-
-
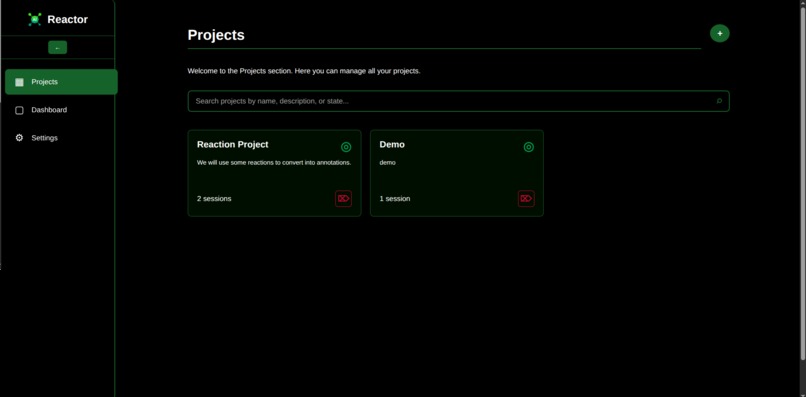
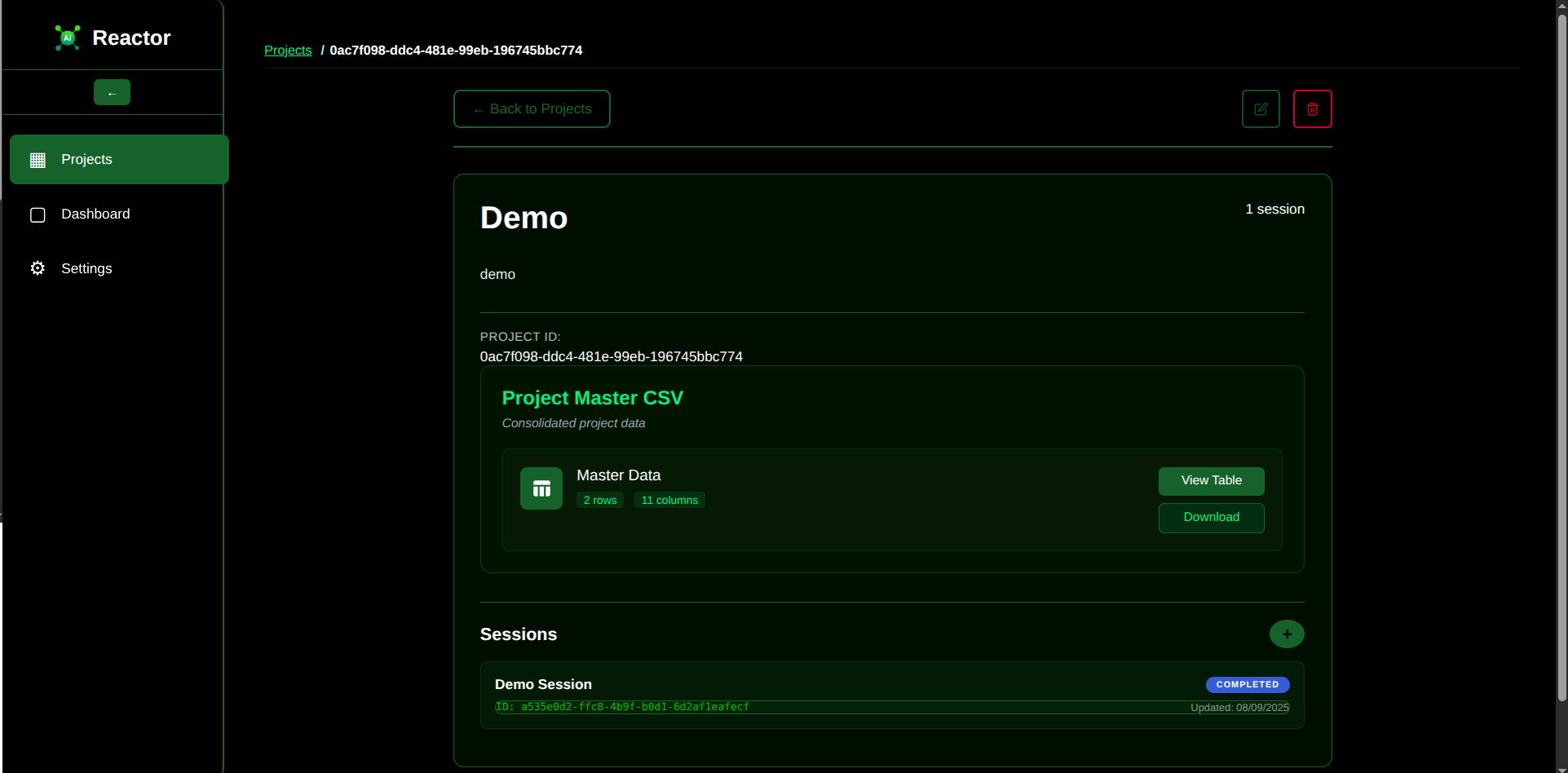
Projects Page
-
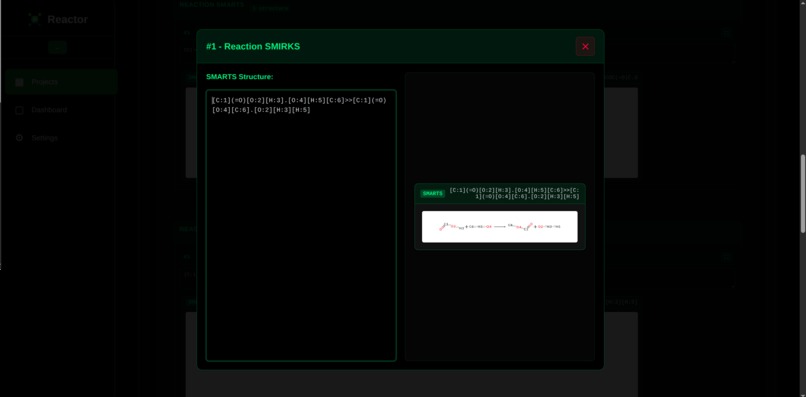
Expanded Editor Page
-
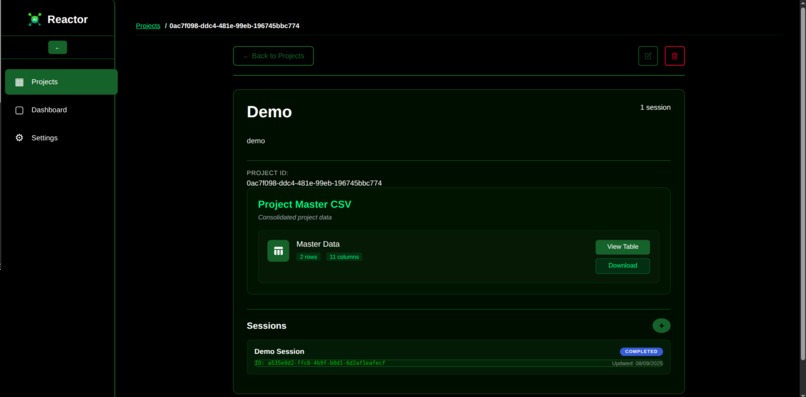
Project Page
-
