-
-
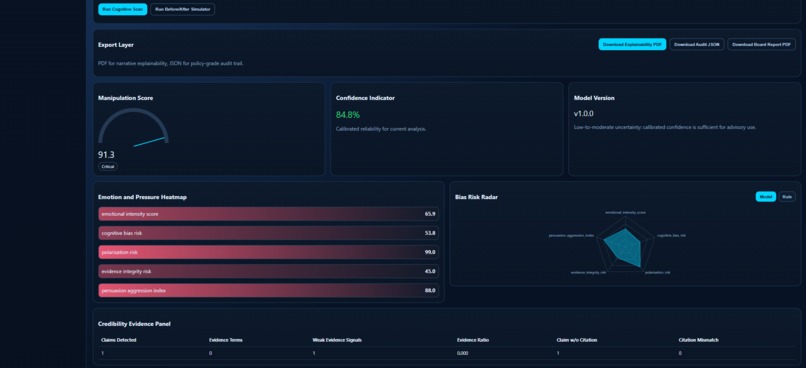
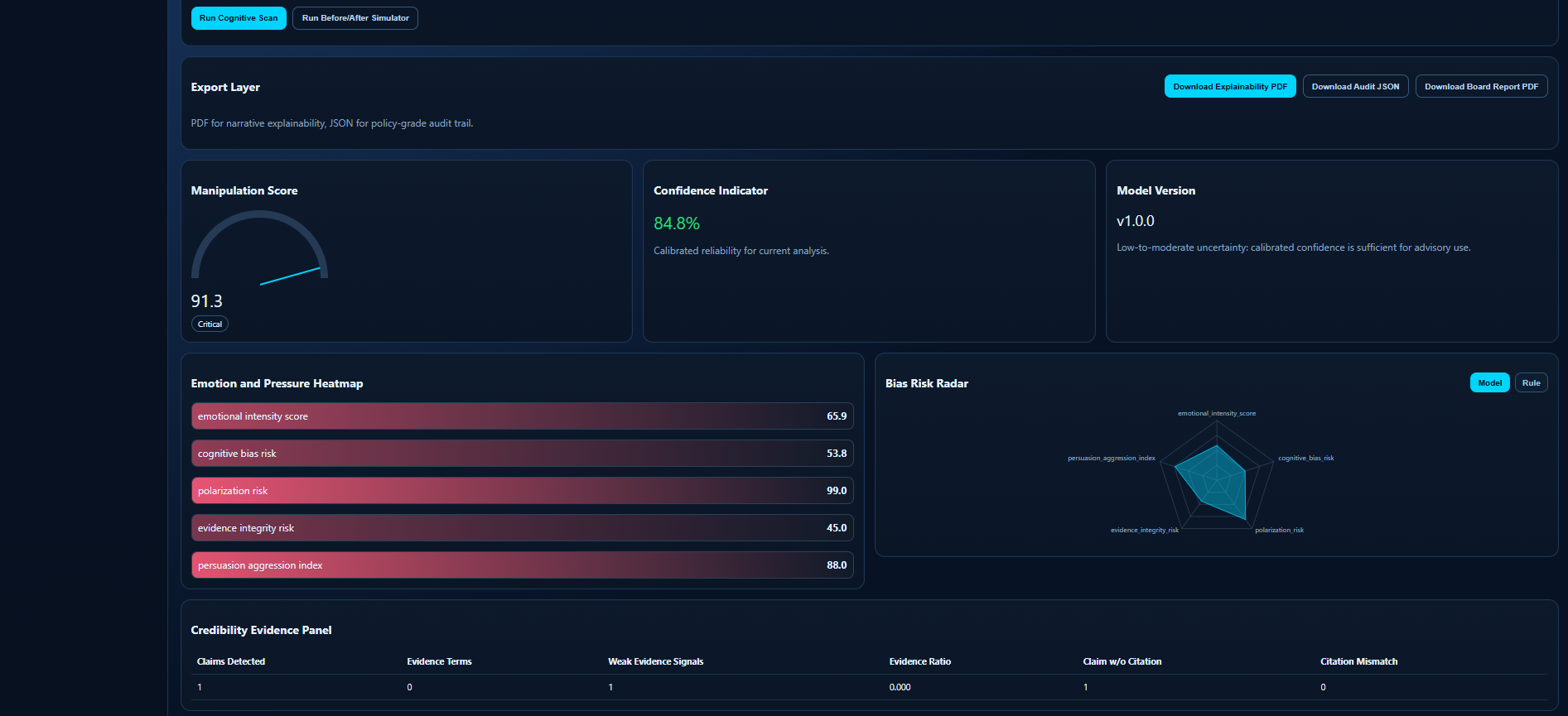
Critical manipulation detected with explainable score, confidence, tactic