reAgent
📰 Featured in Enter.pro HackPrinceton Builder Series →
The thesis
Most agent failures in 2026 are not model failures, they are context failures. Small bugs and hallucinations compound across agents until the system tricks itself, and by the time you notice, the cloud bill has already shipped. AI cannot one-shot a multi-agent swarm. Catching the cascade before it starts is still a human's job, and the tooling for doing that work has not caught up to how fast people are deploying agents.
reAgent closes that gap. It treats your architecture as a graph and runs real algorithms over it, depth-first search for runaway-cost loops, Kahn's algorithm for the actual critical path, an LLM-as-judge for the design decisions math can't see. The whole product is harness engineering, context gates, fallback routers, schema-constrained handoffs, model right-sizing, evaluation loops, human-in-the-loop, Tool RAG, and memory management, all seamlessly combined into something you can see and edit before committing.
The proof: describe a problem, get an architecture
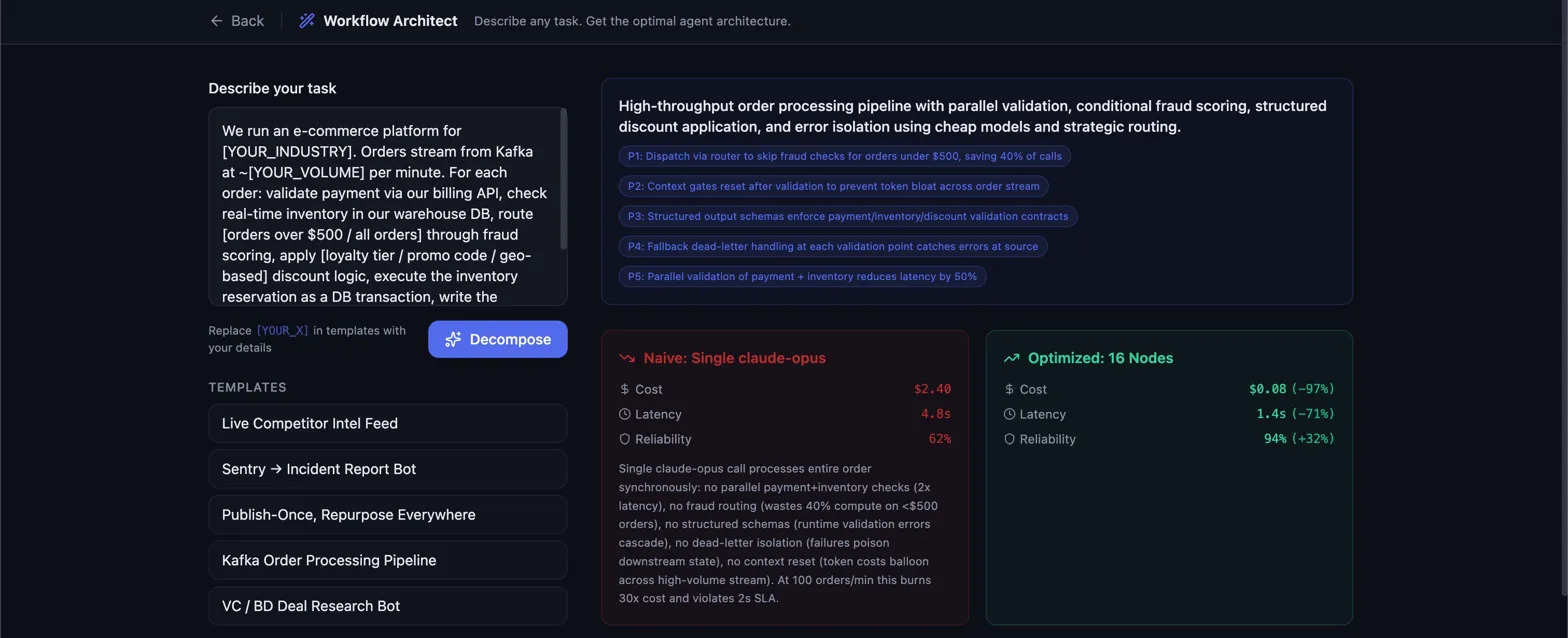
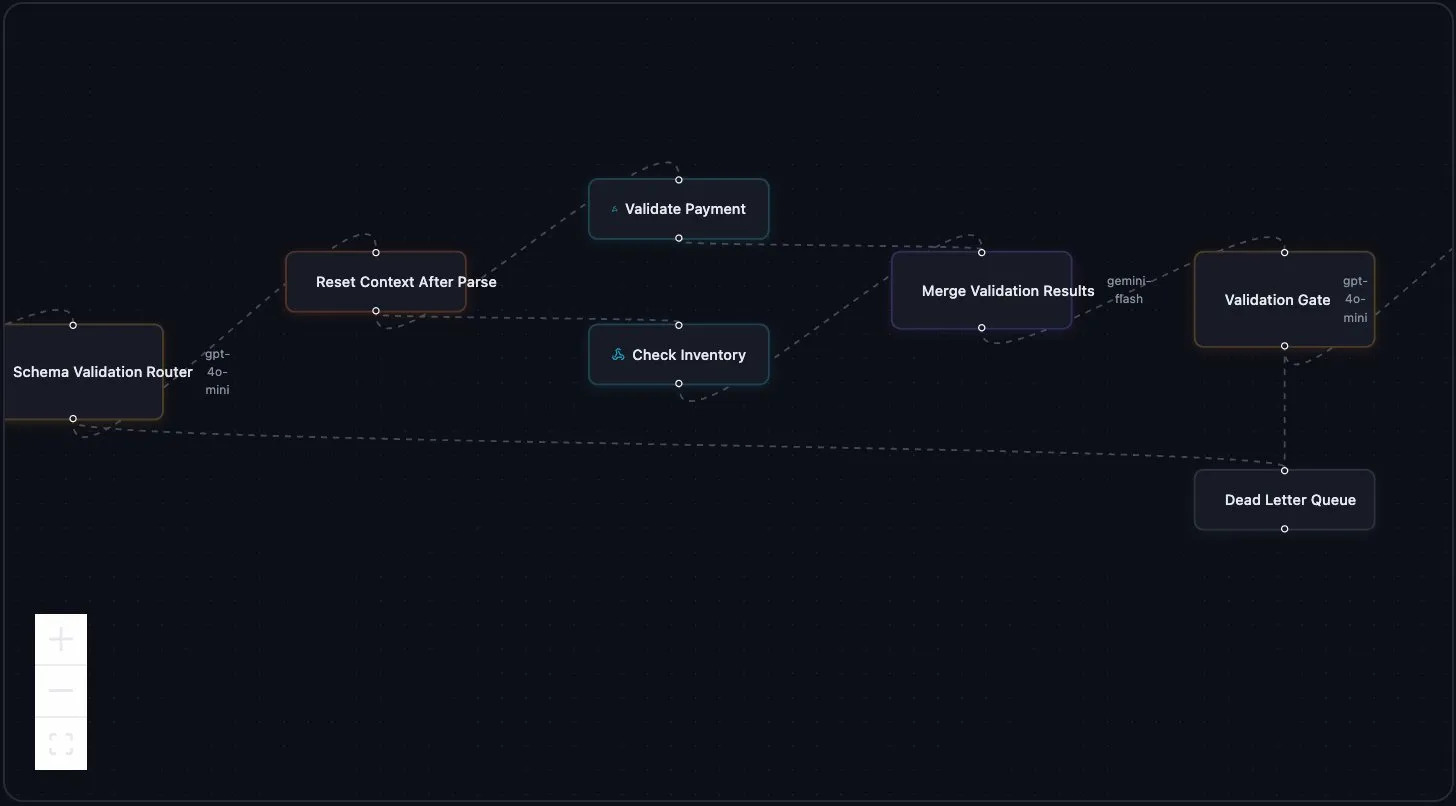
The sharpest demo is the Workflow Architect Sandbox Mode. Half the fun was watching it produce things we didn't expect. Paste a plain-English problem ("high-throughput e-commerce order processing with parallel validation, fraud detection, 2s SLA") and the system decomposes the requirement into named patterns (value-threshold routing, context-gate compression, structured output schemas, fallback with dead-letter queue), then generates the full graph.
The delta against the naive baseline of one Claude Opus doing it all:
| Metric | Naive | Optimized | Delta |
|---|---|---|---|
| Cost | $2.50 | $0.08 | −97% |
| Latency | 5.8s | 1.4s | −76% |
| Reliability | 52% | 94% | +42pp |
Modeled cost from per-node pricing × call counts; modeled latency from critical-path traversal; reliability estimated by judge with internal rubrics. The reasoning the system gives ("no parallelization, fragile JSON parsing, no routing wastes fraud checks on low-value orders, no context compression burns tokens on full payloads") reads like a senior engineer's review notes because the LLM-as-judge in Pass 2 is doing exactly that work, grading the user's workflow and prompt engineering skills.
