-
-

SplashScreen
-
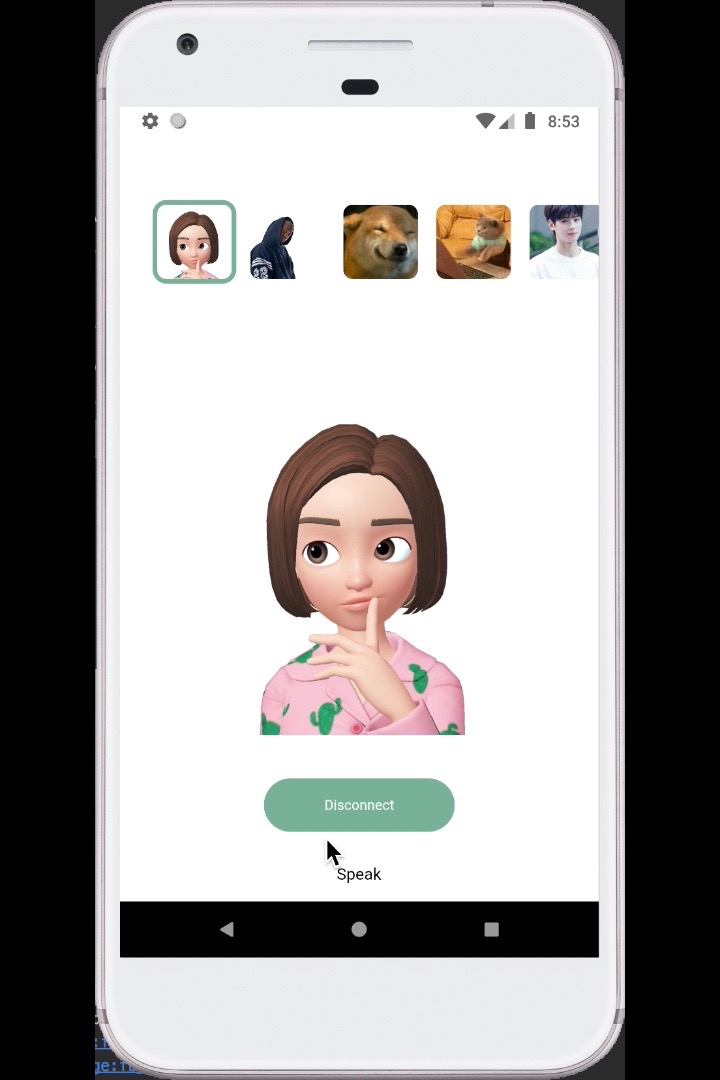
Select your persona.
-
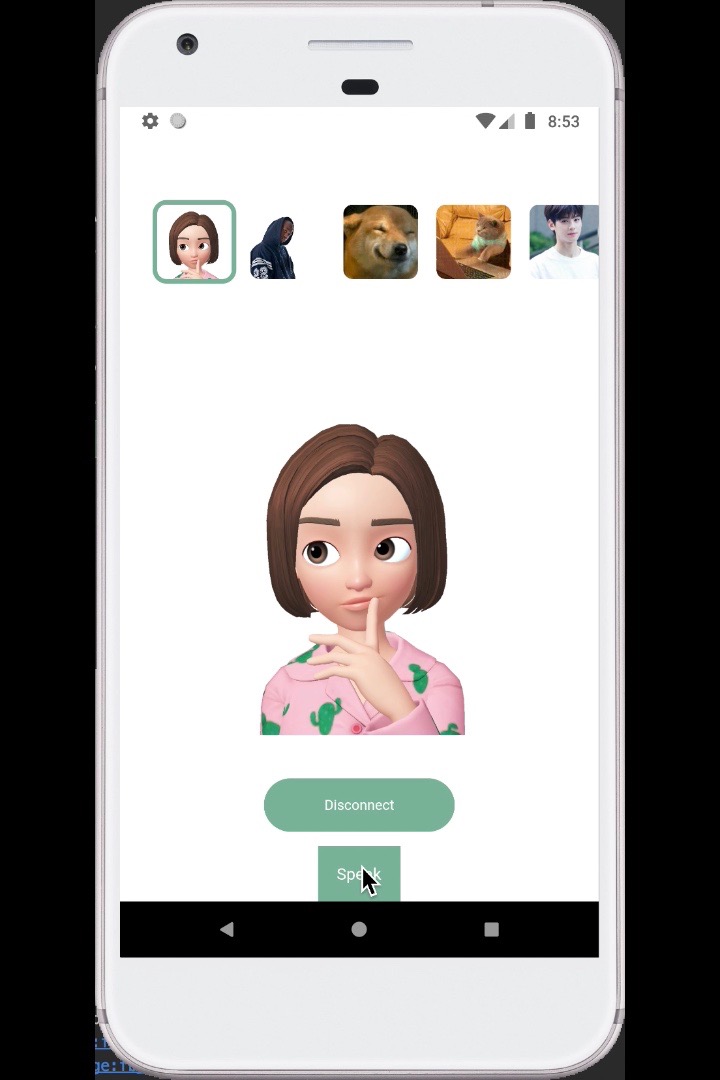
Start talking while pressing the button.
