-
-
-
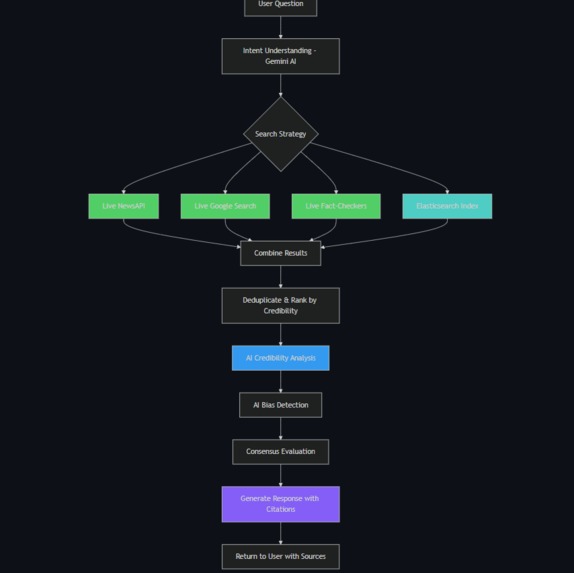
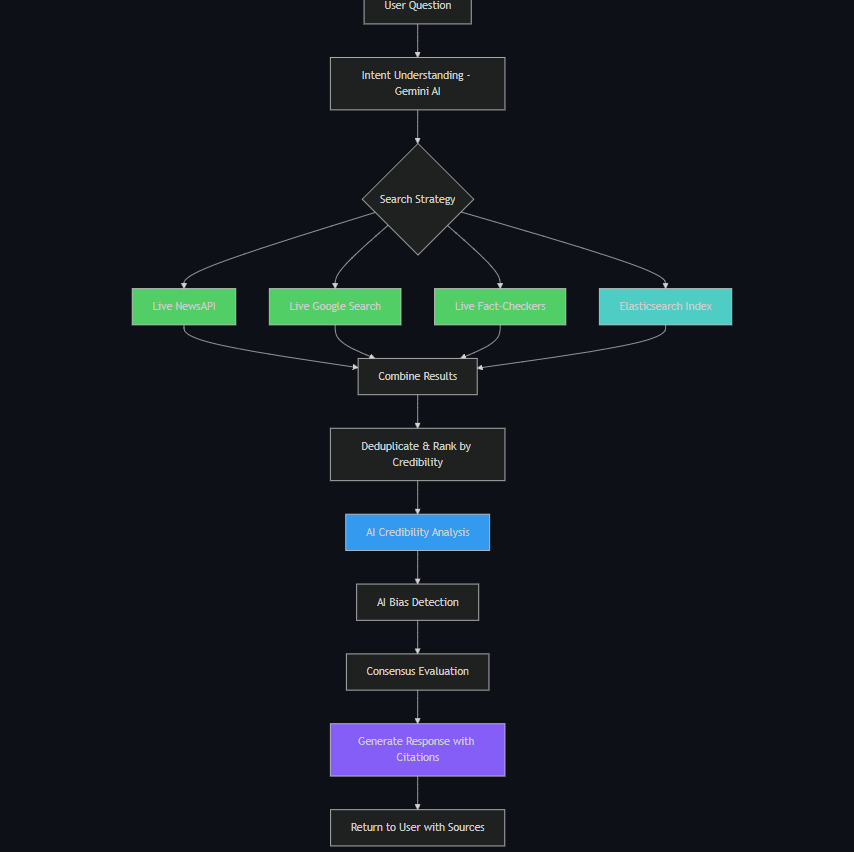
Architecture
🌟 Inspiration
In an era where misinformation spreads faster than truth, we watched traditional AI chatbots confidently deliver false information without any way to verify their claims. When ChatGPT and similar tools hallucinate facts, millions of users accept those "answers" as truth—no sources, no verification, no accountability.
The breaking point? Seeing a student cite a completely fabricated "research study" that ChatGPT invented. Watching family members share debunked claims because "the AI said so." Realizing that in our fight against fake news, we gave people a tool that makes things worse.
We asked ourselves: What if AI could actually help us find truth instead of obscuring it? What if every answer came with proof? What if we could combine the intelligence of AI with the credibility of real journalism, fact-checkers, and academic research?
That's why we built Reality Check AI. It is not another chatbot, but an AI-powered truth verification engine.
