-
-
Reactor Guard Dashboard 1
-
Reactor Guard Dashboard 2
-
Reactor Guard Dashboard 3
Inspiration
In safety-critical industries, “good enough” monitoring quietly becomes normal—until the day it isn’t. I kept coming back to a simple question: if a reactor was slowly drifting into danger at 2 a.m., would anyone actually notice in time?
Most plants still lean on static alarms, siloed dashboards, and tired humans watching lines crawl across screens. I wanted to see what would happen if we gave that operator a true AI copilot: something that understands patterns over time, across reactors, and can take action using Elasticsearch and Agent Builder instead of just adding one more blinking light.
ReactorGuard is my answer to that “what if?”—a project to prove that agents plus time-series data can genuinely move the needle on industrial safety.
What it does
ReactorGuard is an autonomous safety agent for industrial reactors built on Elasticsearch and Agent Builder.
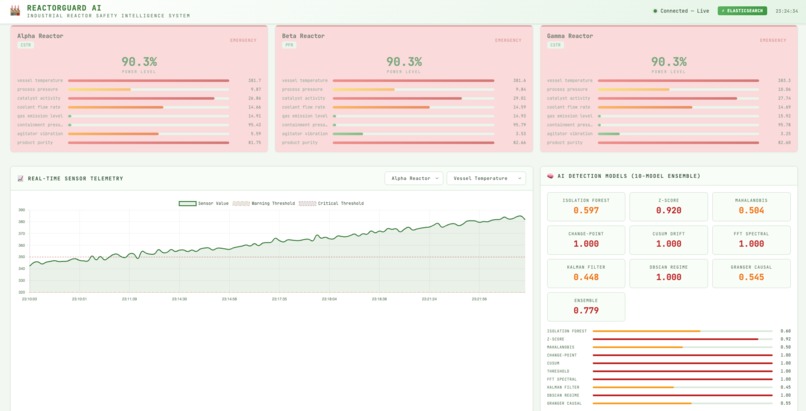
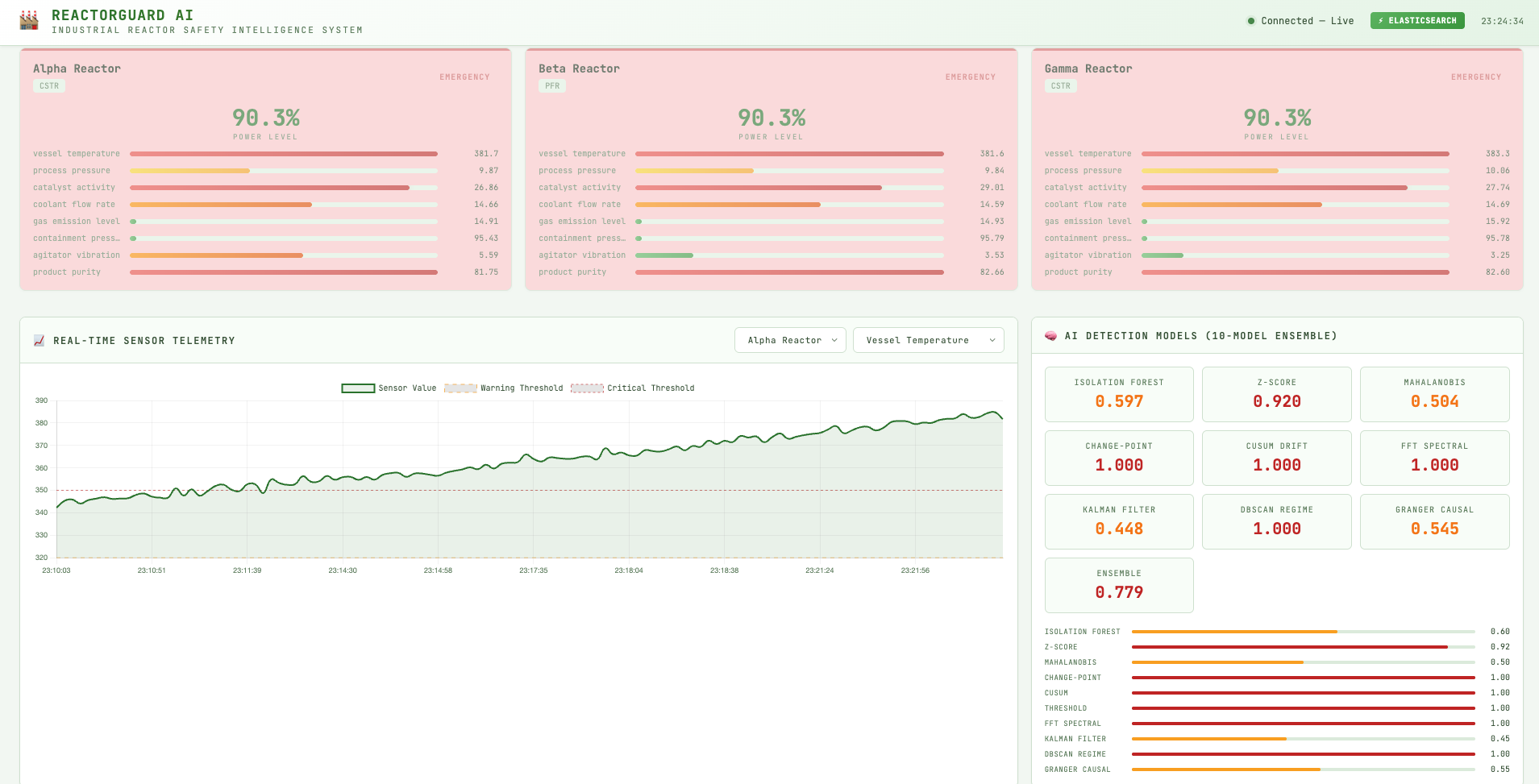