-
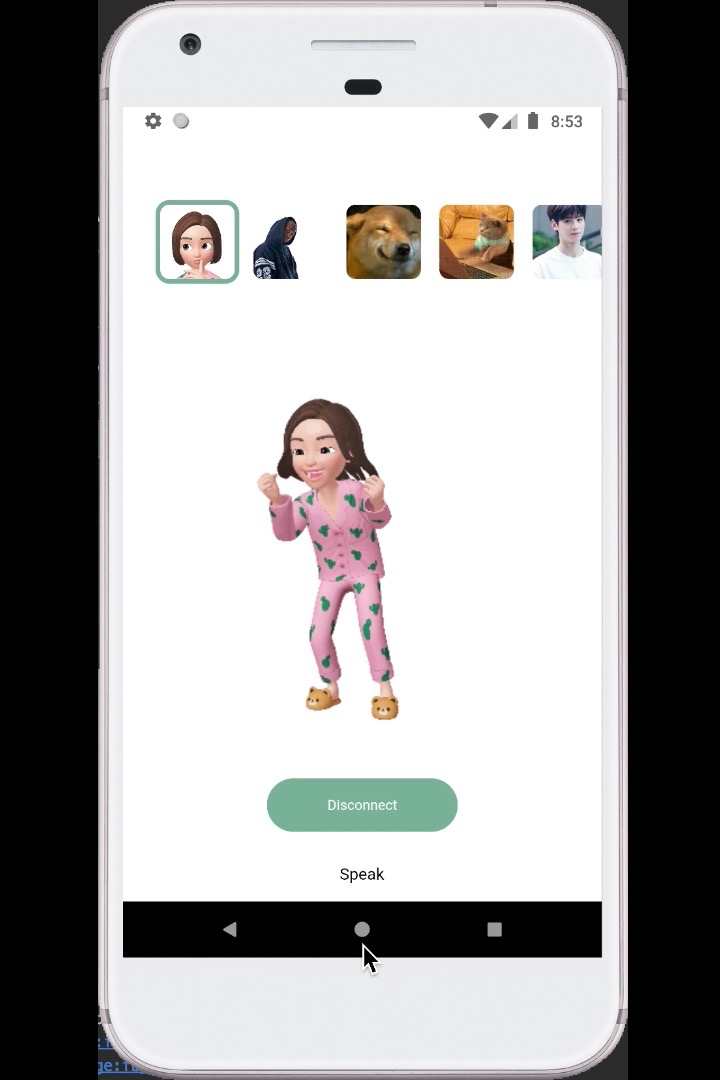
Persona recognizes and reacts to your emotion!
