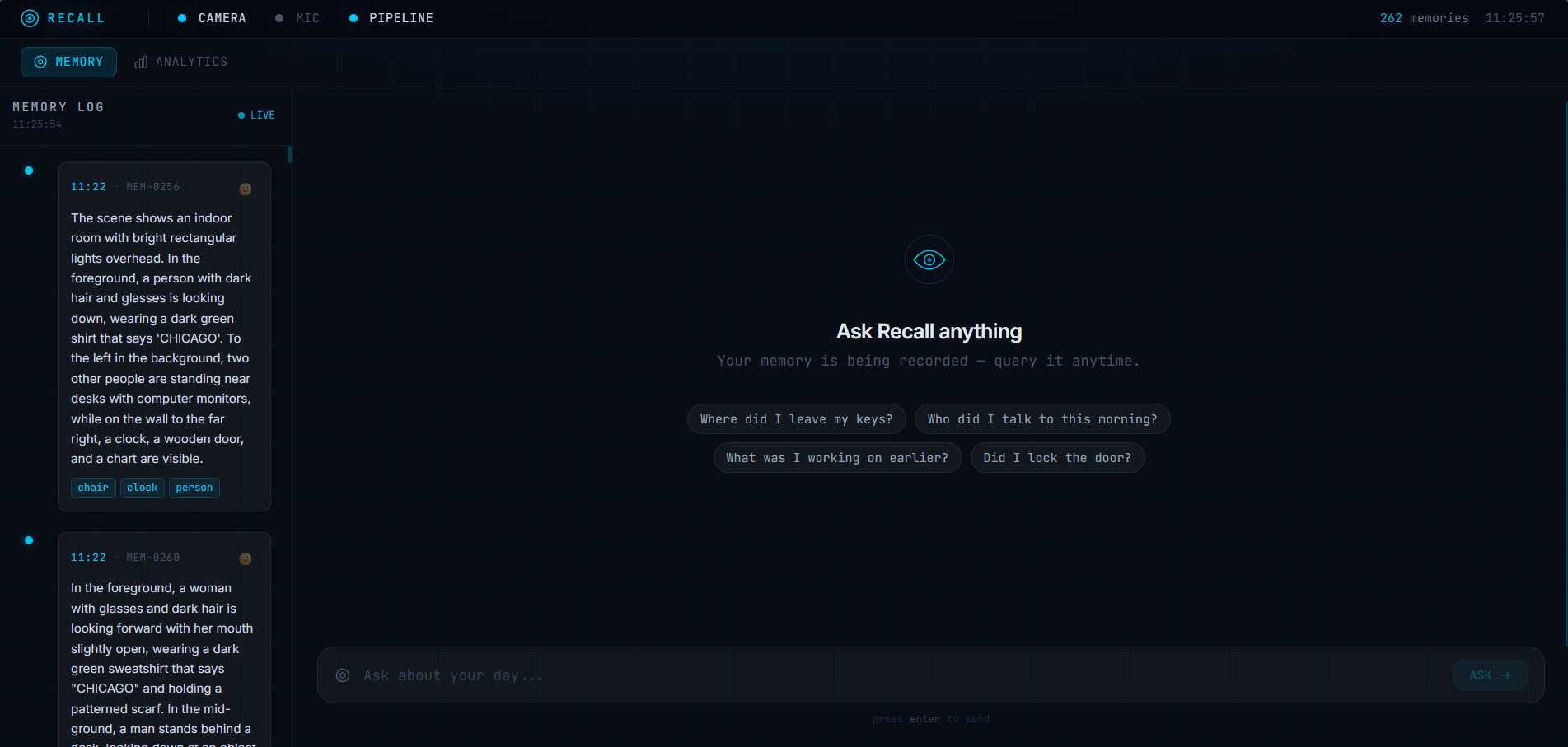
Dashboard
-
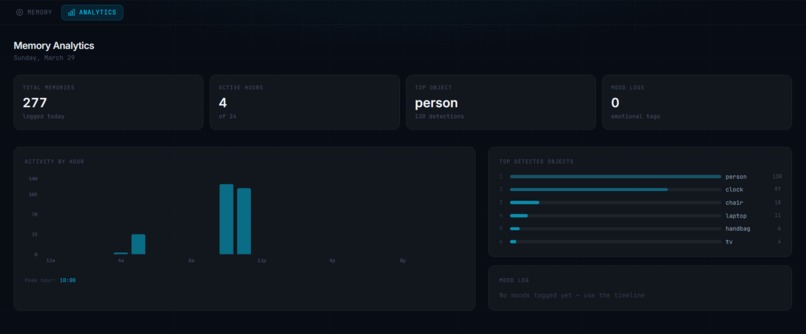
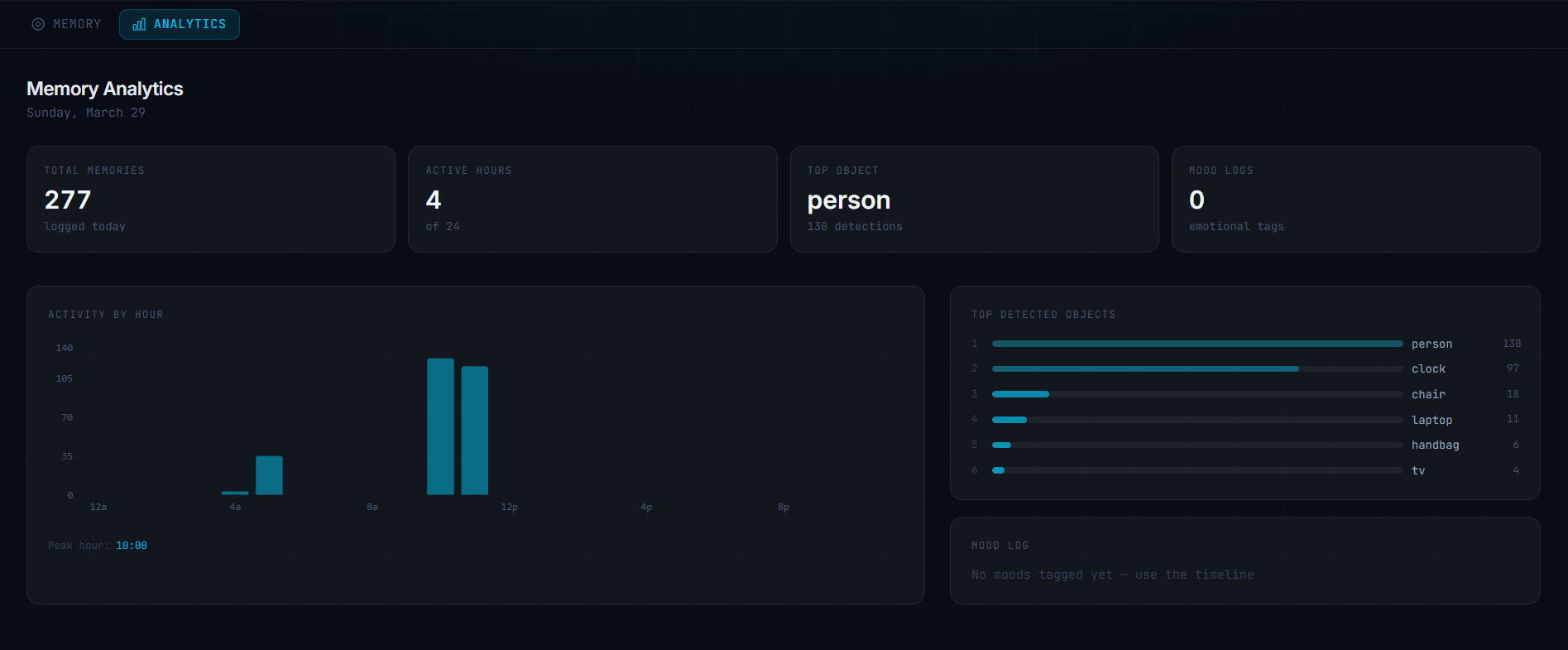
Memory Analytics
-
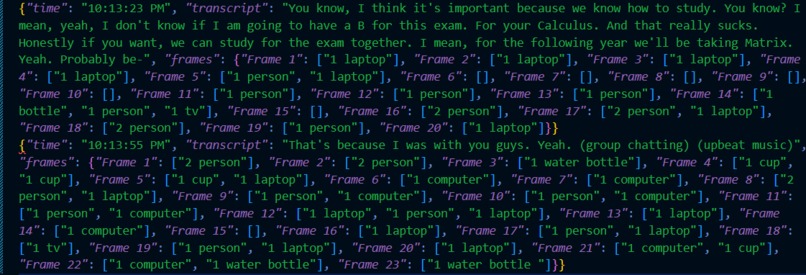
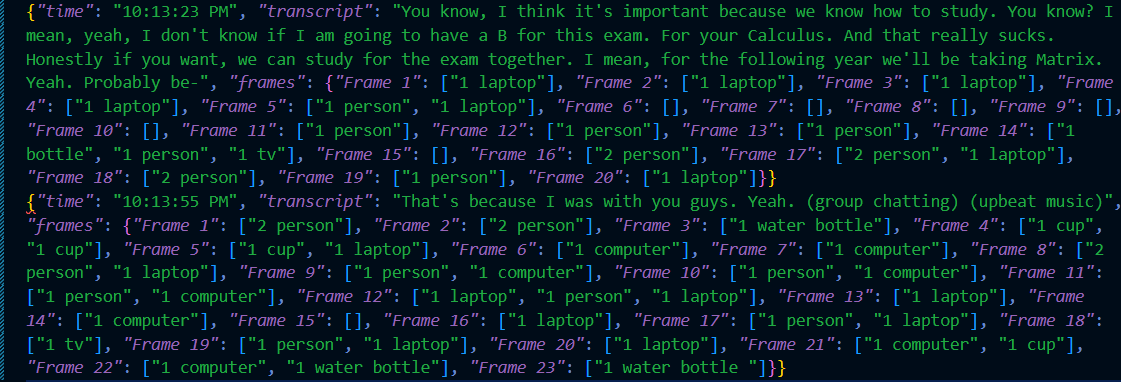
Gemini Speech Transcript



Inspiration
For the 55 million people worldwide experiencing cognitive impairment, along with millions more recovering from traumatic brain injuries, simple tasks can be daunting. Remembering where they left their keys, whether they locked the door, or what they were doing five minutes ago can mean the difference between living independently and relying on others. We wanted to restore that autonomy by building a passive, always-on memory assistant that watches, listens, and remembers on their behalf.
What it does