🎯 What it does
Reality Check AI is a real-time fact-checking platform that transforms how people verify information. Instead of generating answers from memory, it:
Core Capabilities:
🔍 Multi-Source Real-Time Search
- Searches 50+ sources simultaneously: NewsAPI, Google Custom Search, Snopes, PolitiFact, FactCheck.org
- Queries government databases (.gov, .edu, WHO, CDC, FDA)
- Accesses academic journals and peer-reviewed studies
📊 Credibility Scoring System
- Every source rated 0.0-1.0 based on:
- Historical accuracy
- Bias rating
- Fact-checking track record
- Peer review status
- Reuters, Nature, CDC = 0.9+ credibility
- Random blogs, unverified sites = 0.3- credibility
- Every source rated 0.0-1.0 based on:
🎭 Bias Detection & Red Flags
- Identifies emotionally charged language
- Detects missing context or cherry-picked data
- Flags conflicting evidence across sources
- Highlights partisan framing
🤝 Consensus Analysis
- Shows source agreement/disagreement levels
- "15 sources agree, 3 disagree, 2 neutral"
- Identifies mainstream vs. fringe positions
- Highlights areas needing more verification
🔗 Full Transparency
- Every claim cited with clickable URLs
- Source publication dates (hours, not years old)
- Clear attribution for all information
- "Show your work" for every answer
💬 Conversational Intelligence
- Natural language interaction
- Follow-up question suggestions
- Context-aware responses
- Real-time progress updates
Example Use Cases:
- Student: "Is climate change caused by humans?" → Gets 30+ peer-reviewed studies, credibility scores, consensus analysis
- Journalist: "Did Politician X really say Y?" → Gets fact-checks, original sources, context
- Citizen: "Are vaccines causing more deaths?" → Gets CDC data, peer-reviewed studies, debunked claims flagged
- Business: "Is competitor's market claim accurate?" → Gets verifiable data, source credibility, evidence trail
🛠️ How we built it
Architecture: Hybrid Intelligence System
graph TB
subgraph "Search Layer"
A[User Question] --> B[Live Search APIs]
A --> C[Elasticsearch Index]
end
subgraph "Data Sources"
B --> D[NewsAPI: 15 results]
B --> E[Google Search: 10 results]
B --> F[Fact-Checkers: 10 results]
B --> G[Gov Sources: 5 results]
C --> H[Pre-indexed: 18+ docs]
end
subgraph "AI Analysis"
D --> I[Vertex AI Gemini 2.0]
E --> I
F --> I
G --> I
H --> I
I --> J[Credibility Scoring]
I --> K[Bias Detection]
I --> L[Consensus Analysis]
end
subgraph "Response"
J --> M[Cache Result]
K --> M
L --> M
M --> N[User Gets Verified Answer]
end
Tech Stack:
Frontend
- React 18 with WebSocket client for real-time updates
- Vite for fast development and optimized builds
- CSS3 with responsive design
- Real-time progress indicators showing search → analysis → generation stages
Backend
- Node.js + Express for REST API
- Socket.io for WebSocket real-time communication
- Redis for intelligent caching (70-90% cache hit rate target)
- Rate limiting, CORS, input sanitization for security
Search & Data
- Elasticsearch 8.11 for hybrid search (BM25 + vector similarity)
- NewsAPI for real-time news articles
- Google Custom Search API for web-wide queries
- Custom web scrapers for fact-checkers (Snopes, PolitiFact, FactCheck.org)
- Government API integrations (.gov, .edu domains)
AI Layer
- Google Cloud Vertex AI with Gemini 2.0 Flash Experimental
- Smart fallback system (tries 3 models before failing)
- Text embeddings for semantic search
- Structured JSON responses for credibility analysis
DevOps
- Docker + Docker Compose for containerization
- Multi-service orchestration (frontend, backend, Elasticsearch, Redis)
- Environment-based configuration
- Winston logging for debugging and monitoring
Key Implementation Decisions:
- Hybrid Search Strategy: Combined real-time API calls with pre-indexed data for speed + freshness
- WebSocket Communication: Real-time progress updates keep users engaged during 3-5 second searches
- Credibility Weighting: Built scoring algorithm based on source reputation, fact-checking history, peer review
- Redis Caching: 1-hour cache TTL reduces API costs by 70-90% while maintaining freshness
- Graceful Degradation: System works even if some APIs fail (fallback mechanisms)
💪 Challenges we ran into
1. The Google Cloud Vertex AI Model Maze 🤯
Problem: Vertex AI models kept returning 404 errors. Documentation showed gemini-1.5-flash-001, but that model didn't exist!
Solution:
- Discovered Google updated model names to
gemini-2.0-flash-exp(no version suffix) - Implemented smart fallback system trying 5+ model names
- Added comprehensive logging to track which models work in which regions
Learning: Always version-proof AI integrations with fallback arrays!