heatmap, and evidence integrity panel
-
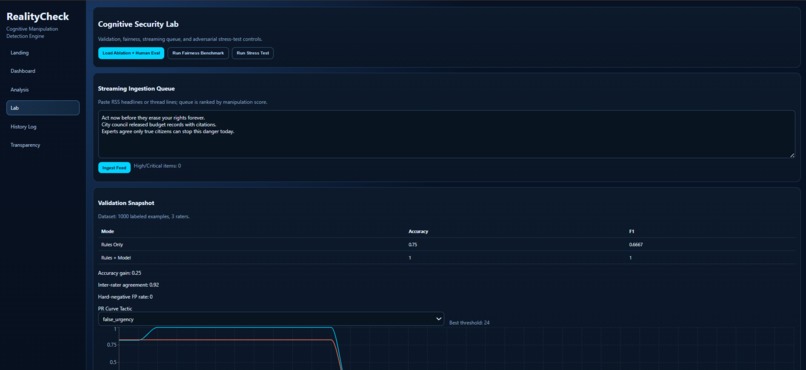
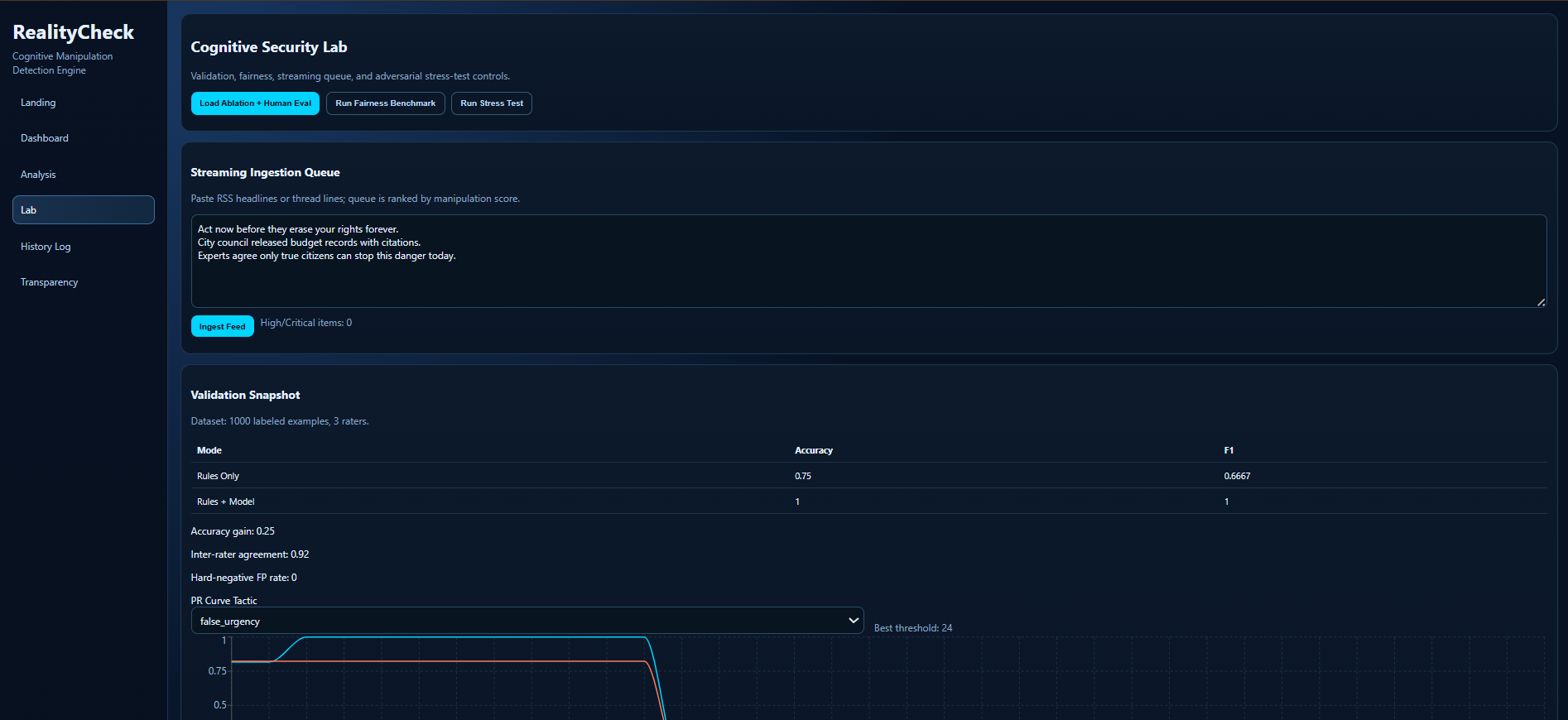