Recall is an AI-powered memory assistant integrated into a pair of glasses. It constantly captures the user's visual and audio environment, smartly curates important moments, and saves them as searchable memories. Users can ask natural language questions ("Where did I leave my keys?", "Did I lock the door?", "Who did I talk to this morning?") and receive specific, timestamped audio responses.
The system features:
- Continuous passive capture: Streams video and audio directly from the glasses-mounted hardware.
- Intelligent scene understanding: Pairs real-time object detection (YOLOv8) with Gemini Vision to create detailed spatial descriptions, such as "keys on the kitchen counter next to the toaster."
- Semantic memory search: Uses ChromaDB vector embeddings so users can search their memories by meaning instead of just exact keywords.
- Conversational interface: Provides a chat interface with voice feedback powered by ElevenLabs TTS.
- Mood tracking: Allows users to tag memories with their emotions and view analytical trends over time.
- Live dashboard: Displays real-time hardware status, a scrollable timeline of memories, and analytics showcasing activity patterns and detected objects.
How we built it
Hardware
We mounted two ESP32 microcontrollers onto the frames of the glasses:
- ESP32-S3: Equipped with an OV2640 camera module, this streams MJPEG video at VGA resolution over WiFi using a custom multi-endpoint HTTP server (
/stream,/frame,/status). - ESP32-WROOM-32E: Paired with an INMP441 I2S MEMS microphone, this captures 16kHz mono audio and streams raw PCM data via a TCP socket.