Inside the harness
Fourteen node types, each mapped to a pattern AI engineering teams currently implement by hand:
- Executors with per-node model selection (gpt-4o, gpt-4o-mini, gemini-flash, claude-opus) cost-aware right-sizing so you don't pay Opus tax for a regex job
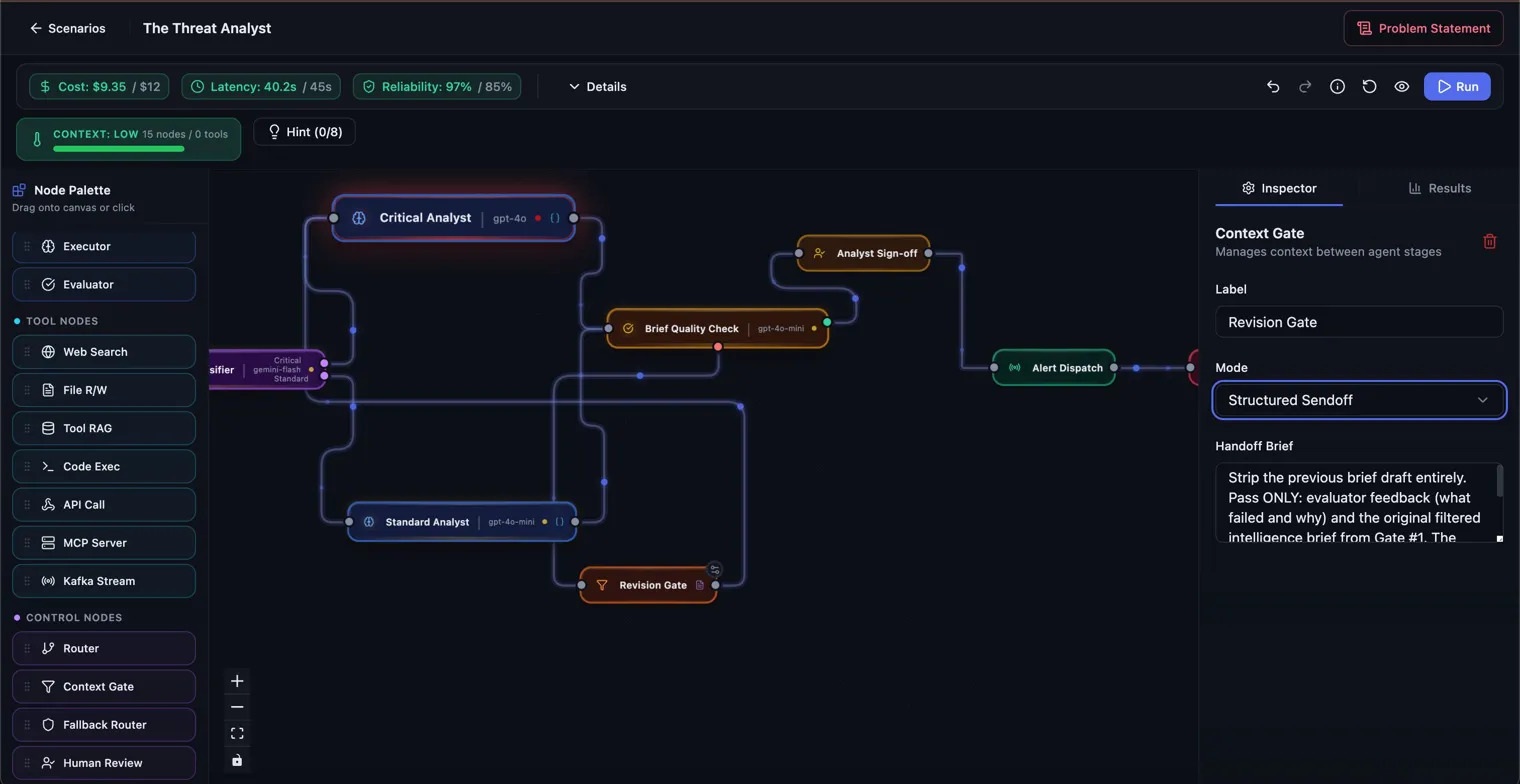
- Context Gates with three modes: pass-through, structured sendoff, and intel filter. Structured Sendoff lets you write an explicit handoff brief between agents ("strip the previous draft, pass only evaluator feedback and the original brief"), surfacing context isolation as a UI primitive, not a buried config field
- MCP Servers that aggregate tools behind a single coordination point, with a reliability bonus when 3+ tools are bundled (matching real MCP design pressure in production)
- Tool RAG for selective tool retrieval when the catalog gets large, so unnecessary tools don't bloat the context.
