-
-

Real Truth or Dare
-
me trying my app


Real Truth or Dare
Introducing REAL TRUTH OR DARE, a web based app that can detect an anomaly in your speech or answer and this anomaly can be used as a reference to tell either the person telling truth or lie, ofc while playing truth or dare in a zoom with your friends
Inspiration
so while doing online school, me and my friends often play a game called truth or dare, the game is about either choosing to tell a truth about something that ur friend ask or go and do a dare that your friend ask for. But the problem here is how if your friend is lying?, how can you tell?
How Does Web This Work
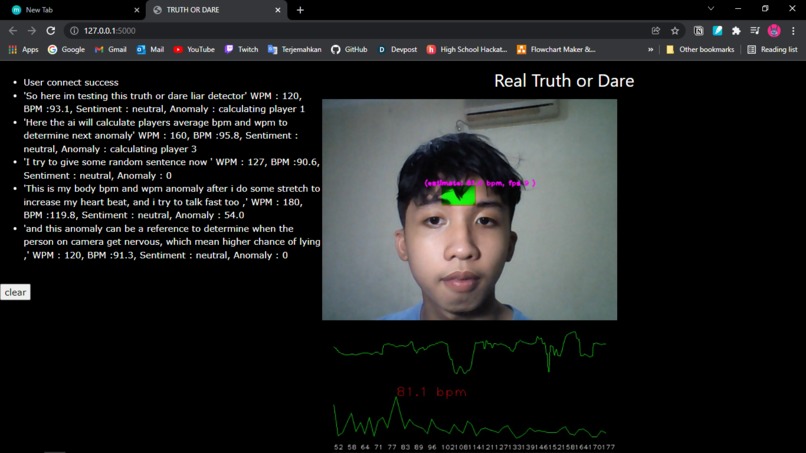
this web is actually replicating the process of detecting liar with traditional polygraph, based on heart rate, respiration rate, and how fast the subject talk. All of this things combined and create a level of anomaly in subject sentence or answer. Higher the anomaly, equal to higher chance of the subject is lying to you.
Heart bpm
First, we calculate your heart bpm, with a camera. Yes a camera. We calculate your heart bpm using opencv app and a trained model, to capture color fluctuation on high iso sens camera. We split this color fluctuation into r g b channel and pick the green one, bcs the green channel featuring the strongest plethysmographic signal, corresponding to an absorption peak by (oxy-) hemoglobin then blue channel (noisy), and red channel(noisy too). actually we can calculate the respiration rates, but bcs this hackathon only give 24 hours so i think its will be on my to do list and i will apply it after the hackathon period.
Speech wpm
Second, we calculate wpm in your speech ,we use speech_recognition library to convert ur speech into text, thanks for google api, than we calculate the length of the text and divide it by the time it takes, to get its WPM
Sentiment model
Third, we create a model again, but now its function is to predict the sentiment of the text. we create this using sklearn (to build a small model) , bcs tensoflow appear to be so heavy and will take so much resource on cloud later. The model type we use is NLP Model Naive Bayes, trained with over 100,000++ columns of a dataset, extracted using twitter api.
Average bpm & wpm
replicating polygraph process, the inspector should ask the subject simple question to determine average bpm & wpm, after some simple question (read the instruction on website), the real introgation can be start, the anomaly calculated by absoluting average bpm & wpm minus by bpm & wpm when they answer the question, then calculate it with the sentiment too
Integration
goodnews is, this app can be intregated with zoom, with little help from obs, but in the future we will add integrating to all video calls platform.
How to play TOD using this app?
- The default playmode is for 2 people, can be 1 introgator and 1 subject, or 2 ppl being an inspector and a subject then sw role after 1 question aswered.
- Please use a proper lighting, camera / webcam, and mic for better anomaly accuracy
- If u can set ur cam / webcam iso, set it into high iso until u can see some noise in the camera, but dont do it to much, bcs we want the app still can see ur face. (if in doubt just leave it regular, but with proper lighting).
- Now wait until the black box on your forehead change to green one
- if u seeing user connected and green box in your face, youre ready to go!
- Now see the red text in left side bar, read it!.
- read "The quick fox jumps over the lazy dog" until u see your speech get recorded
- Now swap into player two
- read "The quick fox jumps over the lazy dog" until u see your speech get recorded, again
- okay now you're ready to ask your friend the real question
- HAVE FUNNN TY TY!
- ps : you can integrate this app to zoom using obs virtual cam & obs audio
How we built it
- First I build the voice recognition program bcs its the easiest part of this project, then wrap it with flask, html and socket io.
- Second, I collect sentiment data from twitter and bring it to my jupyter notebook.
- Third, I build a sentiment model with sklearn & tensorflow, but the tensorflow model appear to be so heavy and take so much resource so i dump it, and use the sklearn one.
- Fourth I integrate the sentiment model to voice recognition program that I build previously.
- Fifth (the hardest), I build and integrate opencv using pretrained face model to locate face, then extract green channel raw data, using vector calculation with numpy and opencv.
- Sixth, I integrate all of it, importing all of it to main.py and started building route, etc
i already explain it above but here's the summary : we built it using sklearn, flask, opencv, and reading a bunch of remote plethysmographic article, then creating NLP model, after that integrating all of them(THE MOST HARDEST PART AAARGH)
Challenges we ran into
- integrating all of my app features is so hard (solved ofc)
- so many error while i try integrate opencv to website (solved) ## Accomplishments that we're proud of
- can integrate my app
- can do a bpm measure with webcam
- can build a great but light model (thanks to naive bayes sklearn)
- can replicate polygraph
What we learned
creating a project only for 24 hours is extremely hard T_T, and i learn so much more from this hackathon, btw this is my second hackathon & project
What's next for REAL TRUTH OR DARE
- integrate it to all videocall platforms
- host it, so everybody can use it!!!
End sentences
Now, while playing Truth or Dare, your friend can't lie anymore. (evil laugh)
Built With
- computer-vision
- flask
- google-colab
- google-web-speech-api
- jupyter-notebook
- machine-learning
- natural-language-processing
- numpy
- opencv
- pickle
- polygraph
- sklearn
- wave



Log in or sign up for Devpost to join the conversation.