-
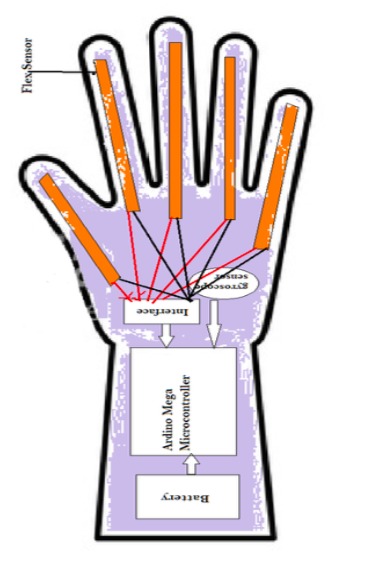
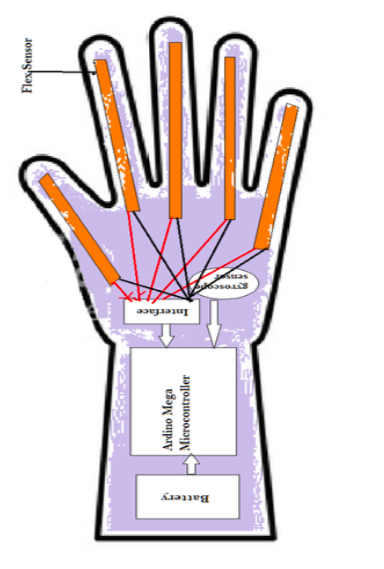
schematic diagram of the glove
-

sensor-packed glove that recognizes signs
-

Training dataset image for 'How are you' (the background is subtracted and hand is segmented from it)
-

Training dataset image for 'Sign' (the background is subtracted and hand is segmented from it)
-

Training dataset image for 'Fine' (the background is subtracted and hand is segmented from it)
-
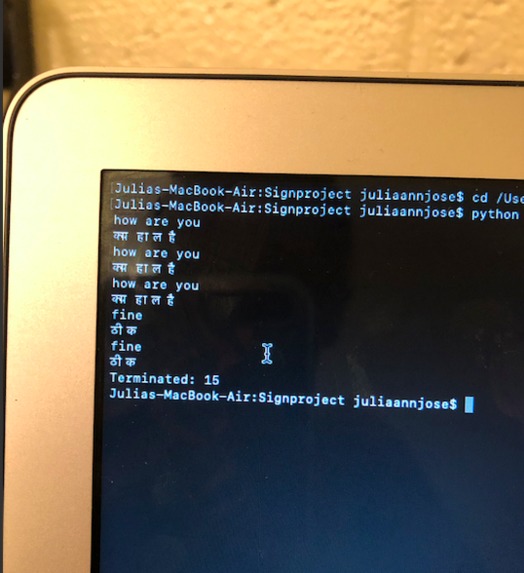
The system recognizing the sign 'How are you' and 'fine' in English and Hindi
-

The system detecting the sign 'fine' as seen on the left window
-

The system detecting the sign 'Hello' as seen on the left window







Introduction
This project presents two methodologies for Real-Time Sign Language Recognition - a sensor-based approach which is a glove that converts sign to speech and an image-based approach that uses computer vision and machine learning algorithms for sign language recognition.
What it does
This system detects and recognizes a certain number of signs/gestures and converts it into speech (English and Hindi).
How I built it
I used two approaches to this problem. 1) A sensor-based approach: This is a sensor-packed glove that converts sign to speech with the help of a Bluetooth module. As part of the sensor-based approach to Real-Time Sign Language Recognition, a glove that is aimed at helping people with impaired hearing and people who have difficulty in speaking/talking to others is developed. The following are the functionalities of the glove:
A. It detects and recognizes the sign language gestures of the wearer. B. It converts the sign language to speech.
The gloves can provide information on the position, rotation, orientation of the hand along with information on the orientation of individual fingers. This information can be further used to make the glove detect and recognize various sign language gestures. The glove is battery powered and uses flex sensors and gyroscope and accelerometer sensor to measure bending of fingers or the orientation of hands and fingers ignorer to detect the words made by the wearer and sends them to a mobile application via Bluetooth for converting them to speech.
2) Image-based approach: In the Image-based approach to Sign Language Recognition, cameras are used for real-time video streaming of gestures. The image-based approach comes with a number of advantages over the sensor-based approach. The image-based approach is more cost-effective. Also, wearing the glove system is very cumbersome. The flex sensors are very delicate and special care must be given when using them. The Image-based system requires just a camera, hence making it much more comfortable. With the help of a camera (or webcam), dynamic images are sent as input to the image-based system. The video sequence, which is a series of frames of images, is then analyzed. Google’s Inception v3 model is then used for image classification purposes of these sign gestures.
Although the image-based approach has advantages over the sensor-based approach, it comes with a number of problems. Variation of light in images, hand segmentation from the rest of the background, etc to name a few.
Challenges I ran into
Some of the challenges that I ran into were: Working with the flex sensors, which are very sensitive; Variations of light in images, hand segmentation from the background, distinguishing and separating hand and face/background, etc.


Log in or sign up for Devpost to join the conversation.