-
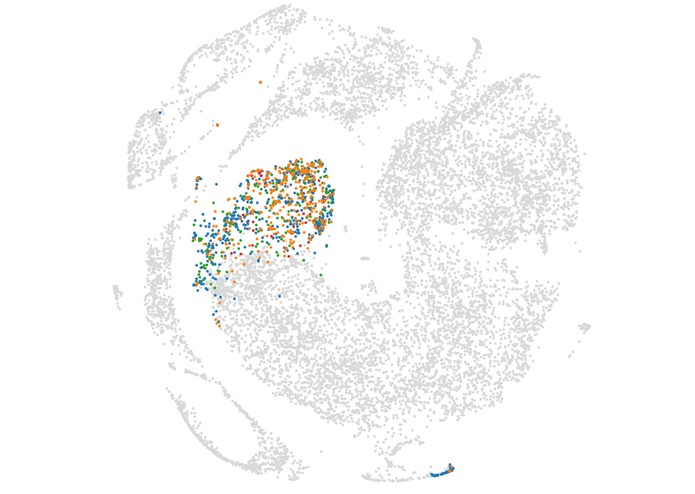
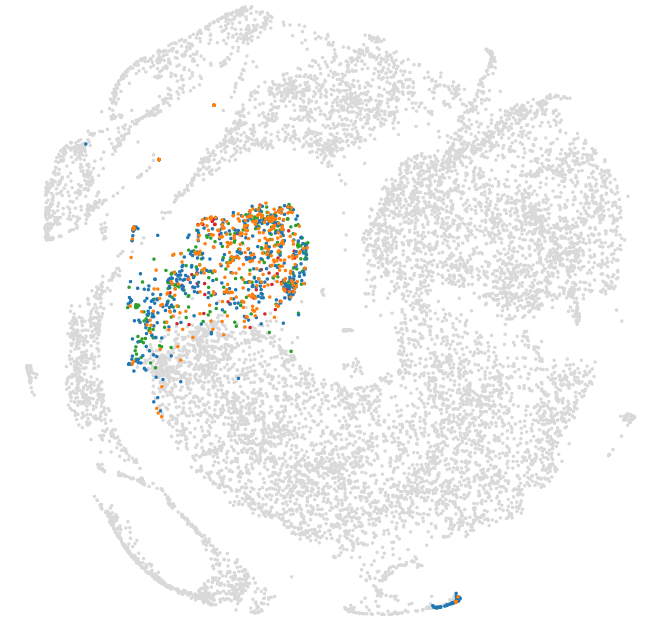
Embedded article corpus
-
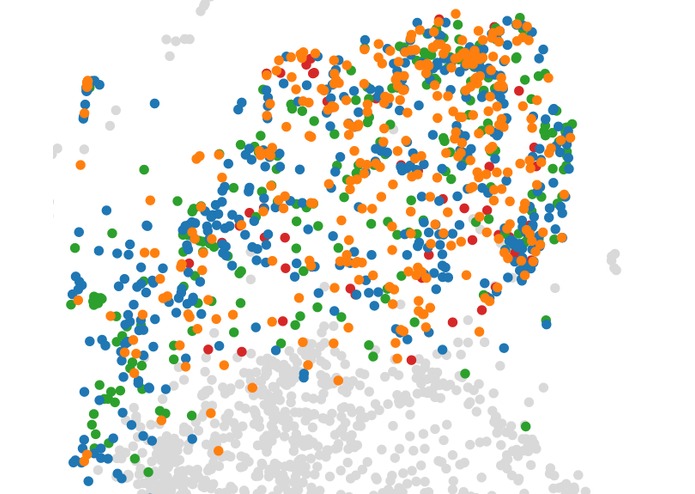
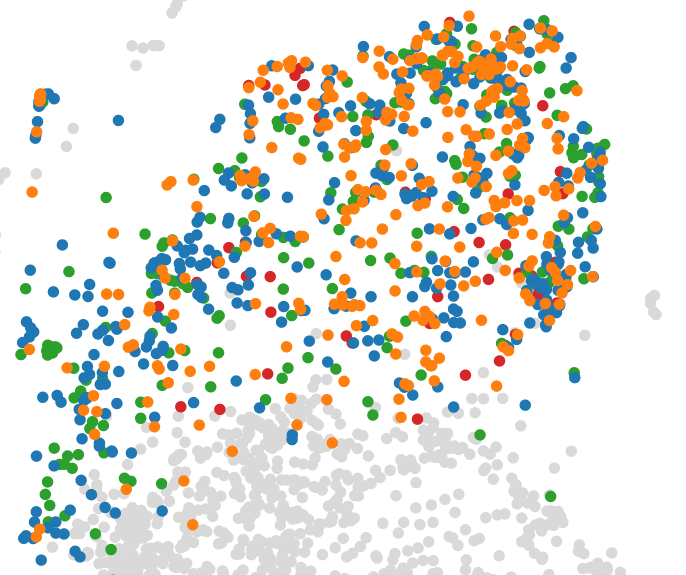
Our user articles
-
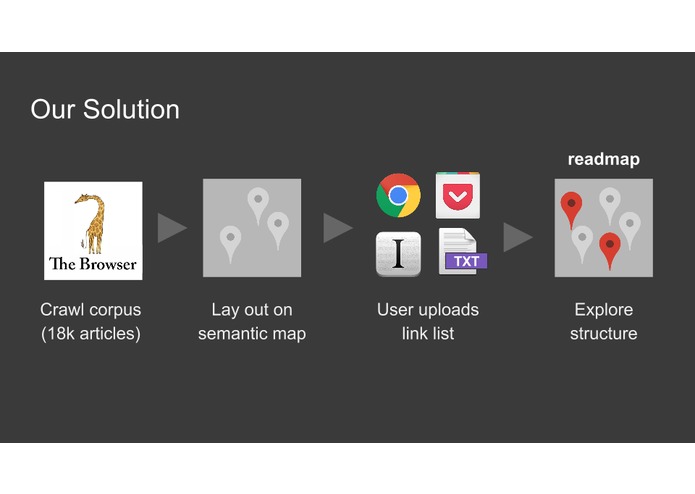
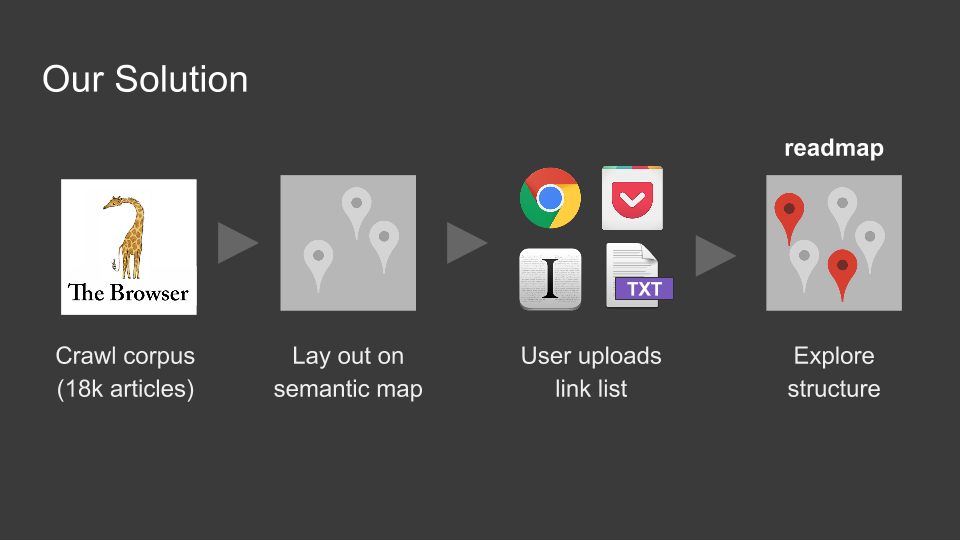
Our solution
-
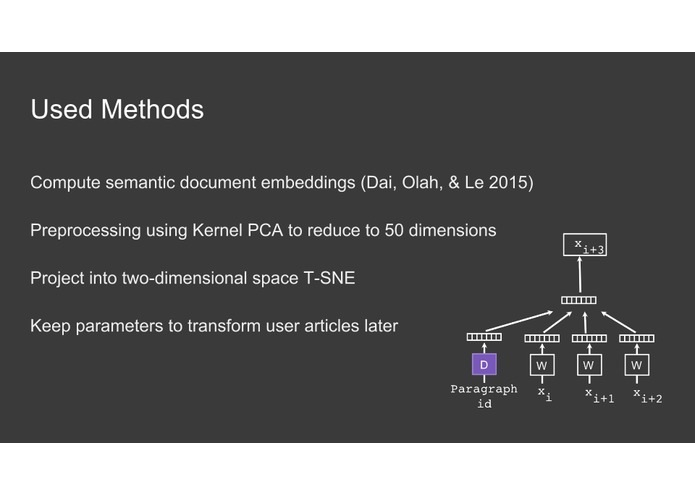
Used methods

Inspiration
The internet provides a vast amount of information to read and enjoy. But discovering the relevant pieces is hard.
What it does
The user can submit a list of documents he has read. Based on his reading history we can recommend similar articles or even articles that expand one's horizons.
How we built it
Our article corpus consists of 18.000 articles crawled from sources like Pocket and The Browser. These articles are then embedded using Doc2Vec. The articles provided by the user are transformed into the same vector space. This allows us to search for new articles which are similar to his own articles. By reducing the highly dimensional into a two-dimensional vector space using Kernel-PCA and TSNE we can provide an intuitive visualization of the article distribution.
Challenges we ran into
It took some time to understand the new techniques. Additionaly we worked hard to reduce our train times.
Accomplishments that we're proud of
The document embedding worked extremely well. On top of this, we provided an intuitive way of exploring and expanding your own topic sphere.
What we learned
Document embeddings, Visualization of highly dimensional data.
What's next for readmap
We plan to publish a demo on the internet and share it with the machine learning community.
Built With
- d3.js
- doc2vec
- python
- scikit-learn
- tsne





Log in or sign up for Devpost to join the conversation.