Inspiration
I love reading, especially fantasy. But there is this annoying thing that always happens to me: I pick up a new book from a series a few months after finishing the previous one, I’ve usually forgotten some character or how we got to some place. I used to rely on fan wikis to catch up, but that was always a gamble—there was a 50/50 chance I’d get spoiled, either because the wiki had spoilers or I just clicked where I shouldn't have. Then, when AI got big, I tried asking ChatGPT. It helped, but it wasn't perfect. Sometimes it was spot on, other times it hallucinated, occasionally it still spoiled me. And sometimes just it didnt had any information about the series I was reading. This is what my app solves.
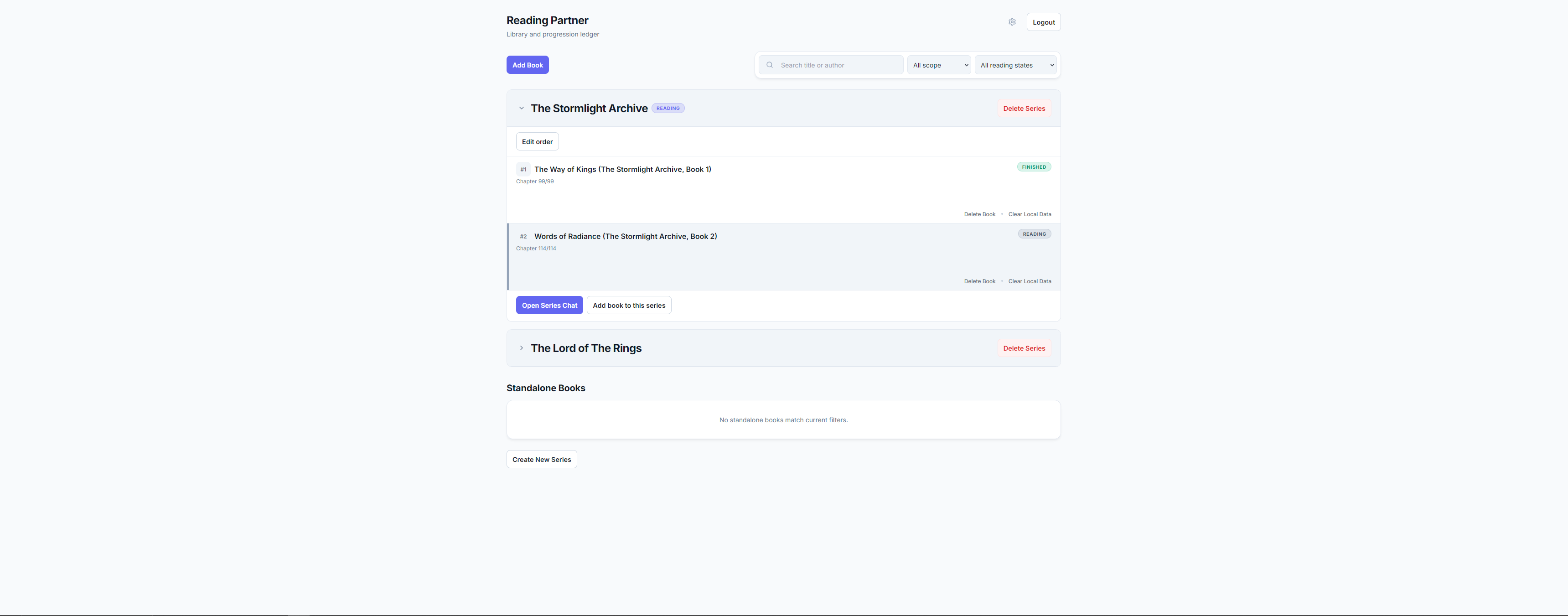
What it does
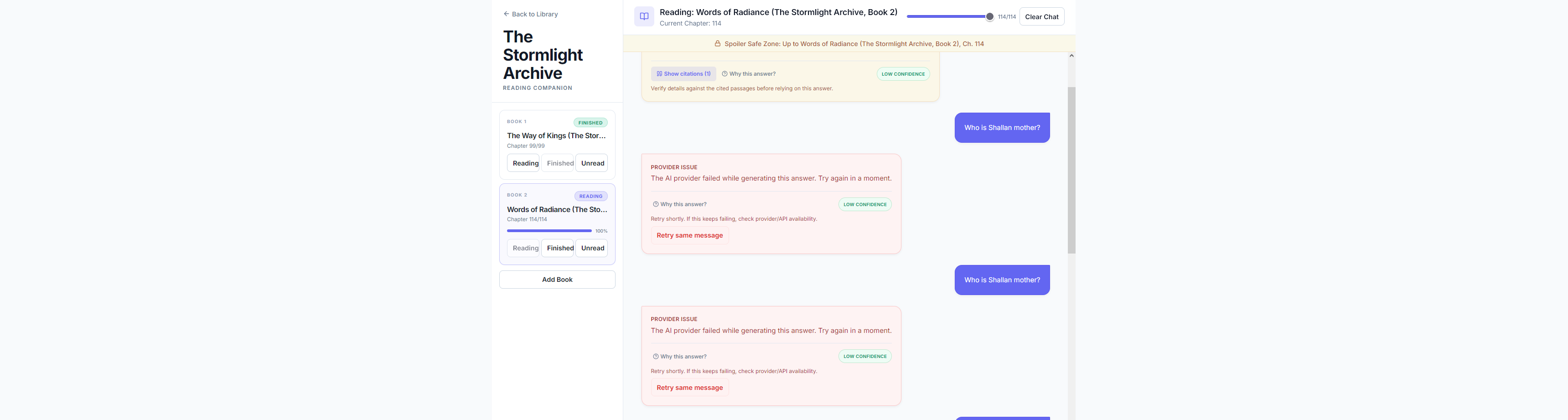
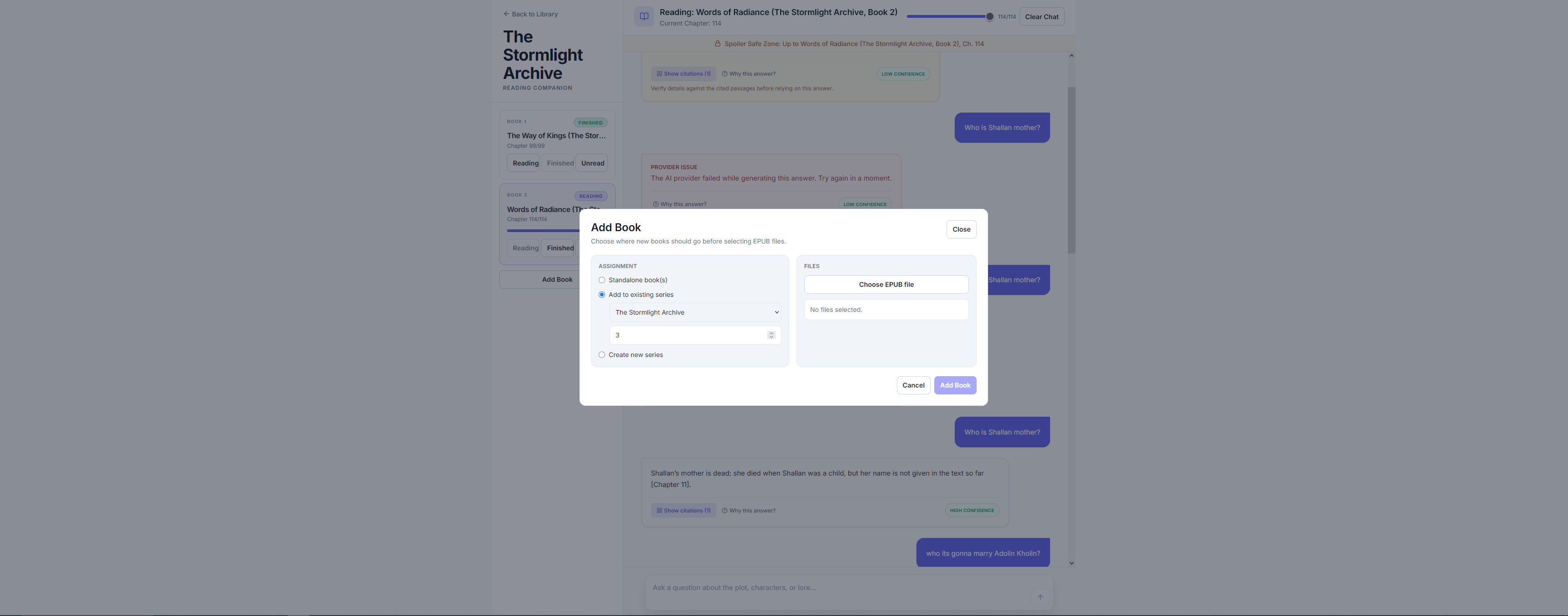
Users upload DRM-free EPUBs—either standalone books or entire series—set their current reading progress, and ask questions. The app retrieves relevant passages strictly from content the user has already read (across all books in a series) and generates spoiler-free answers with citations.
Architecture
https://i.imgur.com/4gFhkJ3.png
How we built it
I used Kilo Code with Claude Opus 4.6 and ChatGPT 5.3 Codex. Honestly, about 95% of this was "vibecoded" with me supervising and guiding the AI.
Challenges we ran into
Finding free models I could use for a hobby project was tough. I will add a way for users to add their own API keys if people are actually interested in using this.
Also, making sure the answers were actually correct was a challenge, getting the right chunk sizes, making sure the context window wasn't too big or too small, and ensuring the retrieval model could actually find the answers.