Cognitive Security Lab showing validation metrics, fairness controls, and real-time streaming ingestion workflow.
-
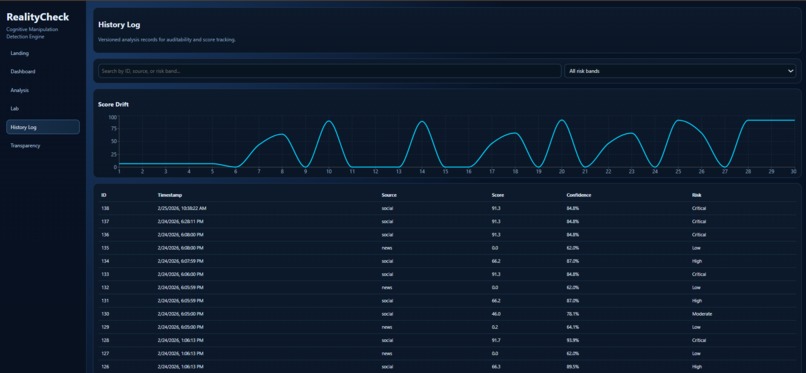
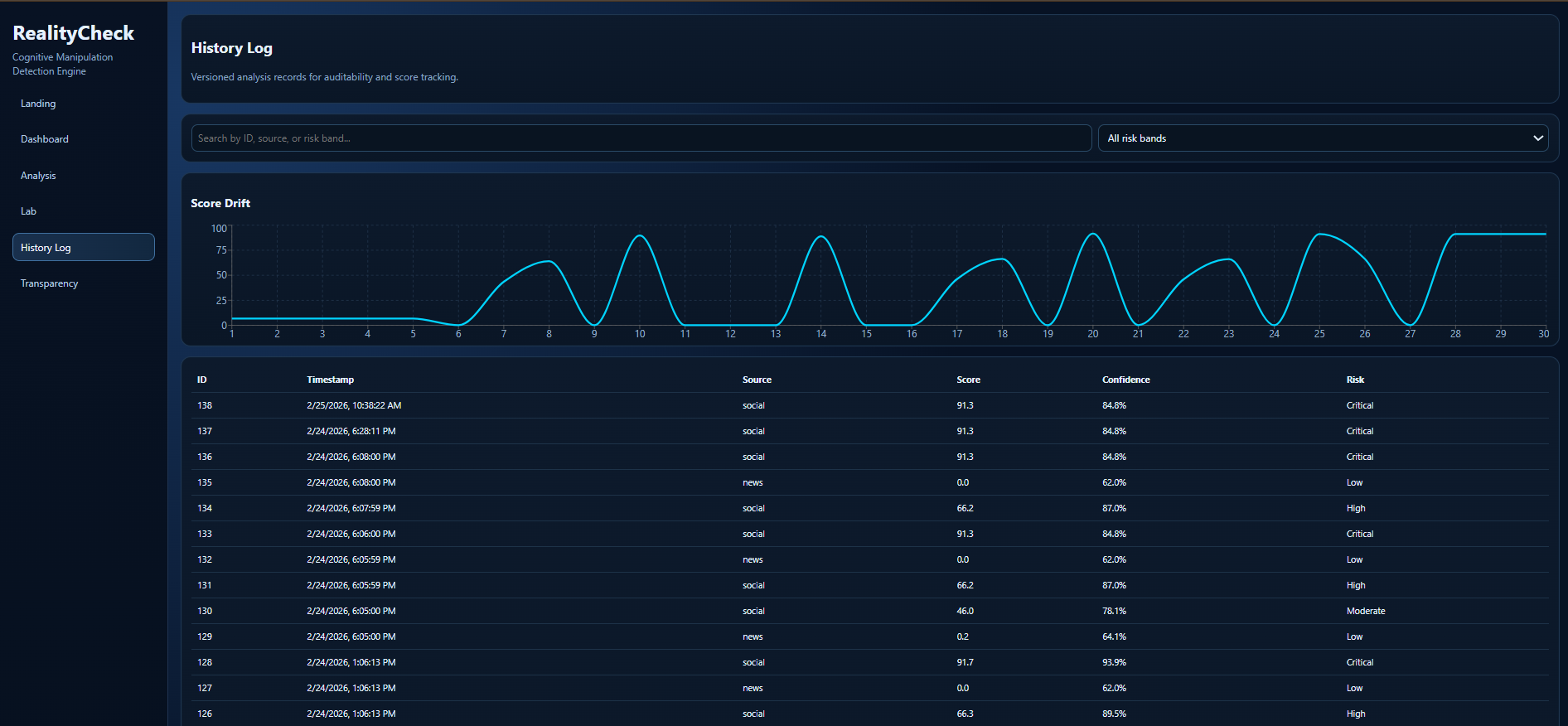
History Log with score drift analytics and audit-ready records of past analyses.
-
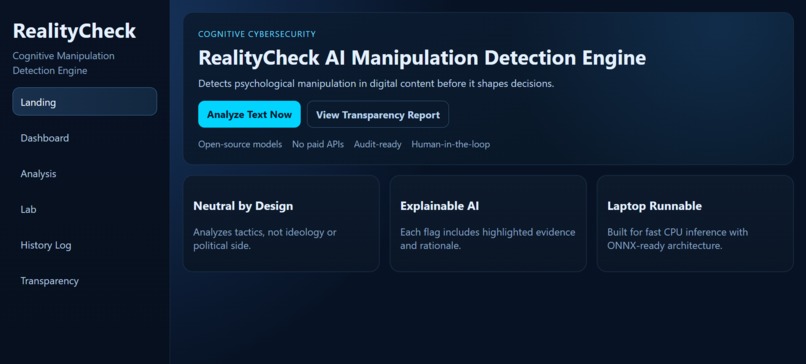