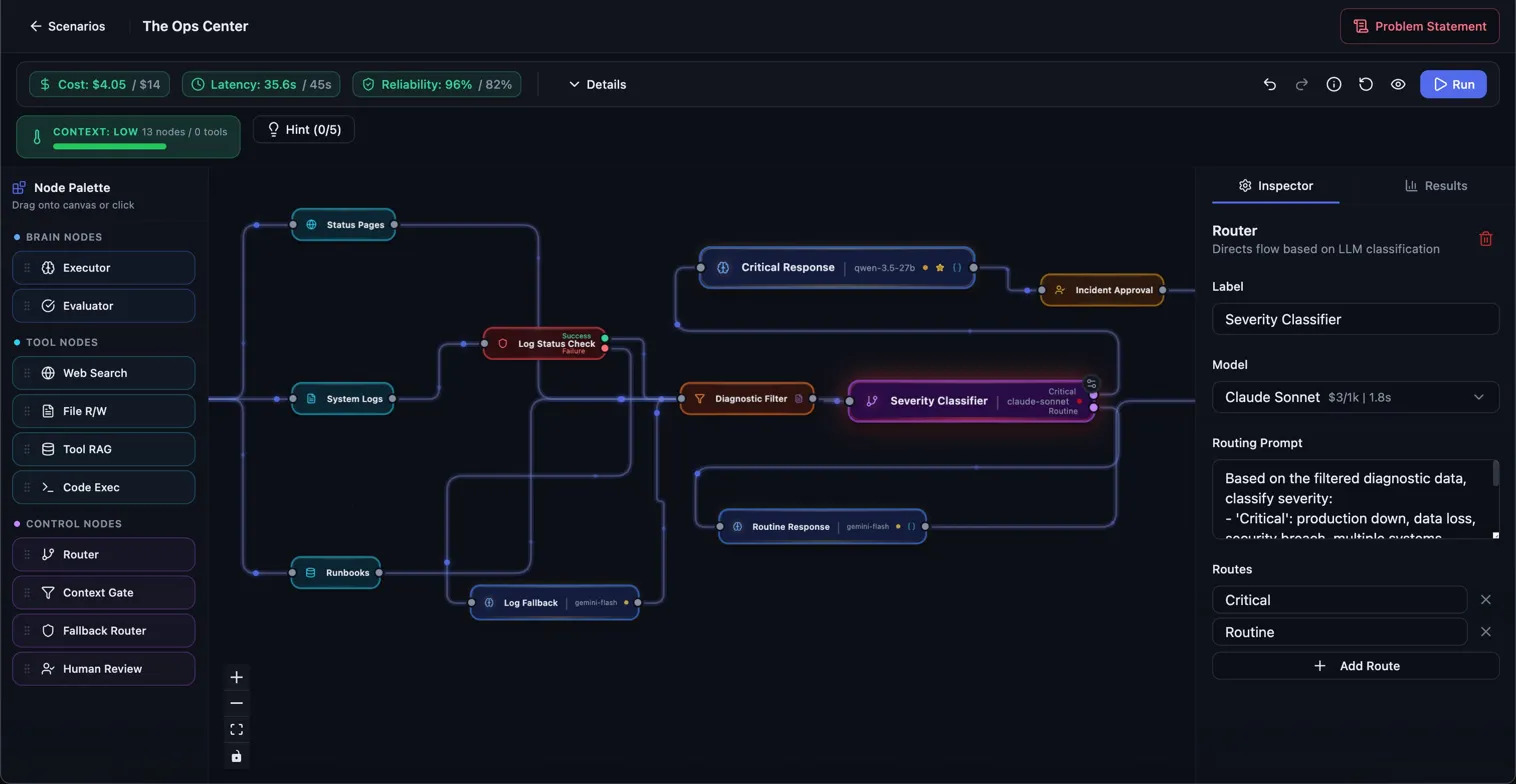
- Routers for value-thresholded dispatch and Fallback Routers for graceful degradation
- Evaluators for in-pipeline quality gates. LLMs are naturally biased toward their own output, making eval loops absolutely essential.
