-
-

Output of a webcam C270 taking pictures and processing through Xilinx Pynq Z2
-

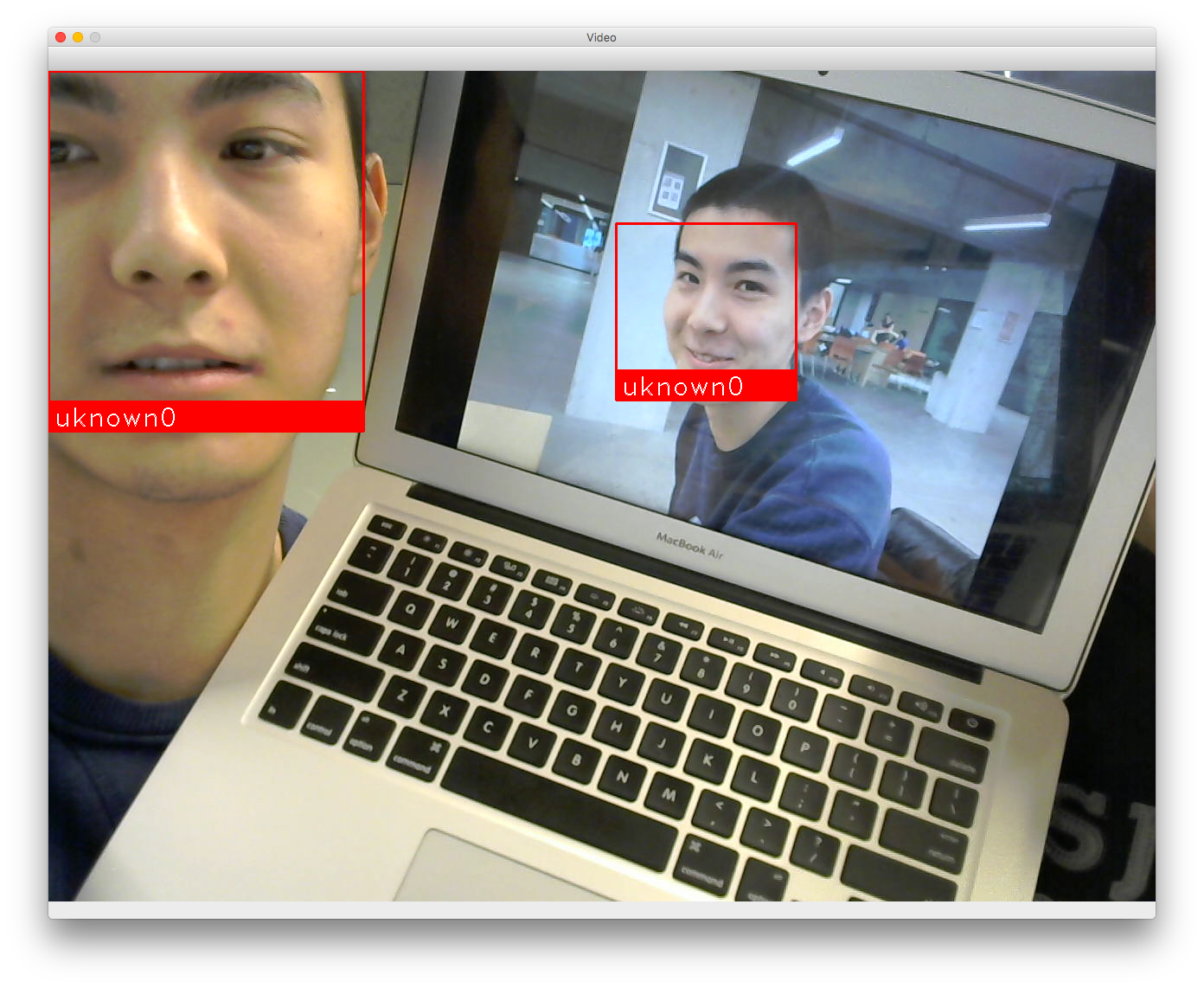
Program recognizes the same face, even when they are displayed on different media
-

Recognize different faces


Inspiration
Prosopagnosia, also known as face blindness, is a cognitive disorder that impairs one's ability to recognize familiar faces and makes everyday communication difficult for its patients. As current machine learning algorithms enable relatively accurate facial and speech recognition, we realized the potential of incorporating these technologies to design a system that can recognize faces for prosopagnosia patients and help them through daily interactions.
What it does
Our project uses speech and facial recognition models to identifies key personal information, such as names, from self-introduction speech and labels faces captured on the webcam with such information.
The webcam continuously detects facial objects in the frame and labels them with a rectangular box. Detected faces are analyzed by the imported face recognition library which compares it with all known faces to calculate a difference value with each. If the difference value is less than 0.5 for a particular face, then the face is classified with the name of that known face. Otherwise, the face is labelled as a new face, and the system waits for user audio input. Once the user says their name, speech recognition converts the audio input into words, which is analyzed by the natural language processing module to identify entities, such as names, addresses, etc. This information is stored in a database and is used to label the face on the screen, thus achieving the purpose of identifying the unknown face for the user.
How we built it
To develop this project, we modified and integrated facial recognition, speech recognition and natural language processing modules.
"Face_recognition" project on Github (https://github.com/ageitgey/face_recognition), which includes dlib and OpenCV, was imported, and threshold similarity values for classification was modified based on trials. Additionally, we created a training sample database using images of our own faces.
For speech recognition, we incorporated the "speech_recognition" project on Github (https://github.com/Uberi/speech_recognition) which uses Google Cloud Speech API to convert spoken words into texts.
To comprehend the user's speech from the laptop's microphone, we wrote a Python program that imports the Spacy Natural Language Processing (NLP) module to recognize the type of words, such as name, address, organization, etc. We created a list database that stores the information filtered by the Spacy NLP module
Challenges we ran into
We had difficulties integrating and uploading the speech, facial, and webcam modules onto the PYNQ board.
Accomplishments that we're proud of
- Successful modification and integration of recognition and NLP models ## What we learned We learned to use:
- Spacy NLP module
- Work with speech and facial recognition models
- Pandas database
- Configure and use PYNQ Z2 ## What's next for Real-time Speech and Facial Recognition
- Improve the classification accuracy of the natural language processing module
Built With
- cv2
- face-recognition
- pynq
- python
- spacy
- speech-recognition

Log in or sign up for Devpost to join the conversation.