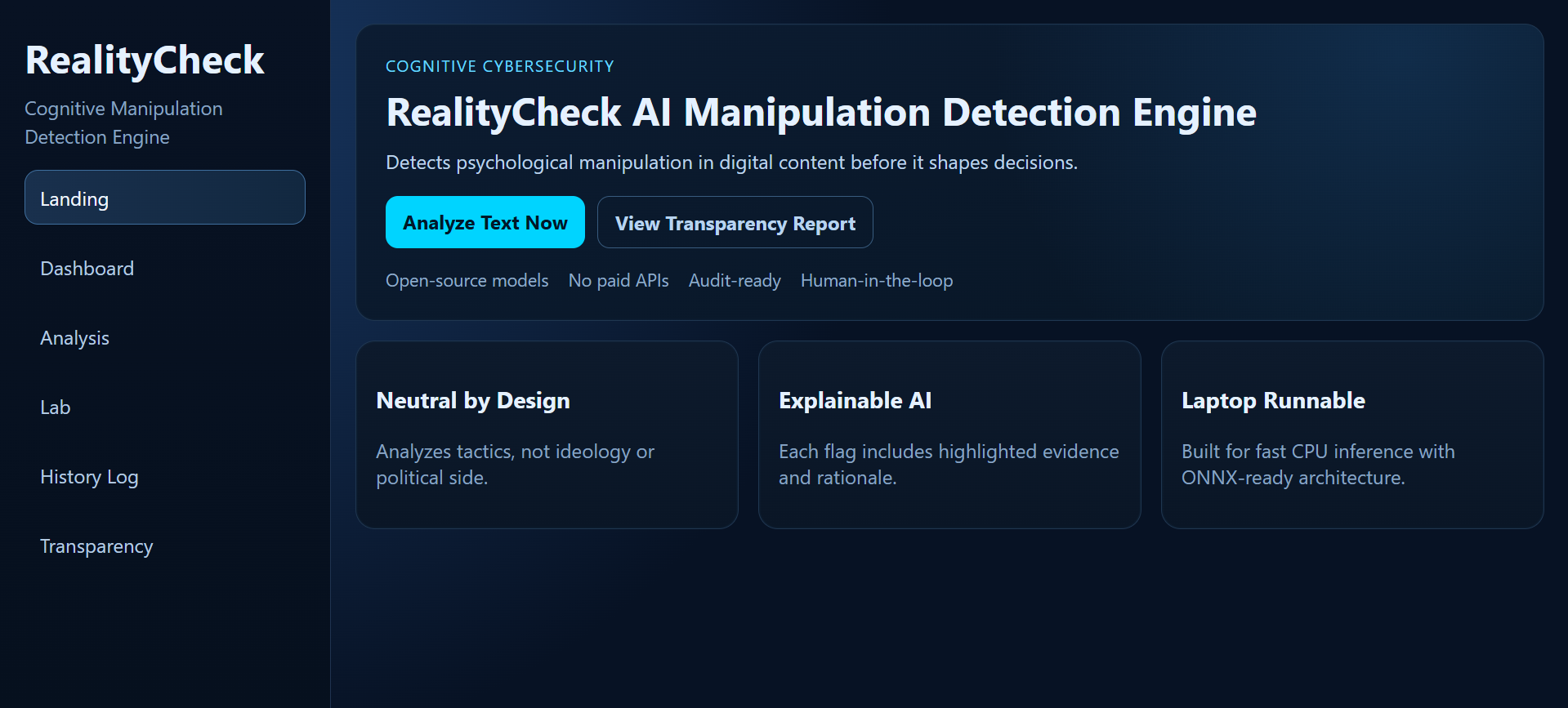
RealityCheck landing page introducing the cognitive cybersecurity mission and core platform strengths.