- Human Review with approval, edit, and escalation modes for decisions that genuinely need subjective perspective
- Kafka Stream ingress for real production hookup
Live telemetry runs every time you change the graph. The Context Thermometer literally shakes when an architecture crosses budget, because abstract token warnings get ignored and a UI that visibly objects does not. The more expensive a model, the bigger the node on the graph. High throughput nodes are instantly visible as many wires are connected to them.
The dual-pass evaluator
Click Evaluate and two checkpoints run.
Pass 1: deterministic. Depth-first search detects cycles. Kahn's algorithm topologically sorts the graph and computes the actual critical-path latency, not summed node times. Costs come from a pricing table calibrated to current model APIs.
Pass 2: LLM-as-judge. Claude Sonnet 4.5 reviews the architecture the way a senior engineer would. Are you using Opus where Haiku would do? Did you skip a context gate where one was needed? Does this actually solve the problem you described? The judge sees the graph, the task, and the Pass 1 metrics together. It also grades prompts and JSONs for agent-to-agent communication.
Both must clear. You cannot pass the math with a nonsensical graph; you cannot pass the logic check at $50 per run. Gaming one breaks the other.
Scenarios
A curated library of named problems with grading rubrics, hints, and pass criteria:
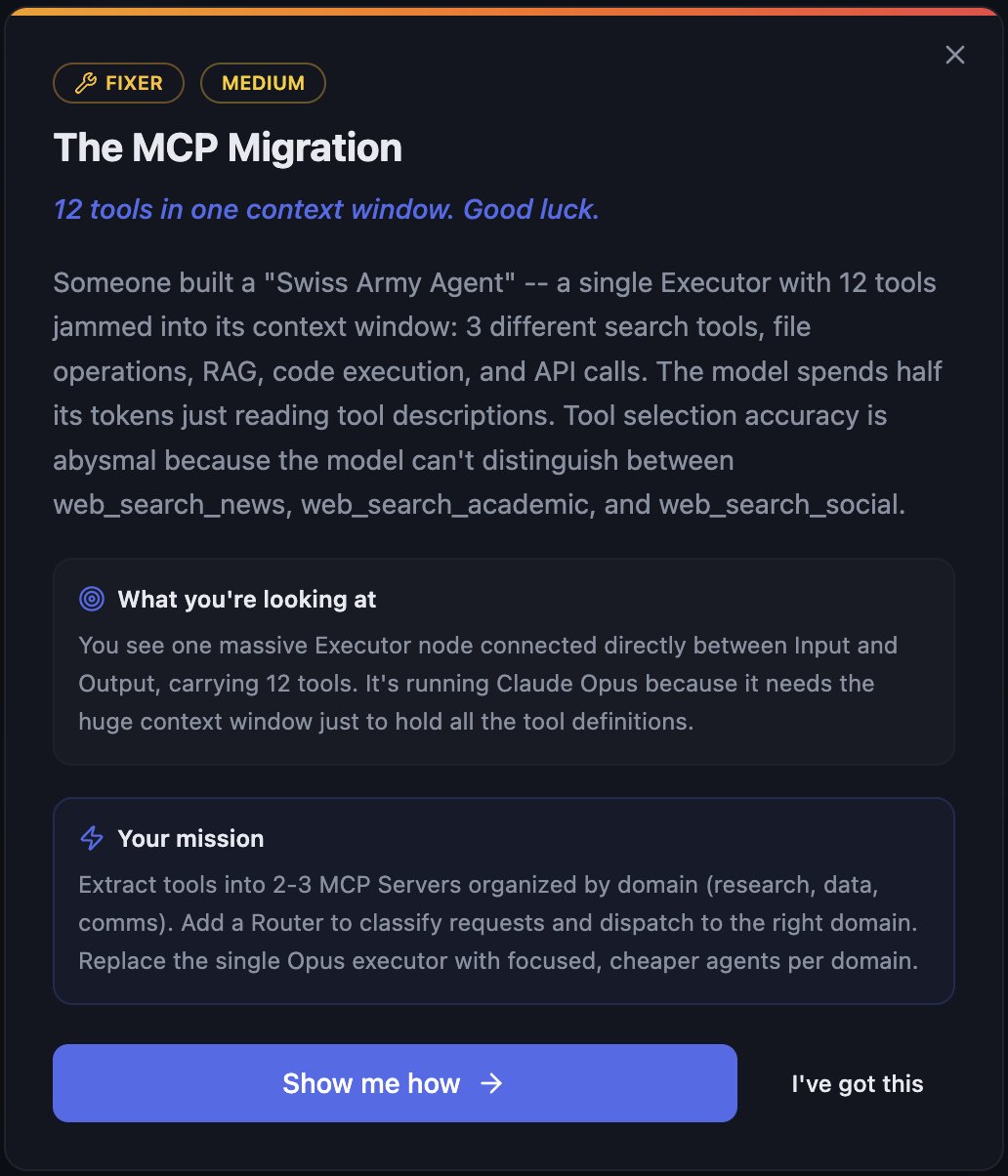
- Fixer scenarios debug a broken architecture inherited from a fictional previous engineer. The Bloated Swarm (too many specialists). The Gold Plater (Opus where mini would do). The MCP Migration (refactor scattered tool executors into MCP servers). The Threat Analyst (a SOC pipeline bleeding money and credibility).