- Simulates realistic IoT telemetry for three reactors (8 sensors each, 24 readings/second) with built-in failure scenarios like overheating, pressure spikes, and gradual catalyst decay.
- Streams this data into Elasticsearch, where a multi-model AI engine scores each timestep for anomalies, drift, changepoints, and proximity to safety thresholds.
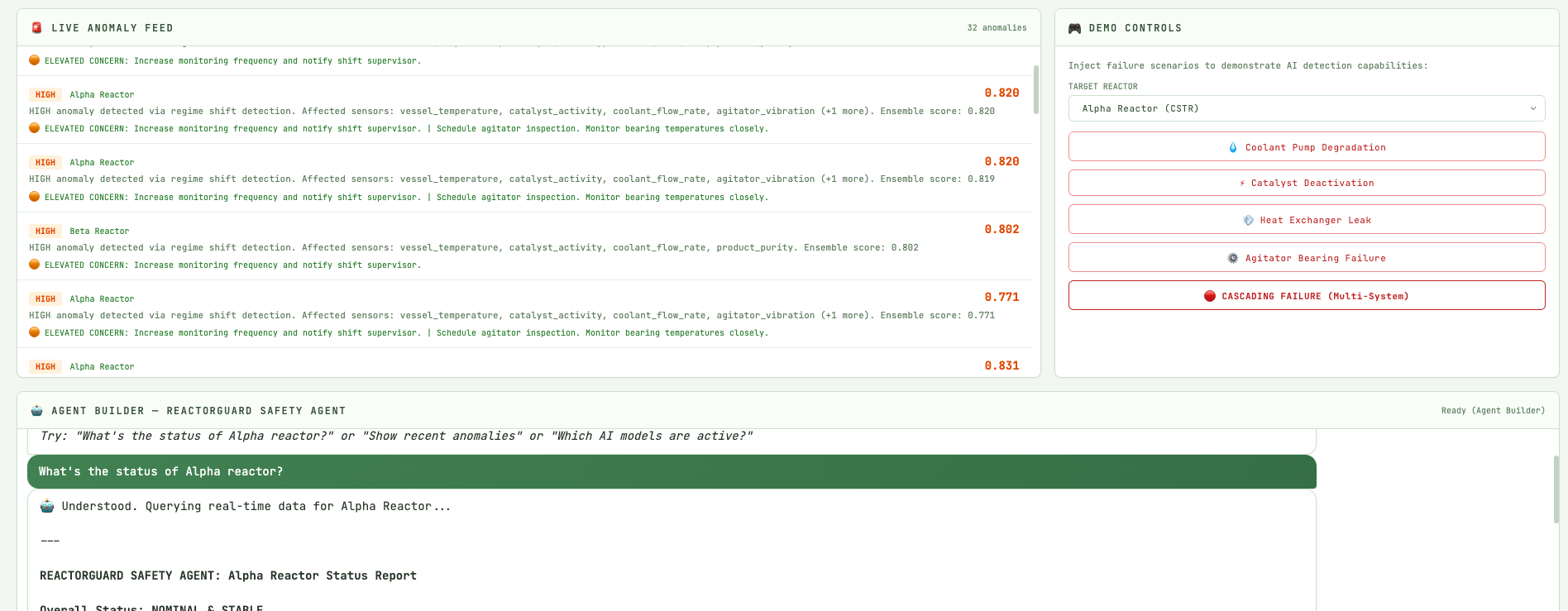
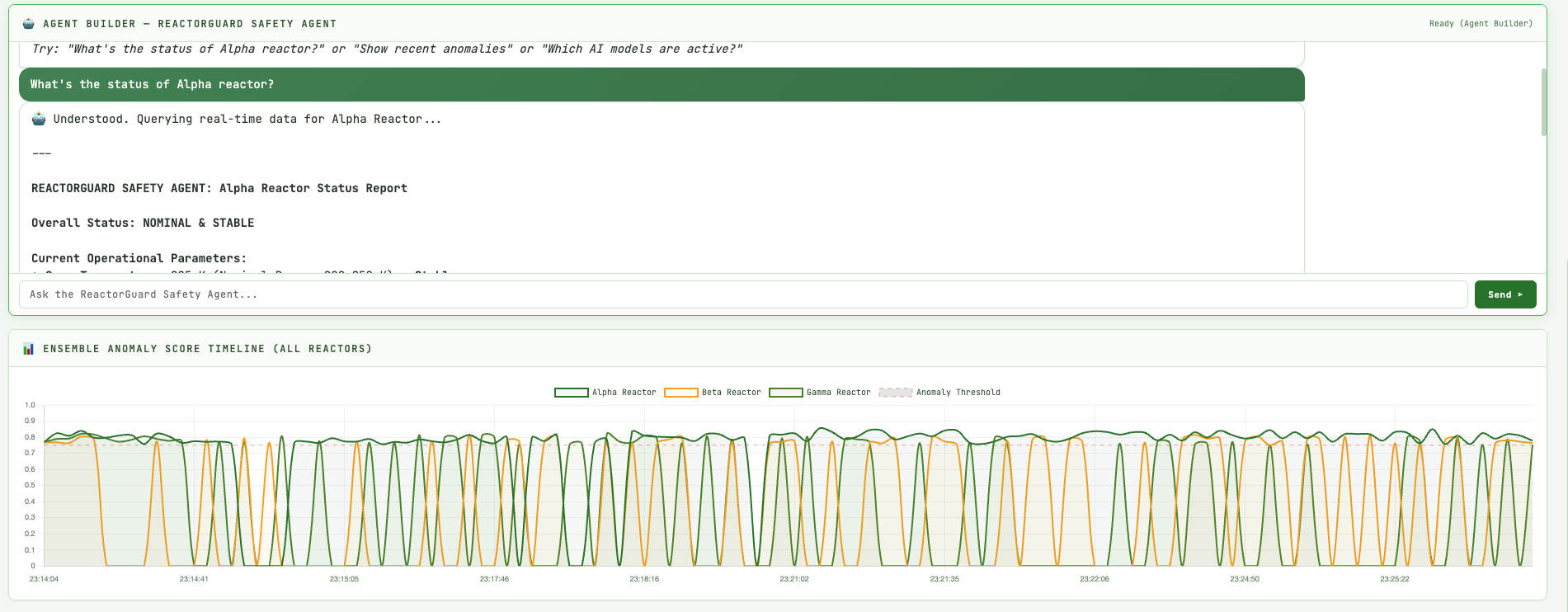
- Visualizes everything in a real-time web dashboard with live charts, anomaly feed, and “failure injection” controls so you can watch the system respond.