-
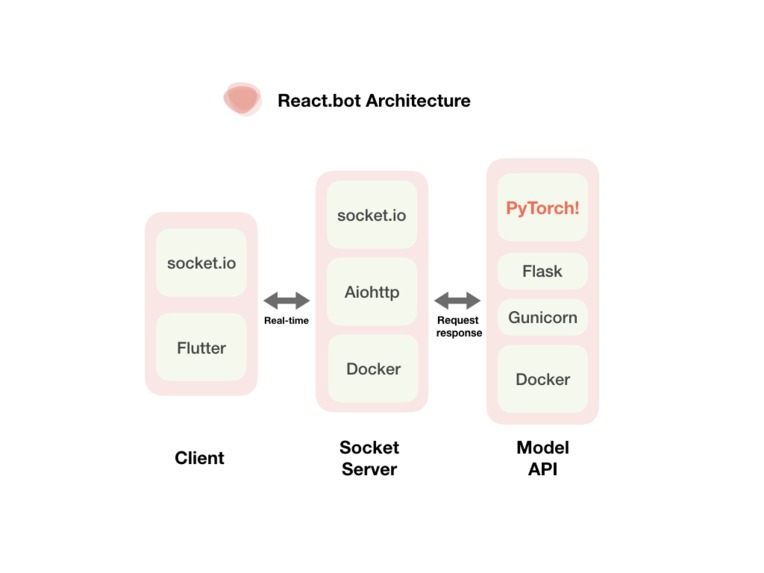
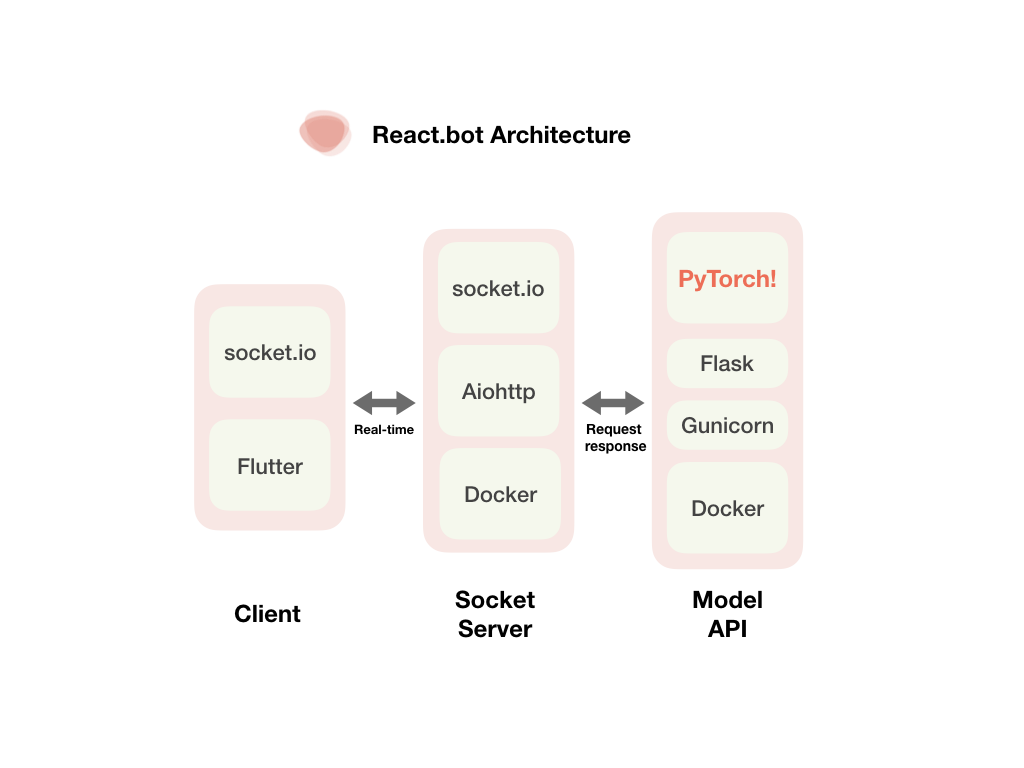
System Architecture
Inspiration
What should we do at the times of loneliness? That was the beginning of our idea.
Emotional loneliness, defined as not having a significant emotional connection with others, is one of the most problematic social phenomenon nowadays. We are living in a good environment where we can easily make friends. But the problem is, most of the relations we have aren't deep enough to share our innermost feelings! We then yearn for someone to whom we want to pour out all our feelings, and who would just listen.
So that's what we made! Our new friend, react.bot, faithfully listens to you, understands your feelings, and reacts proactively by giving the best reactions you would want. Simple yet fun reactions will be just enough to make you feel resonated and cheerful. You can even select different personas of your liking!