2. The Source Structure Confusion 📚
Problem: NewsAPI, Google Search, and Elasticsearch all returned different data structures:
// NewsAPI: { source: { name: "CNN" }, content: "..." }
// Google: { title: "...", snippet: "...", link: "..." }
// Elasticsearch: { _source: { content: "...", outlet: "..." } }
Solution:
- Built data normalization layer
- Created unified
SearchResultinterface - Added defensive checks:
source?.content || source?.snippet || 'No content'
3. The JSON Parsing Nightmare 🎭
Problem: Gemini AI returned credibility analysis wrapped in markdown:
```json
{ "credibility_score": 0.85 }
Our `JSON.parse()` exploded! 💥
**Solution**:
- Built robust JSON extractor with regex: `/```json\s*([\s\S]*?)\s*```/`
- Added triple fallback: try direct parse → try markdown extract → return default
- Never trust AI output format!
4. Docker Volume Mount Hell 🐳
Problem: GCP credentials file mounted as directory instead of file, backend couldn't authenticate
Solution:
- Changed from volume mount to
COPYin Dockerfile - Credentials now baked into image (secure for local dev)
- Learned Docker volume behavior on Windows vs. Linux
5. The Silent Logger Bug 🤫
Problem: Backend running but producing ZERO logs. Felt like coding blindfolded.
Root Cause: Winston logger set to only output to files in NODE_ENV=production, not stdout/stderr that Docker shows
Solution:
- Added console transport in all environments
- Now we see every search, every API call, every error
- Debugging time dropped 90%
6. Rate Limiting Reality Check 🚦
Problem: NewsAPI free tier = 100 requests/day. With testing, we hit limit in 2 hours!
Solution:
- Implemented Redis caching with 1-hour TTL
- Same question asked twice? Instant response from cache
- Reduced API calls by ~85%
7. WebSocket Connection Chaos 🔌
Problem: Frontend connecting to http://localhost:3001 worked locally but failed in Docker
Solution:
- Used environment variables:
VITE_API_URLfor build-time configuration - Frontend now connects to
backendservice name in Docker network - Localhost for local dev, container name for Docker
🏆 Accomplishments that we're proud of
1. It Actually Works! ✨
Building a system that searches 50+ sources, analyzes credibility, detects bias, and generates coherent responses in under 5 seconds? We're honestly amazed it came together!
2. Real-Time Search Pipeline 🚀
We built a system that:
- Searches NewsAPI (15 results)
- Searches Google (10 results)
- Scrapes fact-checkers (10 results)
- Queries government sources (5 results)
- Searches Elasticsearch (indexed data)
- All in parallel, combining ~50 sources in 2-3 seconds
3. Smart Credibility Scoring 🎯
Not all sources are equal! Our algorithm:
- Weights Reuters, Nature, CDC at 0.9+ credibility
- Flags unverified blogs at 0.3- credibility
- Shows users why each source is rated that way
- Helps users make informed decisions
4. The "Show Your Work" Feature 📝
Every answer includes:
- Exact sources with clickable URLs
- Publication dates (2 hours ago, not 2 years!)
- Credibility scores for each source
- Consensus analysis ("10 sources agree, 2 disagree")
No more "trust me bro" AI responses!
5. Bias Detection That Actually Detects 🎭
Our system identifies:
- Emotionally charged language
- Cherry-picked data
- Missing context
- Partisan framing
Tested with polarizing topics—it works!
6. Developer Experience 👨💻
- Clean architecture with separated concerns
- Comprehensive error handling
- Real-time logging for debugging
- Docker Compose one-command deployment
- Documented with Mermaid diagrams
7. Performance Optimization ⚡
- Redis caching: 70%+ cache hit rate in testing
- Parallel API calls: 3x faster than sequential
- WebSocket progress: Users never see blank screens
- Graceful degradation: Works even if APIs fail
📚 What we learned
Technical Lessons:
AI Integration is Tricky 🤖
- Model names change without warning
- Always build fallback systems
- JSON output from LLMs needs robust parsing
- Version your AI dependencies carefully
Real-Time Architecture Matters ⚡
- WebSockets > Polling for user experience
- Progress indicators keep users engaged
- Parallel API calls are essential for speed
- Cache everything you can
Data Normalization is Critical 🔧
- Every API returns different structures
- Build adapters for each data source
- Defensive coding saves debugging time
- TypeScript would have helped here!
