-
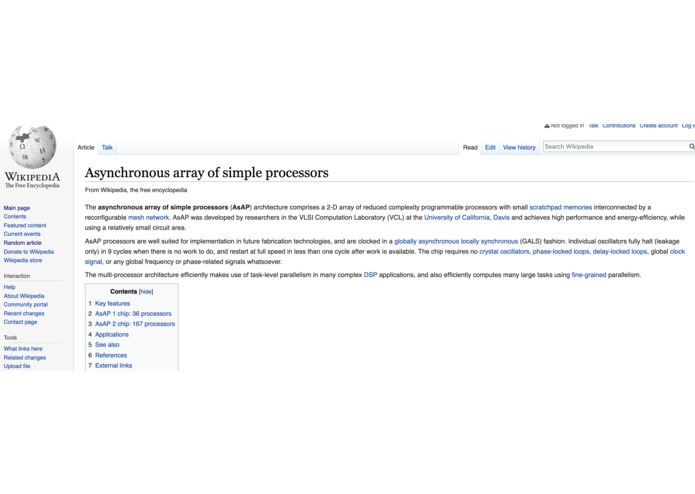
1. Finds difficult article
-
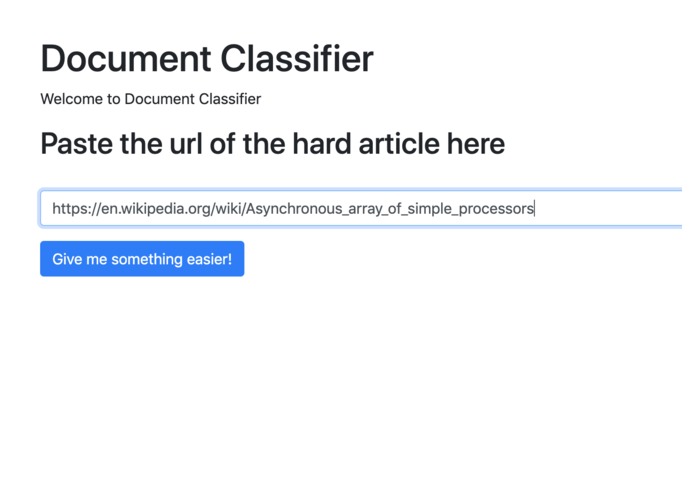
2. Pastes url into ReaDiscover.net
-
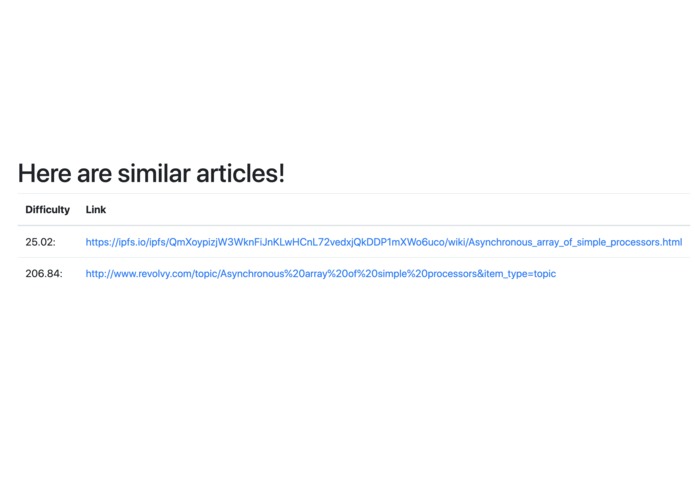
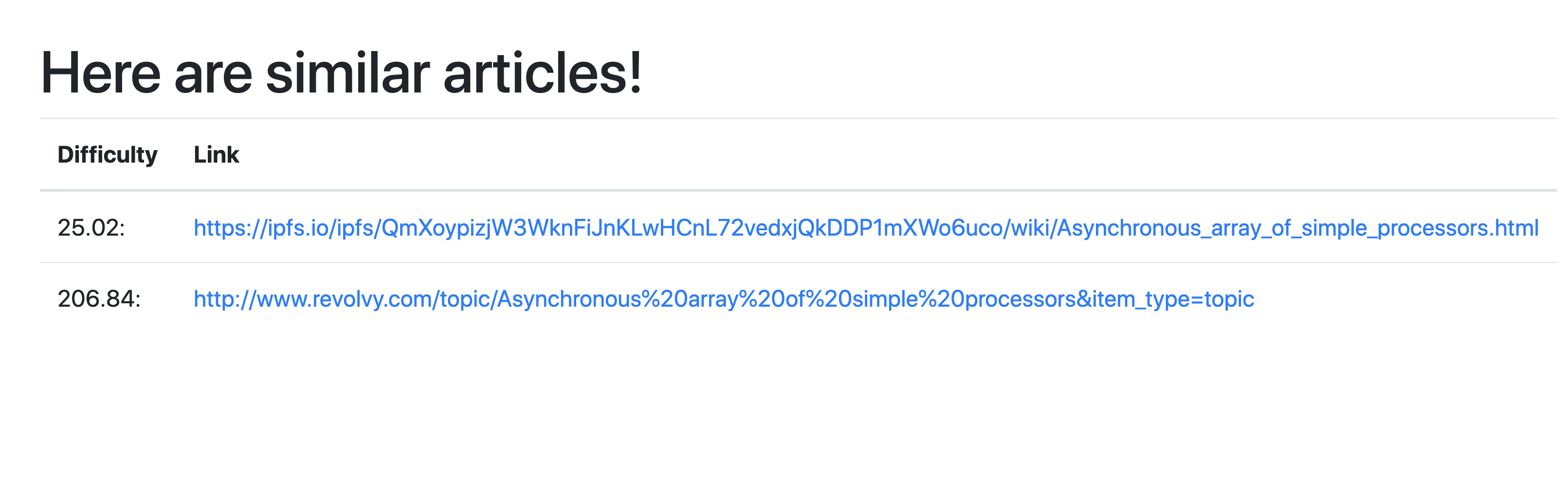
3. Chooses the url with the desired difficulty
-
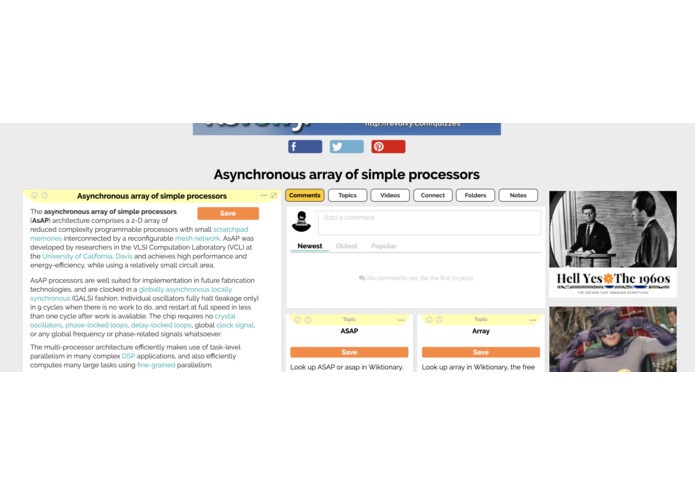
4. Reads better suited article
Inspiration
Every student looks for solutions for their problems in scientific articles. Often however the articles are too sophisticated for his skills/needs. Then the poor student’s search continues, reading through piles of articles and scientific mumbo jumbo until he finds what he needs. However it doesn’t have to be that way…
What it does
When a user reads an article and find that the reading difficulty doesn't match their level of comfort, they can use our service to find other articles on the same topic but with a different reading difficulty. This will be useful for anyone reading articles. Meaning the potential user base is very broad.
How we built it
With python script as main processor for the request on the Node.JS backend. The script is making API calls to Microsoft Cognitive Services to find the main topics of the text through text analysis. Then through a Bing search it’s finding relevant articles and their URLs then again to evaluate each of them in terms of reading difficulty. The results are then parsed to the frontend formatted as a table with clickable links.
The service is hosted on google cloud services using the ReaDiscover.net domain
Node.js,
Python scripts works by:
Call Bing Topic modeling engine to get top topics and format to one string
Recall Bing Search to get as least 4 similar web pages removing 3 lowest topic words with each iteration
Return the difficulty using flesch reading ease of similar web pages along with url.
Html:
WIP: Call database(firebase) to request results
If no previous results, calls python script
Calculate and return results of python script
Database (Firebase):
Receives requests for urls. If url does not exist, runs python script. Otherwise return url and difficulty score.
Challenges we ran into
Combining Python and Node.js Using Microsoft services. Hosting the server on google cloud services and setting up the domain.
Accomplishments that we're proud of
The solution is using a lot of different algorithms and services that combined gives a really great solution. Combining all of these different technologies has been a challenge but with a satisfying result.
What we learned
How to use microsoft services in python. Different methods of calculating difficulty of text. Routing API calls and user input correctly and making a representable result in html/Jade Making a successful project in a very time constrained situation. Focusing on JUST making it work.
What's next for Readiscover
Add database so it will be possible to process the requests faster. Have a loading screen for a more interactive user experience. Integrate with PDF reader to find alternative articles for the PDF article you’re reading. Browser extension.

Log in or sign up for Devpost to join the conversation.