Both microcontrollers connect to the same WiFi network as the laptop managing the processing pipeline. This project marked our first foray into hardware; we went from having zero embedded systems experience to creating a fully functional wearable streaming device.
Software
Backend (Python): A single-process architecture using threads for concurrency. The pipeline flows:
- Frames buffer in batches of 40 before YOLOv8 Nano performs batch object detection, selecting the most relevant frames based on detection density.
- These chosen frames are sent to Gemini 2.5 Flash Vision to generate rich scene descriptions, which are then stored in SQLite alongside ChromaDB vector embeddings.
- Meanwhile, audio segments are transcribed using ElevenLabs Scribe v2 and saved with the corresponding visual memories.
- Finally, user queries initiate a semantic search in ChromaDB using recent memory context. This prompts Gemini to formulate an answer that ElevenLabs TTS reads aloud.
Frontend (Next.js 16 + TypeScript + Tailwind): We designed a dark-themed glassmorphism interface highlighted with cyan accents. It features a split layout with a live memory timeline and mood tagging on one side, and a conversational chat on the other. An integrated analytics page presents activity histograms, frequently detected objects, and mood distribution. Additionally, real-time indicators monitor hardware connection health.
Key tech: OpenCV, Ultralytics YOLOv8, Google Gemini 2.5 Flash, ElevenLabs (Scribe v2 + TTS), ChromaDB, SQLite, Flask, Next.js, Recharts.
Challenges we ran into
- ESP32 networking: Connecting both ESP32 boards and the laptop reliably to the same network was surprisingly difficult. We faced changing IPs, mismatched subnets, and WiFi buffer overflows that corrupted frames until we switched to chunked data transmission.
- API rate limits: Our initial design quickly exhausted Gemini's free tier of 20 requests per day. We had to completely redesign the pipeline, dropping from roughly 90 API calls per minute to around 30. We achieved this by increasing batch sizes, limiting the number of selected frames, and swapping the Gemini-based frame selector for a local heuristic method.
- I2S audio quality: The INMP441 microphone outputs 32-bit I2S samples that require downsampling to 16-bit PCM. Achieving clean audio without clipping or dead air took extensive debugging.
- Concurrent writes: SQLite's restriction to a single writer required us to carefully manage threading and locks, especially since multiple pipeline stages needed to write data simultaneously.
Accomplishments that we're proud of
- Working with hardware for the first time: None of our team members had prior experience with embedded systems, yet we successfully built a working wearable device from the ground up.
- Functional end-to-end pipeline: The entire system works seamlessly, from the moment light hits the camera sensor to the spoken response detailing where you left your keys.
- Semantic memory search: ChromaDB embeddings mean queries work by meaning, not just keyword matching. "Where's my drink?" finds memories about a McDonald's cup seen earlier
What we learned
- The mechanics of I2S communication between MEMS microphones and microcontrollers.
- Techniques for ESP32 camera initialization, PSRAM management, and MJPEG streaming protocols.
- The critical role of rate limiting and cost optimization in real-time AI pipelines.
- The power of vector databases like ChromaDB in enabling semantic search across unstructured data.
- Effective threading patterns in Python to handle concurrent I/O-bound and CPU-bound tasks.
- The reality of hardware debugging: it is often 80% checking connections and 20% fixing actual logic bugs.
What's next for Recall
- On-device inference: Running a lightweight vision model straight on the ESP32-S3 to minimize bandwidth and reduce latency.
- Longer-term memory: Implementing tiered storage with daily summaries that condense into weekly and monthly overviews, allowing Recall to answer questions like "What did I do last Tuesday?"
- Caregiver dashboard: Building a dedicated interface for family members and caregivers to track activity patterns and get alerts.
- Proper glasses form factor: Designing a custom PCB to shrink the electronics so they fit into frames resembling standard everyday glasses.
- Offline mode: Utilizing local LLM inference (such as Gemma or Phi) for privacy-conscious users who want to ensure no data leaves their device.
- Multi-user support: Adding facial recognition to differentiate between the people the user interacts with, which would enable questions like "What did Sarah tell me yesterday?"











Log in or sign up for Devpost to join the conversation.