- Uses Agent Builder tools and workflows to query ES|QL, correlate anomalies across reactors, open incident records, and log AI actions and recommendations.
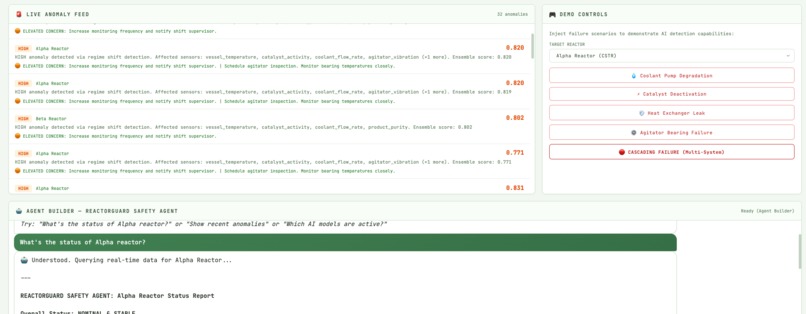
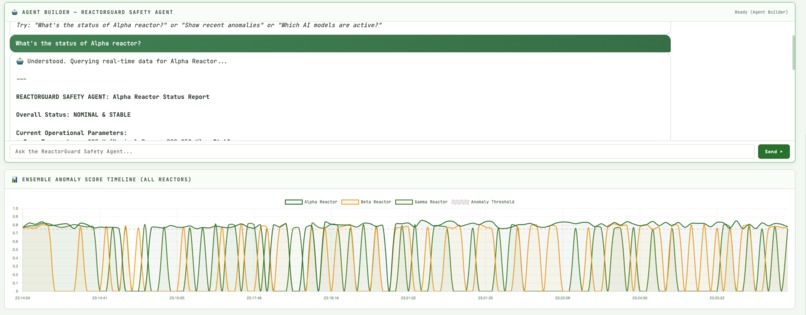
- Exposes a “ReactorGuard Safety Agent” you can chat with: ask “What’s going on with reactor-beta in the last 10 minutes?” and it responds with ES-backed context, scores, and suggested actions.
Instead of another monitoring screen, ReactorGuard acts like a junior safety engineer that never gets tired, always has the logs, and knows how to use the right tools.
How I built it
Everything is wired end-to-end around Elasticsearch and Agent Builder:
- IoT simulator & ingestion: A Python simulator models three reactors with correlated sensors (temperature, pressure, coolant flow, etc.) and injects realistic failure modes. Data is batched and sent into Elasticsearch indices for sensor readings, anomalies, incidents, and AI actions.
- AI anomaly engine: A dedicated engine combines several detectors (Isolation Forest, z-score, Mahalanobis distance, changepoint, CUSUM, threshold proximity, and more) into a weighted ensemble. Each reading produces a score and severity that gets indexed back into Elasticsearch.
- Real-time dashboard: A Flask + Socket.IO app subscribes to the live stream, plotting multiple reactors, highlighting anomalies, and exposing switches to trigger failures on demand for demo and testing.
