-
-
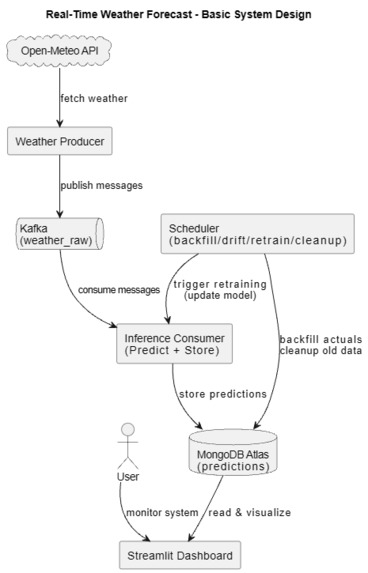
System Design of the project

Inspiration
Weather affects everyone daily, yet most forecasting tools are black boxes — they give you a number with no transparency into how it was derived or whether the model is still accurate over time. I wanted to build something end-to-end: a system that not only predicts weather in real time but also knows when it's going wrong and fixes itself automatically. The idea of a self-healing ML pipeline that runs continuously without manual intervention was what drove this project from the start.
What it does
Real Time Weather Forecast is a fully automated weather forecasting pipeline. It continuously fetches live weather data from the Open-Meteo API, streams it through a Kafka topic, and runs it through a trained ML model that predicts the next temperature. Every prediction is stored in MongoDB Atlas with a timestamp and model reference. A background scheduler then backfills actual temperatures once they become available, monitors the model for drift, triggers automatic retraining when accuracy degrades, and cleans up stale records. A Streamlit dashboard ties everything together, showing live KPIs, prediction vs actual comparisons, and pipeline health in real time.
How we built it
The system is built in Python and composed of several independent, loosely coupled services. Kafka runs in Docker and acts as the backbone of the streaming pipeline. A weather producer polls the Open-Meteo API on a schedule and publishes raw weather readings to a Kafka topic. An inference consumer listens to that topic, preprocesses the incoming data, runs it through the best-selected ML model, and writes predictions to MongoDB Atlas. The ML model itself was trained on 5 years of historical weather data and selected through a comparison script that evaluates multiple algorithms and saves the best-performing one. An orchestration scheduler handles backfilling actual temperatures, drift detection, retraining pipelines, and data retention cleanup — all running on timed intervals. The Streamlit dashboard reads from MongoDB and renders live insights across multiple pages.
Challenges we ran into
The biggest challenge was time and synchronization. Actual temperature values from Open-Meteo are only available after a delay, so predictions had to be stored with a null actual value and backfilled later by the scheduler — which required careful matching logic based on timestamps. Managing timezone-aware datetimes consistently across every layer of the stack (Kafka messages, MongoDB documents, API responses, and the dashboard) without silent offset bugs was a constant source of friction. Getting drift detection tuned correctly was also non-trivial — it needed to be sensitive enough to catch real model degradation but stable enough to not fire on normal variance. Keeping all services running in sync across Kafka, MongoDB, and the scheduler without race conditions or dropped messages required significant testing and hardening.
Accomplishments that we're proud of
The most satisfying achievement is that this is a genuinely self-sustaining system. It runs, predicts, evaluates itself, detects when it starts underperforming, retrains, and keeps going — all without any manual intervention. Building a full MLOps cycle from data ingestion to drift monitoring to retraining inside a single project, rather than just training a model in a notebook, is something few projects at this scale attempt. The Kafka streaming pipeline being fully containerized with Docker and the clean separation between producer, consumer, scheduler, and dashboard also gives us something that actually resembles a production-grade architecture.
What we learned
This project was a deep dive into MLOps beyond model training. The biggest lesson was that deploying a model is only the beginning — keeping it accurate over time is the real work. Implementing drift monitoring and automated retraining gave a practical understanding of why production ML systems fail silently in the real world. On the infrastructure side, working with Kafka for the first time showed just how powerful event-driven architectures are for decoupling services. Managing MongoDB for time-series data, handling offset-aware datetimes correctly, and orchestrating multiple long-running Python processes also added real depth to the overall engineering skill set.
What's next for Real Time Weather Detection
The immediate next step is expanding predictions beyond temperature to include humidity, precipitation probability, and wind speed. On the infrastructure side, replacing the local scheduler with Apache Airflow would make the pipeline far more observable and fault-tolerant. Adding anomaly detection on top of the existing drift monitor would allow the system to flag unusual weather events automatically. Deploying the full stack to a cloud provider with a public URL for the dashboard is also a priority, so the system can run 24/7 without depending on a local machine. Longer term, multi-location support and a REST API layer would open the project up as a usable service rather than just a personal pipeline.
Built With
- apache-zookeeper
- docker
- kafka
- kafka-python
- mongodb-atlas
- numpy
- open-meteo-api
- pandas
- pymongo
- python
- scikit-learn
- streamlit

Log in or sign up for Devpost to join the conversation.