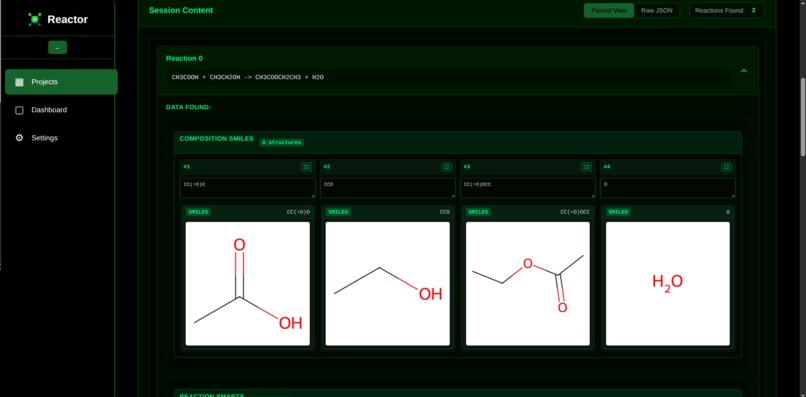
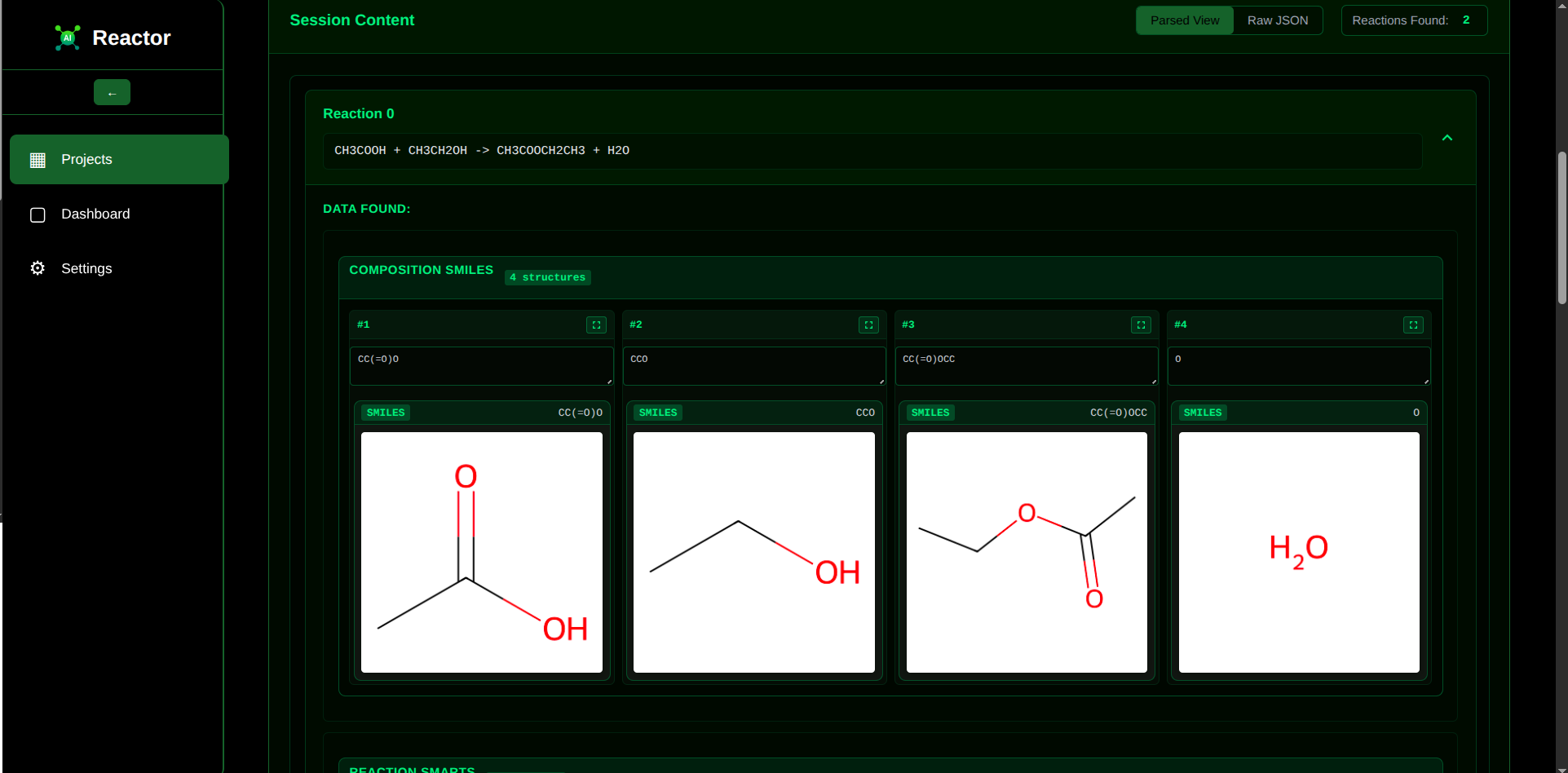
Session Finding Page
-
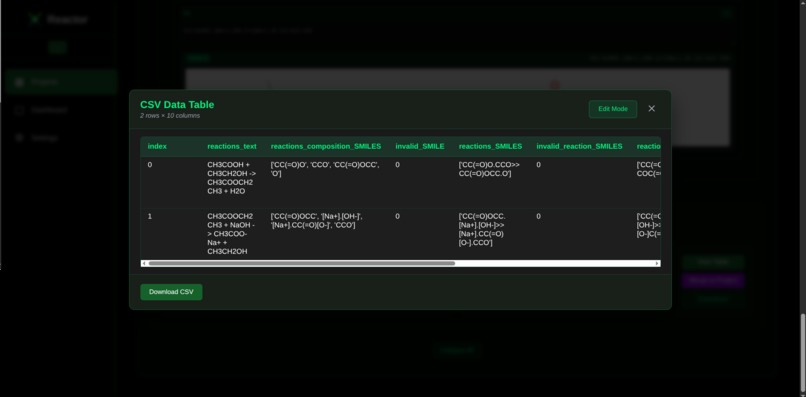
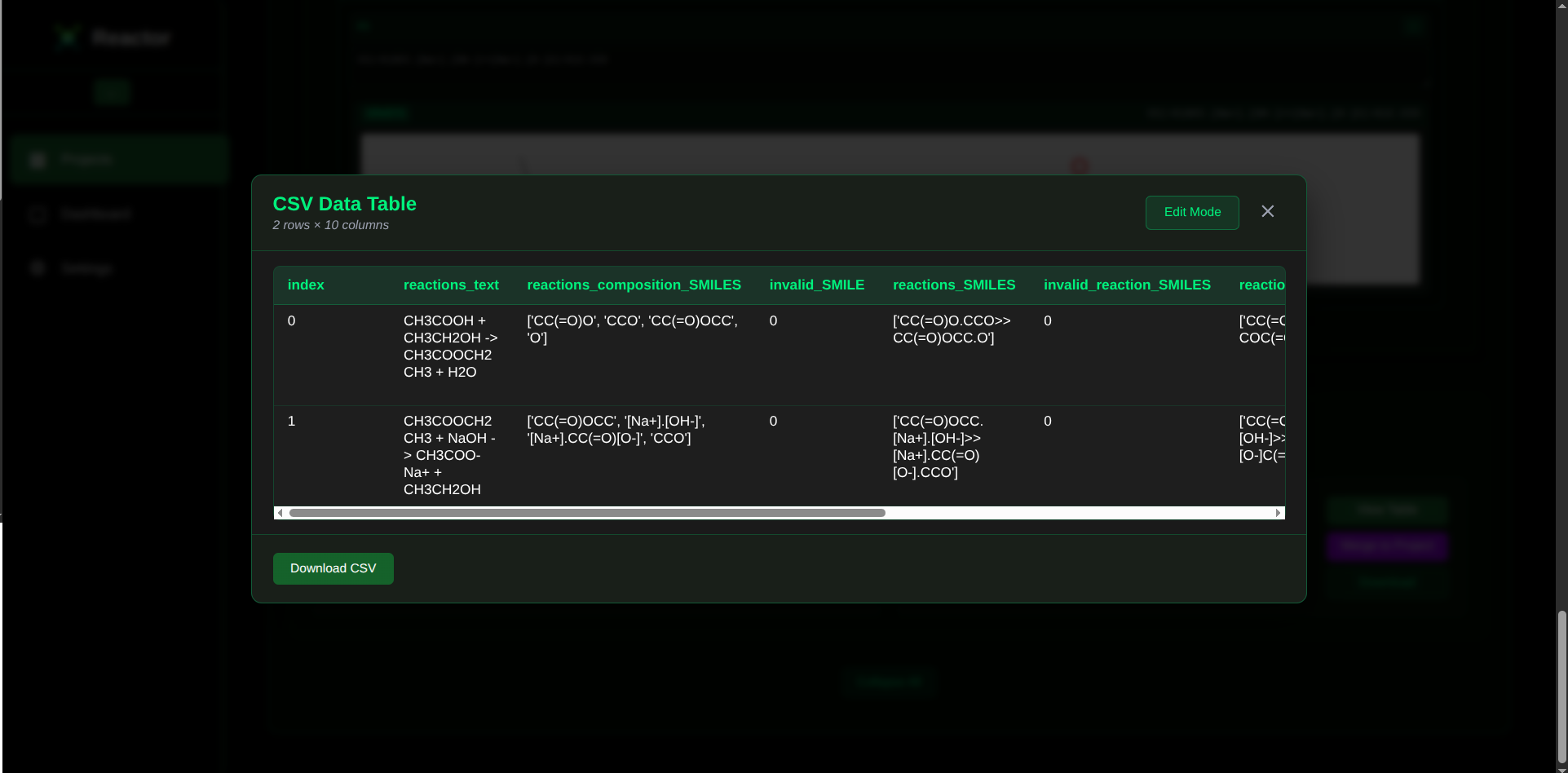
Tabular Findings View Page
-