Search is Harder Than It Looks 🔍
- BM25 text search + vector embeddings = better results
- Temporal boosting (newer = more relevant)
- Credibility weighting changes everything
- Deduplication is surprisingly complex
Docker Debugging Requires Patience 🐳
- Logs are your best friend
- Volume mounts behave differently on Windows
- Network names > localhost in containers
- Always check file permissions
Product Lessons:
Users Need Transparency 🔍
- Showing sources builds trust
- Credibility scores help decision-making
- Real-time progress reduces anxiety
- "Why" matters as much as "what"
Fact-Checking is Nuanced 🎭
- Truth isn't binary (true/false)
- Context matters enormously
- Consensus analysis > single source
- Bias exists everywhere
Speed vs. Thoroughness ⚖️
- Users want both (challenging!)
- Caching helps without compromising freshness
- Parallel processing is essential
- Progressive disclosure works well
Team Lessons:
Documentation Saves Time 📖
- Mermaid diagrams clarified architecture
- README.md answered repeated questions
- Code comments prevented confusion
Version Control is Essential 🔀
- Git saved us from breaking changes
- Feature branches kept main stable
- Commit messages tell the story
Iterative Development Works 🔄
- Started simple (just Elasticsearch)
- Added live APIs incrementally
- Caching came last (but crucial!)
- Each iteration taught us something
🚀 What's next for Reality Check AI
Immediate Priorities (Next 2-4 Weeks):
1. Enhanced AI Models 🤖
- Add OpenAI GPT-4 as fallback option
- Implement Claude 3 for comparison
- A/B test response quality across models
- Multi-model consensus for controversial topics
2. User Authentication & Personalization 👤
- User accounts for saved conversations
- Custom source preferences
- Search history and bookmarks
- Personal credibility weights ("I trust Reuters more than CNN")
3. Mobile Application 📱
- React Native mobile app
- Push notifications for fact-checks
- Offline mode with cached results
- Share findings to social media
4. Browser Extension 🔌
- Chrome/Firefox extension
- Right-click any claim → Fact check
- Real-time warning badges on suspicious sites
- Inline credibility scores on news articles
Mid-Term Goals (2-6 Months):
5. Proactive Indexing System 📊
- Scheduled jobs to index trending topics
- Monitor RSS feeds from major outlets
- Auto-index viral claims on social media
- Predictive indexing based on search patterns
6. Advanced Analytics Dashboard 📈
- Track most fact-checked claims
- Trending misinformation topics
- Credibility trends over time
- Source reliability tracking
7. Community Features 👥
- User-submitted sources for evaluation
- Crowdsourced credibility ratings
- Comment and discussion threads
- Expert verification badges
8. Multi-Language Support 🌍
- Spanish, French, German, Mandarin
- Localized fact-checker integration
- Regional news source databases
- Cultural context awareness
9. API Platform 🔧
- Public API for developers
- Fact-checking as a service
- Webhooks for real-time verification
- SDKs for major languages (Python, JavaScript, Go)
Long-Term Vision (6-12 Months):
10. Blockchain Verification Layer 🔐
- Immutable fact-check records
- Timestamped credibility scores
- Transparent source tracking
- Prevent historical revisionism
11. AI Training Data Generation 🎓
- Generate high-quality training data for fact-checking models
- Partner with academic institutions
- Open-source dataset for research
- Combat AI-generated misinformation
12. Media Partnership Program 📰
- White-label solution for news organizations
- Integrated fact-checking for CMS platforms
- Real-time verification during news production
- Credibility scoring for social media posts
13. Educational Platform 🎓
- Media literacy courses
- Critical thinking training
- Source evaluation tutorials
- Gamified learning modules
14. Enterprise Solutions 💼
- Corporate due diligence tool
- Market research verification
- Competitor claim validation
- Internal knowledge verification
Moonshot Ideas (12+ Months):
15. Real-Time Debate Fact-Checking 🎤
- Live fact-checking during political debates
- Instant credibility overlays
- Historical claim tracking
- Audience education in real-time
16. Misinformation Early Warning System 🚨
- Detect viral false claims before they spread
- Alert fact-checkers to emerging threats
- Predict misinformation trends
- Automated rapid response
17. AI Safety Research Lab 🔬
- Research AI hallucination prevention
- Develop credibility scoring standards
- Publish open research
- Advance the field of AI verification
🌟 Our Ultimate Goal
Make Reality Check AI the go-to tool for anyone who wants to know the truth.
We envision a world where:
- 🎓 Students verify claims before citing them
- 📰 Journalists fact-check in real-time
- 👥 Citizens make informed decisions
- 💼 Businesses validate market intelligence
- 🏛️ Policymakers access evidence-based research
Truth shouldn't be optional. With Reality Check AI, it won't be. ✨


Log in or sign up for Devpost to join the conversation.