We hope react.bot can give a more delightful encouragement to lonely modern people.
What it does
- Detects emotions inherent in user's speech by analyzing audio bytestream in realtime.
- Resonates with users by reacting proactively to detected emotions in images and sounds, such as laughing out loud, sharing tears, or expressing rage on behalf.
- Provides various personas that show unique reactions to account for users' diverse preferences.
How we built it
Front-End
- Designed with prototyping tool, Sketch.
- Built with Flutter to support Android/iOS multi-platform.
- Used socket.io library to send audio bytestream in realtime to server.
Back-End
- Socket Server
- Used socket.io and Aiohttp to receive audio bytestream from client.
- Model Server
- Used Flask and PyTorch to deliver sentimental analysis result inferred by models when socket server requests for it.
Model
- Extracted various audio features from data such as mfcc, chroma, spectral_centroid, spectral_rolloff, spectral_flux and spectral_bandwidth.
- The data we used is from IEMOCAP (https://sail.usc.edu/iemocap/).
- BiLSTM model, implemented with PyTorch, classifies audio features into four sentiments (neutral, angry, excited, and sad).
- Improved model accuracy by utilizing various audio augmentation methods (speed, loudness, noise, VTLP perturbation).
Challenges we ran into
First of all, the biggest challenge for all of us was that we only had night time to work for this project since we all have full-time jobs. Below are more specific challenges we faced in different phases:
Ideation
- No preceding application we could refer to.
- Lack of information on how we should design reactions to satisfy users' needs for resonance.
- Lack of criteria for deciding which personas we should select.
- Prepared resources for reactions on our own.
- Rummaged through many sites to find appropriate images and sounds for reactions.
- Due to lack of adequate sounds, self-recording was also necessary.
Modeling
- Various models to research, taking into account feasibility of implementation in very limited time.
- Difficulty of improving model's performance, due to the small pool of emotion labelled speech data.
- Lack of experience in processing audio features.
Development
- Not enough experience with technologies we needed to use to decide what frameworks to use and which one is better than the other.
- e.g. whether web-app or native-app would be more appropriate for implementing realtime voice data transmission.
- Needed to find a way to shorten reaction time as much as possible for realtime experience.
- e.g. directly embedding a pre-trained model into client vs building a backend server for inference
- Innate limitations in libraries and tools.
- e.g. VAD library that we chose couldn't properly filter out voice activities from realtime audio stream.
Accomplishments that we're proud of
For the most part, we are very proud in that we successfully made a fully functioning application overcoming many challenges we faced. In detail:
Ideation
- Created an original, unprecedented service through deliberate ideations.
Modeling
- Chose BiLSTM as the best model possible.
- Overcame the lack of data problem by augmenting dataset, thus improving the model accuracy.
Development
- Devised workarounds to deal with limitations of existing libraries to ensure the best possible application usage.
- Since WebRTC didn't provide raw bytestream access, we wired together Flutter's microphone library and socket.io to send audio bytestream and receive results in realtime.
- Since VAD library didn't work as expected, we instead used a button to mark start and end of the speech.
What we learned
- Strengths of Pytorch
- Very pythonic! Intuitive and easy-to-write code.
- Ease of debugging speeds up development process.
- Various kind of methodologies to deal with text or speech data through paper review.
- Cutting-edge technologies and libraries (e.g. fastText and fairSeq).
- Understanding how a realtime service works between client and server.
- Last but not least, developing a completely new service from scratch was painful, but also very meaningful and enjoyable.
What's next for react.bot
Technological improvements
- Improve emotion prediction performance.
- Currently, our model predicts only four emotions, but we want to further diversify emotions it can recognize.
- We are currently using only voice data, but we are planning to use speaker's facial expressions or movements to create a more accurate emotion prediction model.
- Keeping the context.
- Make the model consider the characteristics of the speaker and the context, obtained from the previous conversation, so that it can provide a more consistent response.
Service-level improvements
- Not only relieving one's loneliness, it can also be applied on various industrial fields, such as AI audience of live broadcasting service.
- Archive the moment that the speaker communicated with react.bot and help them reminisce about the moment.
- Diversify personas.








Log in or sign up for Devpost to join the conversation.