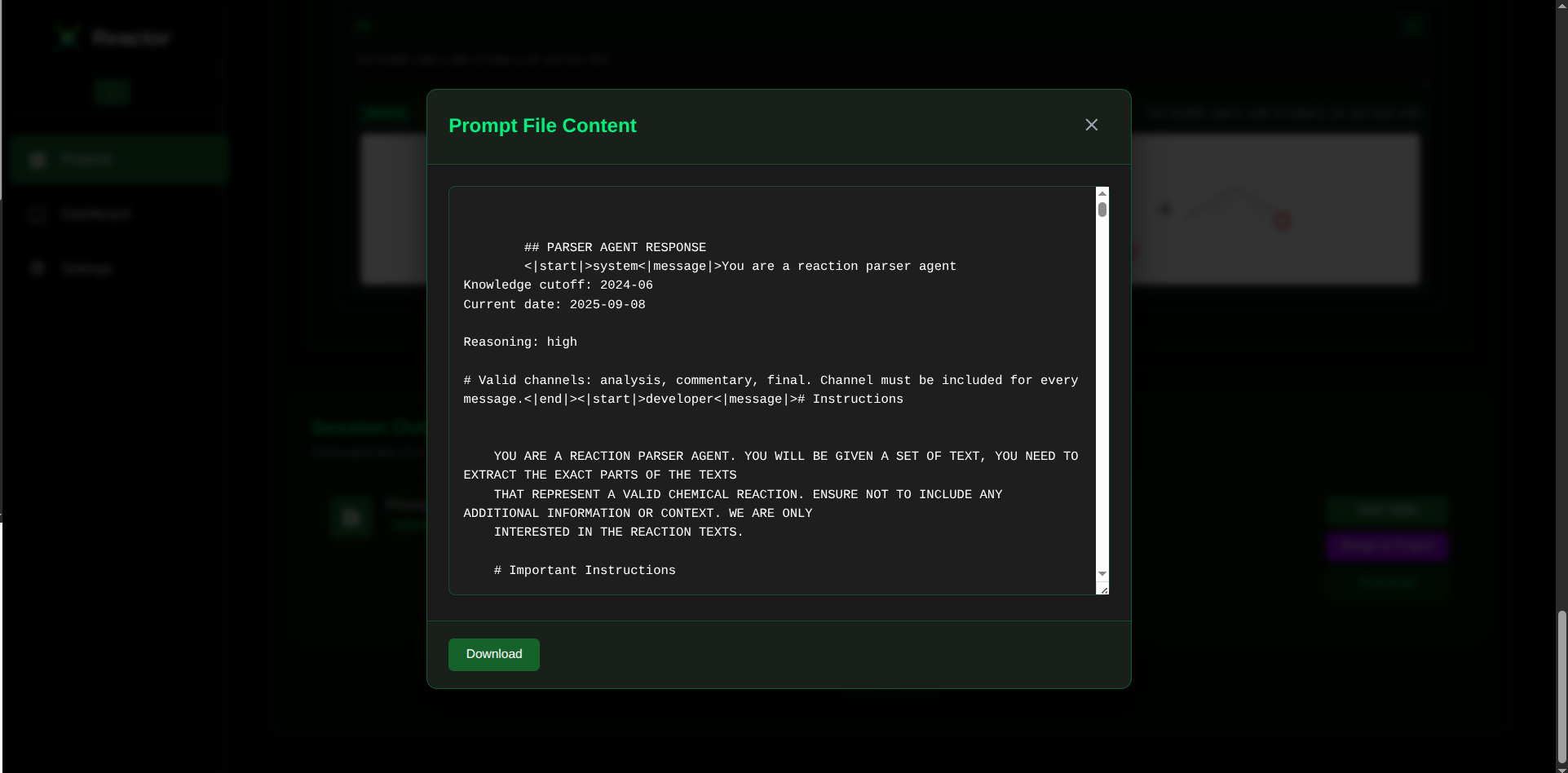
Conversation List Viewer
Inspiration
For computers to accelerate material discovery, we must first translate chemical information from natural language into a format they can understand. Although formats like SMILES and SMARTS are commonly used to represent molecules and reactions, the vast majority of new chemical research is still published in plain text. This disconnect means we need a "mediator agent"—a tool that can accurately translate the language of chemistry into machine-readable formats. This fundamental conversion is the crucial first step for many downstream applications, from drug development to molecular dynamics simulations.
