

Inspiration
Amazing recent advances in deep learning for computer vision, video processing, and natural language have led to increasingly realistic generation of fake faces, voices, and videos. We’re deeply interested in ML, and so we wanted to use some of these recent developments to build something that could engage and captivate people, while also providing potential utility for real world use.
What it does
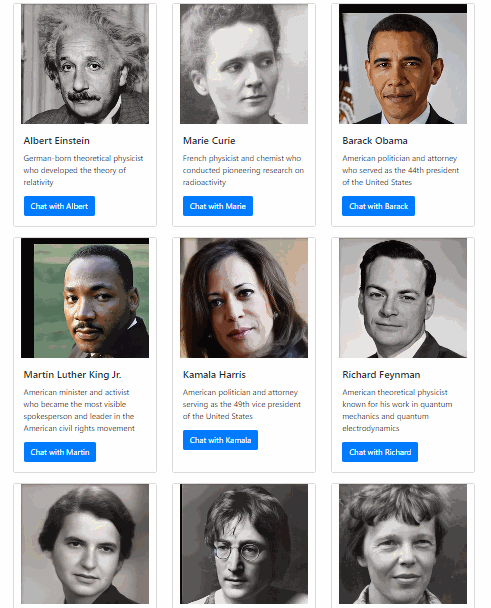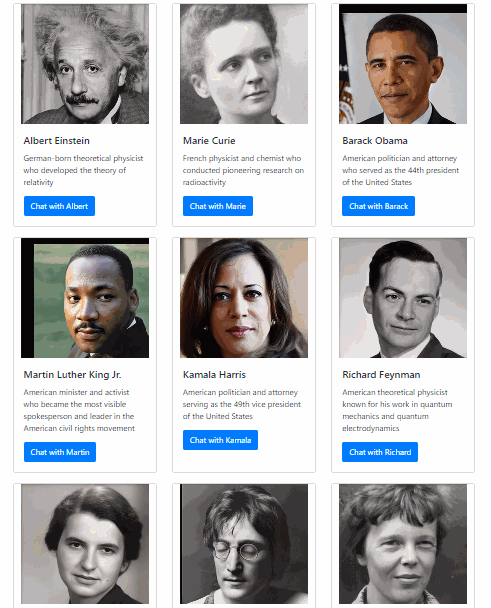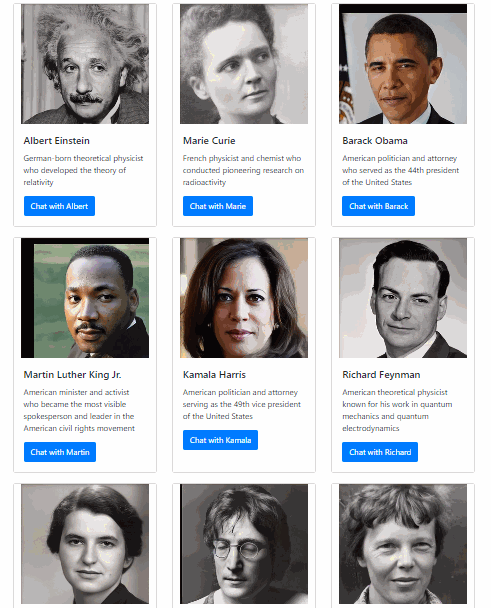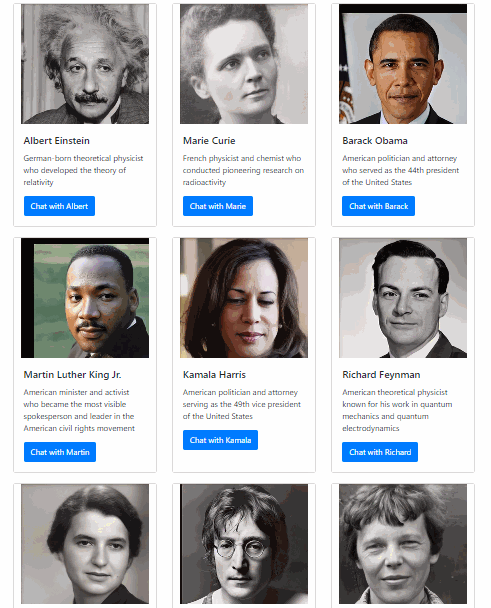
We’ve built a web app that lets you talk to anyone with the power of AI. This isn’t your average chatbot -- our app produces a synchronized audiovisual representation of the person speaking, as if you were talking to this person in real life. With voice synthesized from text and lips synced to the voice, it produces an experience that gets you one step closer to talking to people that don’t actually exist. We hope that this will dramatically increase the immersion factor of educational apps and inspire people to learn more about history and science.
How we built it
We used React and Next.js to power the frontend web application and Python Flask to run our backend server. On the backend, we use GPT-3 to generate response messages, Google Cloud Text-to-Speech and Real-Time Voice Cloning to synthesize audio from those messages, First Order Motion Model and Deep Nostalgia to generate dynamic video from still photos, and finally, Wav2Lip to generate video lip-synced with the synthesized audio. We then store the generated video in Google Cloud Storage so that it can be accessed from our web app.
Challenges we ran into
Throughout this project we’ve ran into a number of issues. We want to return the output in as little time as possible to maximize the realism of actually talking to someone. The critical issue here was the extensive amount of computing time it took for the input to make its way through the pipeline. We made numerous changes to the provided codebases to cut down on compute time by around 5x. Some optimizations that we made include caching voice encodings for our text-to-speech model and replacing Wav2Lip’s slow and resource-hungry face detection model with a fast and efficient one.
Another challenge was producing audio and video of suitable quality. To reliably synthesize convincing audio from arbitrary text using Real-Time Voice Cloning, we had to manually find high-quality audio clips online to serve as template utterances, followed by significant audio preprocessing. We also had to spend significant time experimenting with the best animation poses for use with the First Order Motion Model.
Accomplishments that we're proud of
We’ve created a fully functional app that has a lot of potential for real world use. We are also extremely proud of being able to optimize the voice to lip movement process. Out of the box, it would take almost a minute to output a video in comparison to our now 10-20 second time frame. This keeps the latency between the user typing a message to the final output short enough to not break the illusion too much. We were also especially proud of the amount of features that we were able to fit into this application within just 24 hours of hacking. We were able to implement many of our stretch goals, such as community features and custom profile uploads.
What we learned
We learned a ton about how to integrate deep learning models into web applications. We also learned a lot about React, Flask, and working with the linux command line. We’ve also experienced many instances where we were stuck on certain parts and were tempted to give up but someone else always found either a fix or workaround and we ended up getting nearly everything we wanted to be done. This proved that we were able to persevere even through the toughest of times and really taught us that working together and not giving up will produce something that we’re proud of.
What's next for RealTalk
We want to scale our app to support many concurrent users and build out its community functionality by setting up a robust user uploading pipeline, as well as adding community features such as: letting users upload their own voices for cloning, providing options for users to fine-tune their profiles, and letting users interact with and rate other users’ profiles. We would also like to synthesize more voices from samples, since we only had the time to build and tweak a handful of voices. Additional features we would have liked to add include: providing a speech-to-text for users, allowing users to select famous profiles to talk to each other, and randomly generating entire profiles (like thisfacedoesnotexist.com). Improving GPT-3’s accuracy would help our app provide more correct information to users, and lastly, as deepfake models become more believable, we need to consider the ethics of our app if it were to be used to defraud or defame others.
Built With
- google-cloud
- gpt-3
- pytorch
- react
- vercel











Log in or sign up for Devpost to join the conversation.