It still gets some answers wrong when the book isn't super explicit. For example, when facts contradict each other depending on the character's POV, it really confuses the model. I didn't use the most powerful models available, I just used whatever I found free. I am sure with better models the answer will be close to 100% correct.
Accomplishments that we're proud of
I saw the discord annoucement 18 hrs before deadline, and I had nothing done, I made it, I am proud of that. Designing the whole architecture alongside the AI was genuinely fun. Testing it and fixing the issues felt like a real achievement. I think I’m getting much more comfortable working with AI tools, though I still need to nail down a better workflow. I haven't done many "vibecoded" apps like this, so I'm still learning the ropes.
What we learned
I kind of had an idea about how to train a model to learn from a source, but I’d never actually done it. This seems like a very frequent use case, and it was cool to finally build it out.
What's next for Reading Partner
I am 100% going to use it myself; it really solves a personal pain point. Depending on if other people find it useful, I’ll keep working on it—adding functions, polishing the AI, and fixing bugs. Maybe I'll allow users to use their own API keys or buy a proper domain.
I'm going to keep working on the accuracy to try and get it close to 100%. I think it can be improved a lot, especially since I only had about 12 hours to work on it (I didn't see the hackathon post until Thursday noon and just started building) and I ahd to sleep. I also need to test it with better models. I am sorry if the model keep sending error when you try it
Built With
- hono
- openrouter
- react
- supabase
- typescript

{kind=link}
Log in or sign up for Devpost to join the conversation.