-
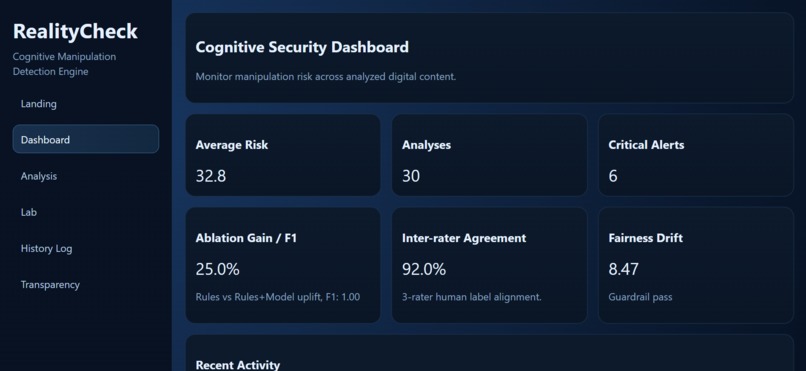
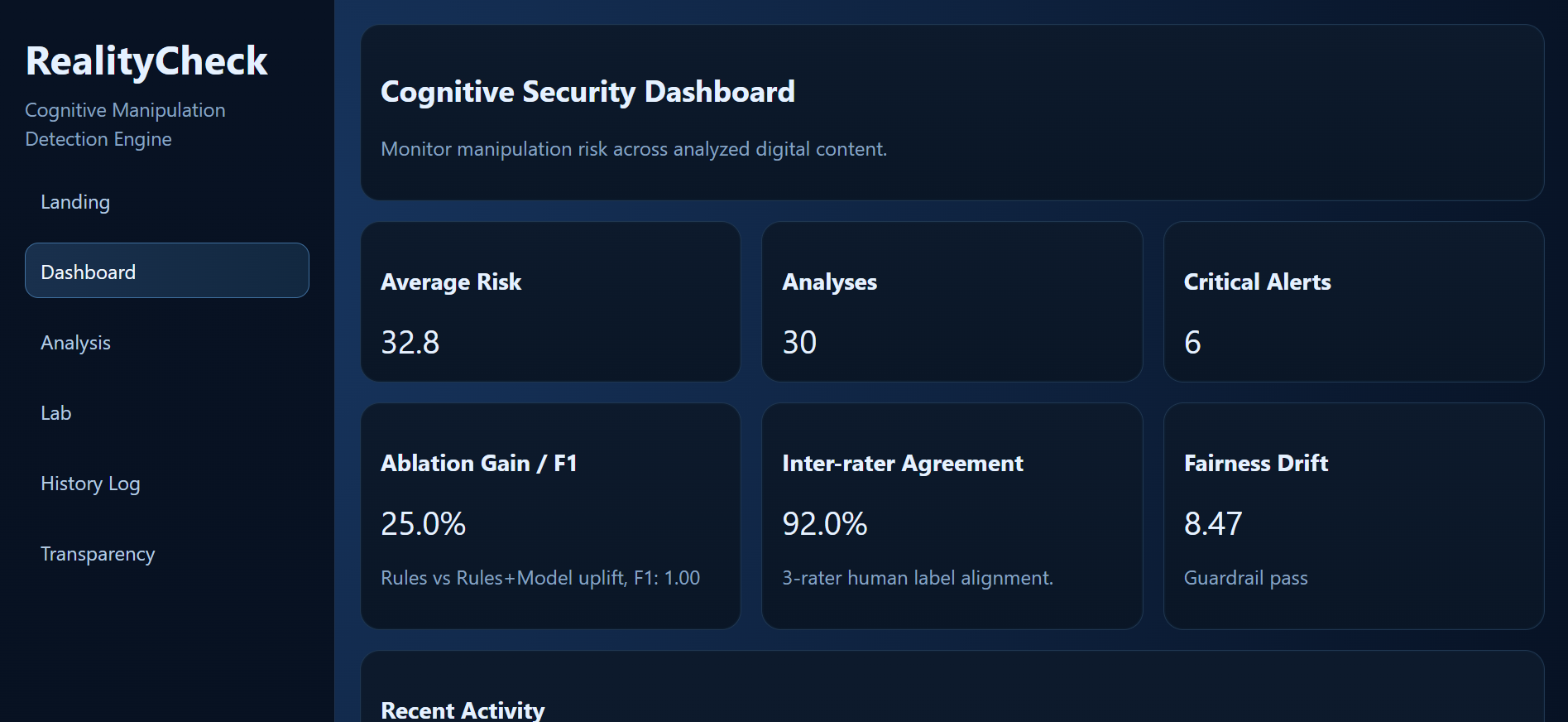
Executive dashboard summarizing risk, ablation gain, inter-rater agreement, and fairness drift status.