- Architect scenarios build from scratch under explicit constraints. The Content Machine. The Safety Net. The Due Diligence Engine.
Difficulty tags (Easy / Medium / Hard) and explicit pass conditions let users self-pace through the patterns.
Built with
React + React Flow + Zustand for the canvas. Supabase Edge Functions on the backend. LangGraph as the underlying agent runtime. Claude Sonnet 4.5 as the judge in Pass 2. Classical graph algorithms (DFS, Kahn's) for the deterministic pass. Enter.pro for cloud orchestration and LLM sandbox enviornment.
The research that informed the design
Alongside the build, the team ran a study on how information actually moves between agents through natural language. Using scenarios from the CraigslistBargains dataset and Qwen as the model, we compared two communication modes: standard text-channel transmission and direct injection of the sender's hidden states into the receiver's forward pass. The gap between resulting representations was measured with a composite metric combining Jensen–Shannon divergence and cosine distance.
The token-level finding is load-bearing: cosine distance between sender and receiver representations stays low and stable, but JS divergence spikes catastrophically on individual ambiguous tokens. Sender and receiver agree across stretches of perfect alignment, then a single high-entropy word blows up the shared distribution mid-message.
This is the mechanistic explanation for why reAgent's Structured Sendoff edges work. Free-text channels between agents are fragile, and the fragility concentrates on specific tokens not spread evenly across a message. Schema-constrained handoffs (typed JSON between nodes) eliminate the high-entropy tokens by construction. The schema does not make agents smarter; it removes the surface area where they fail to understand each other.
The paper measures the failure mode. The product reduces it.
What's next
- Edge ambiguity warnings : surface specific free-text edges where drift is most likely, as inline UI hints. Direct translation of our paper's finding into a product affordance.
- Thinking mode scenarios: Right now static graphs don't capture dynamic agent behavior (re-planning, recursion depth varying with input)
- Communication brittleness scoring in Pass 2, grounded directly in the research
- Telemetry-driven scenario generation instrument deployed reAgent architectures and use logged inter-agent messages as raw material for new scenarios
A note on what we built
The first time the Workflow Architect generated a non-trivial graph, what came back mirrored exactly what we'd been adding to production agents by hand! Evaluation loops that verify outputs without somebody babysitting them, human review at the decision points that need a subjective call, tool control to minimize MCP costs, and context gates so the next agent in line gets curated input instead of a wall of upstream noise. That was the moment it clicked. This isn't a productivity tool. It is the harness pattern made explicit, and the explicitness is the point.
Verifiable engineering for a stack that's otherwise built on hope.
— Advik Lall, Mehek Niwas, Abhi Patel, Daniel Zhang · 36 hours
Please view these links for our agent communication interpretability research writeup:
experiment website html: https://mehek-niwas.github.io/paper-viewer.html
experiment paper link: https://drive.google.com/file/d/1VUAu0G2b3-uN2JC-unfZETI8ppfUSYLB/view
experiment code link: https://colab.research.google.com/drive/1O-zzEfulfzTH7HjTTdw2lbSn0u3gCQJm
This is our colab we used for results: https://colab.research.google.com/drive/1vPlaUgaQ_1GrtVWm3kKt2LW1h59dq-NC?usp=sharing
🏆 Winner, Best Use of Enter.pro · HackPrinceton Spring 2026





Log in or sign up for Devpost to join the conversation.