The Problems with Existing Solutions
While some advanced AI models are good at these complex conversions, they come with significant drawbacks.
Privacy Concerns: Using proprietary models requires sending sensitive research data to a third party, which violates the privacy policies of many organizations.
Licensing Issues: Models with non-commercial licenses can create legal conflicts if the research discoveries they help produce are later commercialized.
High Resource Costs: Running large-scale models repeatedly for specific tasks is slow and consumes too many resources, especially when processing huge volumes of texts.
Our Open-Source Approach
To solve these issues, we opted to use open-source AI models that can be run locally on a device or within a university's computing clusters. This approach ensures data privacy and avoids licensing conflicts. However, these open-source models often aren't accurate enough for the task. To dramatically improve their performance, we've implemented an agentic framework, which provides the necessary reasoning and logic to increase the accuracy of the conversions manyfold.
What it does
The reactor is a comprehensive system designed to automate the process of converting research text into usable chemical data. It serves two main functions:
Automation and Data Generation
Acting as a powerful automation engine, the reactor automatically extracts and validates chemical annotations from a specific set of research texts. It then compiles these findings into a CSV table, making the data immediately available for use in existing cheminformatics pipelines.
Project Management and Control
The reactor also provides a user-friendly interface for managing your projects and datasets. This interface gives you complete control, allowing you to monitor the automated findings and directly edit chemical representations to ensure data accuracy before they are used in your downstream tasks.
How we built it
We discovered that small-scale open-source LLMs (like 20B and 120B models) often fail when integrated into existing large-scale agentic frameworks. These frameworks have complex communication protocols that require specific output formatting, which smaller models struggle to produce accurately.
To solve this, we created our own minimal agentic architecture. We found that smaller LLMs could handle complex tasks if we first broke them down into a series of smaller, more manageable sub-tasks. This approach significantly reduces the risk of the model "hallucinating" or generating incorrect information.
The core of our system is a custom adapter that utilizes the OpenAI harmony-response format. This adapter ensures all communication between agents is properly formatted and, most importantly, archives every step for monitoring purposes. By chaining these small, specialized agents together in a sequence with a feedback and retry loop, we were able to dramatically improve accuracy, achieving excellent results even with the smaller 20B model.