-
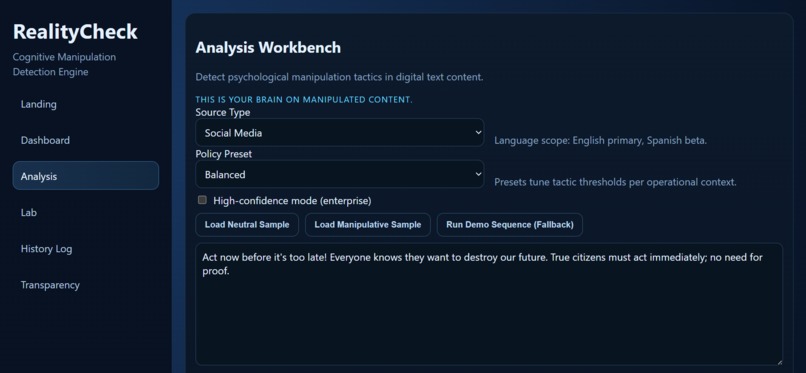
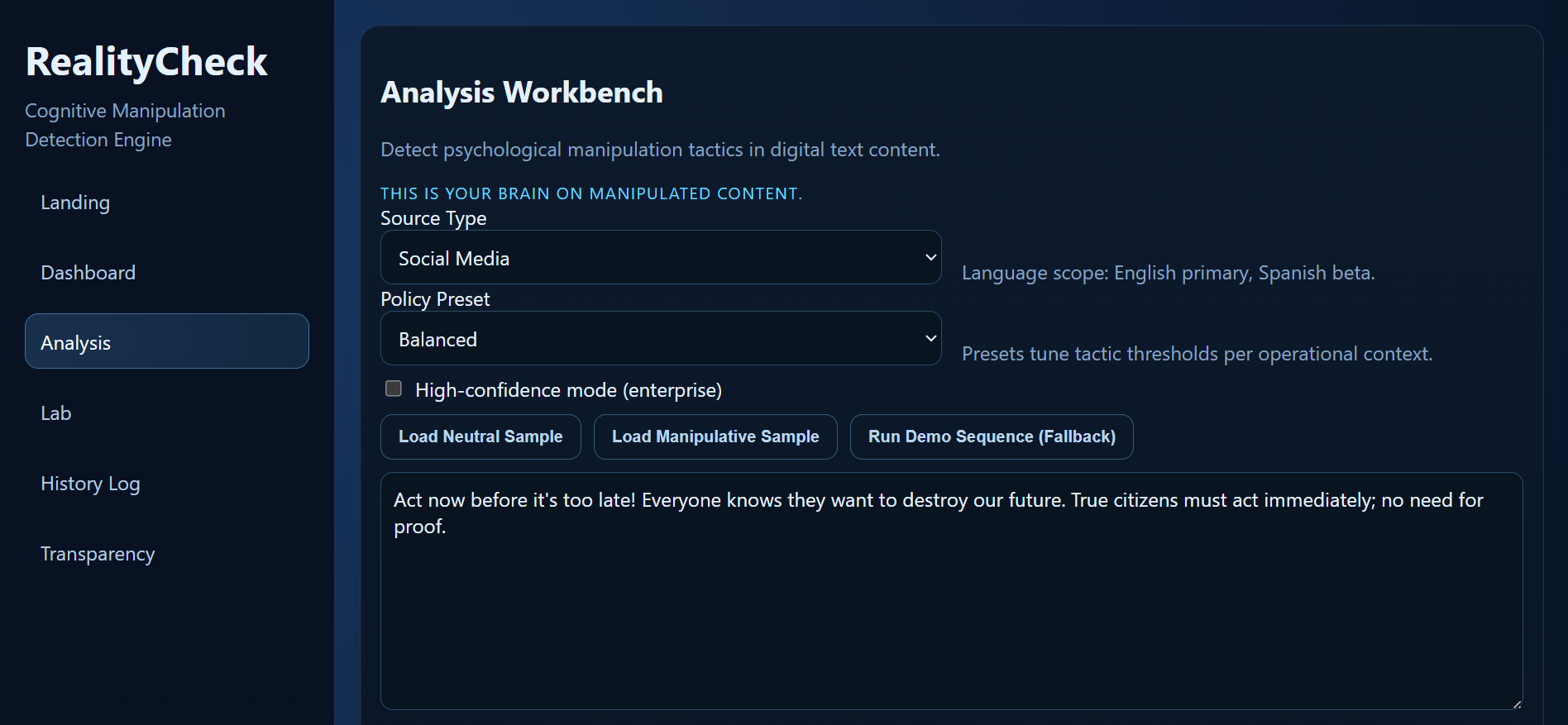
Analysis Workbench for source selection, policy presets, and live manipulation scanning of input text.