- Agent Builder integration: A YAML config defines ES|QL tools (e.g., reactor status, sensor trend analysis, anomaly search, cross-reactor comparison) and index search tools. A Python client calls the Agent Builder APIs to provision these tools, create the “ReactorGuard Safety Agent,” and hook it up to Elastic Workflows for anomaly detection, incident response, correlation, and reporting.
The result is a closed loop: simulator → Elasticsearch → AI engine → workflows → Agent Builder agent → back to operators.
Challenges we ran into
- Making “fake” data feel real: Random noise would have been easy, but useless. I spent a lot of time tuning correlations (e.g., temperature vs. pressure vs. coolant flow) so that failures look like something a process engineer would actually recognize, and so the ensemble has to work to catch them.
- Balancing model complexity with real-time performance: It’s tempting to keep adding detectors, but each comes with a cost. I hit a few bottlenecks and had to profile, prune, and simplify feature sets so we could maintain real-time behavior while still getting meaningful signal.
- Designing good tools for Agent Builder: Turning “I want the agent to understand recent anomalies on reactor-gamma and correlate them with incidents” into concrete ES|QL tools and workflows took iteration. Early versions were either too broad (noisy results) or too narrow (missed important context).
- Keeping the pipeline robust: Mapping issues, schema mismatches, and timestamp problems all surfaced once everything was wired together. Getting from “it runs locally” to “it’s reliable enough for a live demo” was a continuous debugging exercise.
These challenges forced me to think like both an ML engineer and a reliability engineer.
Accomplishments that I’m proud of
- A truly end-to-end system: This isn’t just a model or just a dashboard. It’s a full loop from synthetic plant data → anomalies → incidents → AI-driven recommendations, all powered by Elasticsearch and Agent Builder.
- An agent that takes real action: The ReactorGuard Safety Agent doesn’t stop at explaining charts. It queries ES|QL, correlates events, opens incident records, and writes its own actions into an index so you can audit exactly what it did and why.
- Clear fit to the hackathon’s strengths: The project squarely targets “time-series and geo aware agents” and “tool-driven agents,” demonstrating how an LLM-powered agent can sit on top of fast time-series data and reliably orchestrate tools and workflows.
- Demoability under pressure: With a single command, judges can spin up the simulator, watch a failure unfold live on the dashboard, then jump into Agent Builder to ask the agent what happened and see the workflows in action within a three-minute window.
For a hackathon timeline, getting all of this wired together and stable is the part I’m proudest of.
What I learned
- How to think in terms of agents + tools, not just prompts: Agent Builder pushed me to design ES|QL tools and workflows that the agent can combine and reuse, instead of stuffing everything into a single system prompt.
- Elasticsearch as an “agent brain” for time-series: Storing raw metrics, anomaly scores, incidents, and AI actions in one place made it much easier to build explanations, correlate events, and close the loop.
- The importance of explainability in safety: I learned to treat “why did we raise this alert?” as a first-class requirement, not a nice-to-have. That’s why the agent cites actual readings, thresholds, and timestamps from Elasticsearch.
- How to design for graceful degradation: ReactorGuard can still run in a local-only mode when Elasticsearch isn’t available, which made development and debugging much smoother and highlighted the importance of sane fallbacks.
What’s next for ReactorGuard
- Operator feedback loop: Allow operators to confirm, downgrade, or dismiss incidents and store that feedback for retraining the ensemble and improving workflow decisions over time.
- Richer, cross-system workflows: Extend Agent Builder workflows to integrate with ticketing/maintenance systems so a critical anomaly can open a work order, not just a row in an index.
- Domain expert calibration: Work with actual process/safety engineers to refine sensor ranges, failure modes, and recommended actions so ReactorGuard can move from “demo-grade” to “pilot-ready.”
- Packaging and reuse: Containerize the full stack and add configuration so other teams can plug in their own time-series data (not just reactors) and reuse the same Agent Builder patterns for their domains.
Built With
- elastic-agent-builder
- elastic-workflows
- elasticsearch
- gemini
- python
- python-socketio
- socket.io
Log in or sign up for Devpost to join the conversation.