For the user interface and API, we used React for the frontend and FastAPI for the backend.
Challenges we ran into
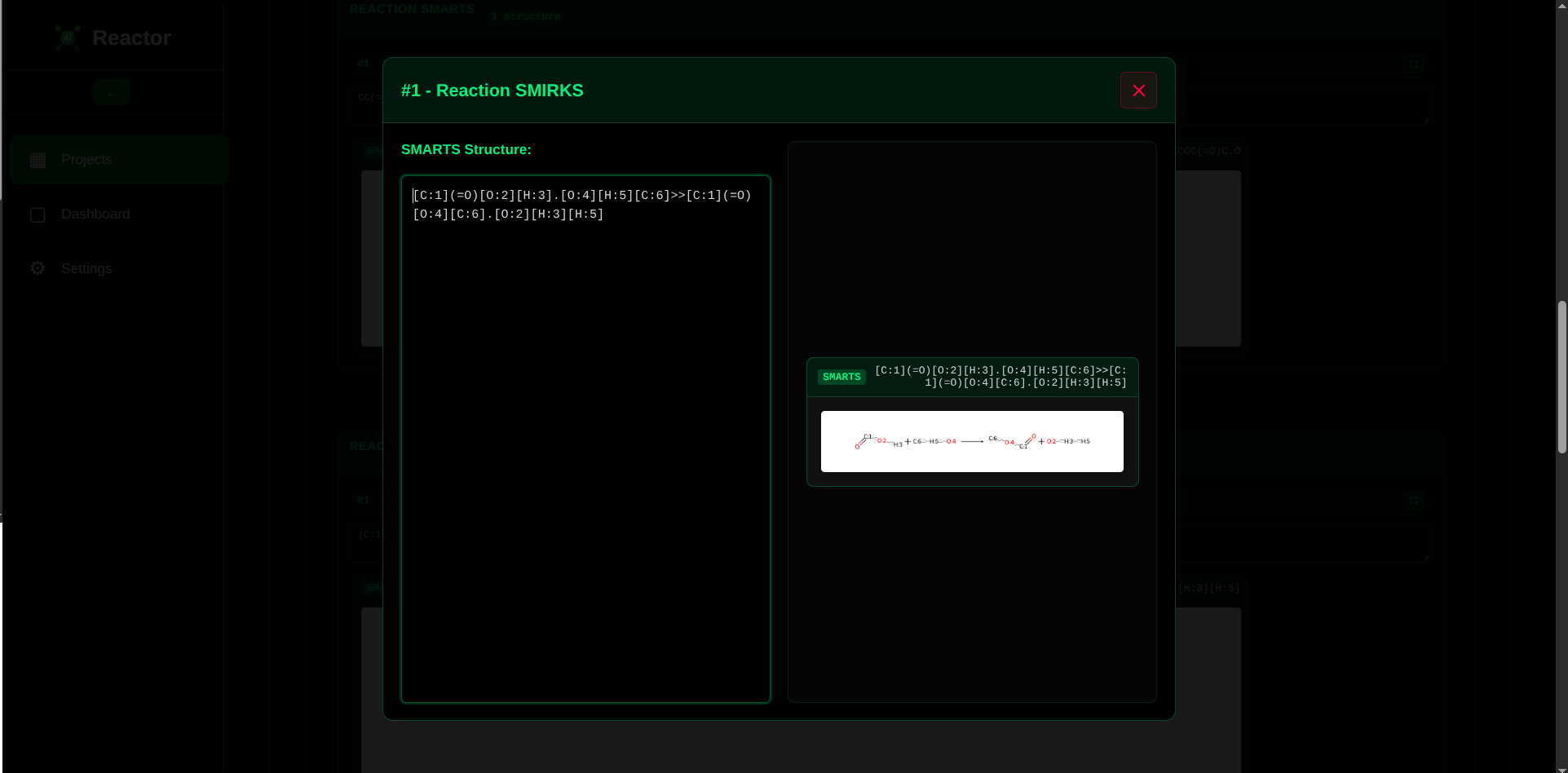
The main hurdle was accurately formatting SMIRKS annotations for chemical reactions. Because SMIRKS only tracks changes in specific, indexed atoms, it can sometimes be confused with SMARTS annotations. This overlap was a problem because our validator, a superset of SMIRKS, would often "hallucinate" and incorrectly accept an invalid annotation as correct, causing data errors.
The second challenge was creating a diverse benchmarking dataset. Very few existing resources provide textual data for different types of chemical reactions. Even after extensive manual research, we could only find 67 reaction types to test. To make matters worse, most of the relevant reactions are only available as images. Even vision language models (VLMs), designed to handle such tasks, were unable to reliably extract the reaction data from these images and form valid text paragraphs.
Accomplishments that we're proud of
Using our new architecture, we significantly improved the accuracy of open-source LLMs compared to a single-run approach, making them reliable enough for practical use. By integrating RDKit, an interface, and a RestAPI backend, we can now effectively validate, monitor, and handle the conversion of large volumes of scientific data.
What we learned
By using a system of smaller, specialized agents to handle sub-tasks and generate smaller, targeted outputs, we achieved a significantly lower failure rate—even when using smaller language models. While the failure rate can remain similar for highly complex single-step conversions, our agentic system performs far better when processing long-running tasks or generating detailed responses. The strategy of assigning agents to specific, smaller tasks makes the entire process more reliable and accurate.
What's next for Reactor
We're expanding our post-hackathon project into a formal study on accurate cheminformatics data handling using multi-agent architectures. By extending our models with various large language models (LLMs), we've successfully tested the system's ability to manage large-scale data conversion. We plan to publish our findings in a scientific journal. For future production use, we may integrate the system with an existing MCP (Multi-Computer Platform) server to be used as part of a large-scale scientific automation workflow.
Built With
- fastapi
- javascript
- openai
- openai-harmony
- python
- rdkit
- react
- sqlite


Log in or sign up for Devpost to join the conversation.