Inspiration
RealityCheck was inspired by a clear blind spot in content safety: many systems detect toxicity or factual errors, but psychological manipulation tactics often pass through. We wanted to detect how language pressures cognition while staying neutral on ideology.
What it does
RealityCheck analyzes digital text (news, social, speeches, marketing) and detects:
- fear amplification
- false urgency
- authority manipulation
- polarization framing
- evidence absence
It returns:
- Manipulation score (0 \rightarrow 100)
- Risk band
- Tactic-level breakdown
- Phrase-level rationale
- Confidence + uncertainty
- Fairness guardrail status
- Audit-ready exports (JSON/PDF)
The scoring intuition is:
[ \text{ManipulationScore} = \sum_i w_i \cdot s_i + \text{concentration_bonus} - \text{confidence_penalty} - \text{language_penalty} ]
where (s_i) are tactic/category scores and (w_i) are calibrated weights.
How we built it
- Frontend: React + TypeScript + Vite
- Backend: FastAPI + Pydantic + SQLAlchemy
- Inference: Hybrid rules + compact transformer ensemble
- Validation: Human-eval pack, ablation, threshold tuning, stress/fairness checks
- Product surfaces: Dashboard, Analysis Workbench, Lab, History, Transparency, Extension MVP
Core ensemble logic:
[ \hat{y}{tactic} = \alpha \cdot y{\text{rules}} + (1-\alpha)\cdot y_{\text{model}} ]
with per-tactic (\alpha) tuned from validation curves.
Challenges we ran into
- Precision vs recall tradeoff
Avoiding false positives on expressive but legitimate writing. - Explainability depth
Making outputs understandable to judges and non-ML stakeholders. - Neutrality + fairness constraints
Ensuring no political stance classification and adding identity-swap drift checks. - Hackathon runtime constraints
Keeping the system laptop-runnable while preserving technical depth.
Accomplishments that we're proud of
- Built an end-to-end cognitive cybersecurity platform, not a toy classifier.
- Added phrase-level rationale, confidence calibration, and governance metadata.
- Implemented fairness guardrails and stress-test workflows.
- Delivered stream triage with review/escalation actions.
- Produced submission-grade evidence artifacts and reproducible evaluation scripts.
What we learned
- In high-stakes AI, governance and explainability are first-class requirements.
- Manipulation detection needs multi-signal structure, not keyword matching.
- Clear boundary definitions increase trust:
- what the model does
- what it does not do
- Operational workflows (triage, audit export, transparency) are critical for adoption.
What's next for RealityCheck – AI Cognitive Manipulation Detection Engine
- Expand from 5 to 10 tactic classes.
- Improve multilingual robustness beyond English-first scope.
- Deploy compact ONNX model as default runtime path.
- Add enterprise controls (team workflows, RBAC, policy presets).
- Strengthen active-learning loops using drift + error-analysis feedback.
- Launch production browser extension backed by the full API stack.
Built With
- docker
- fastapi
- github
- html/css
- huggingface
- javascript
- onnx
- pydantic
- pytest
- python
- react
- recharts
- sqlalchemy
- sqlite
- typescript
- uvicorn
- vite


Log in or sign up for Devpost to join the conversation.