-
-

LOGO
-
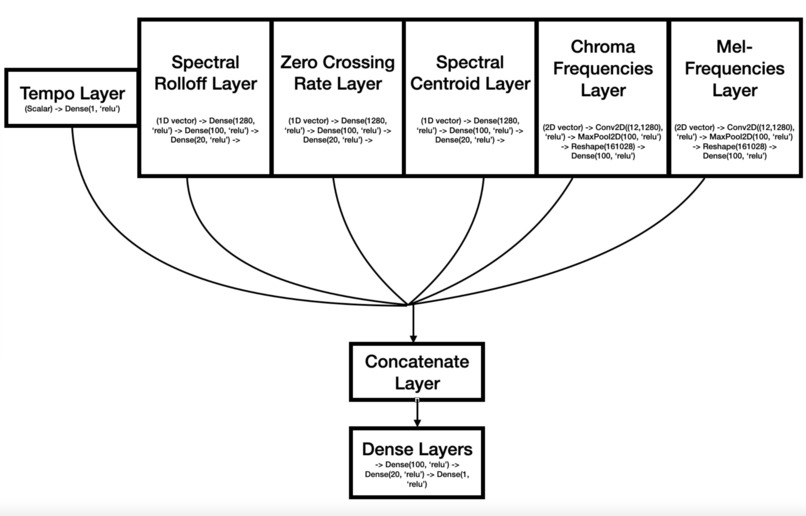
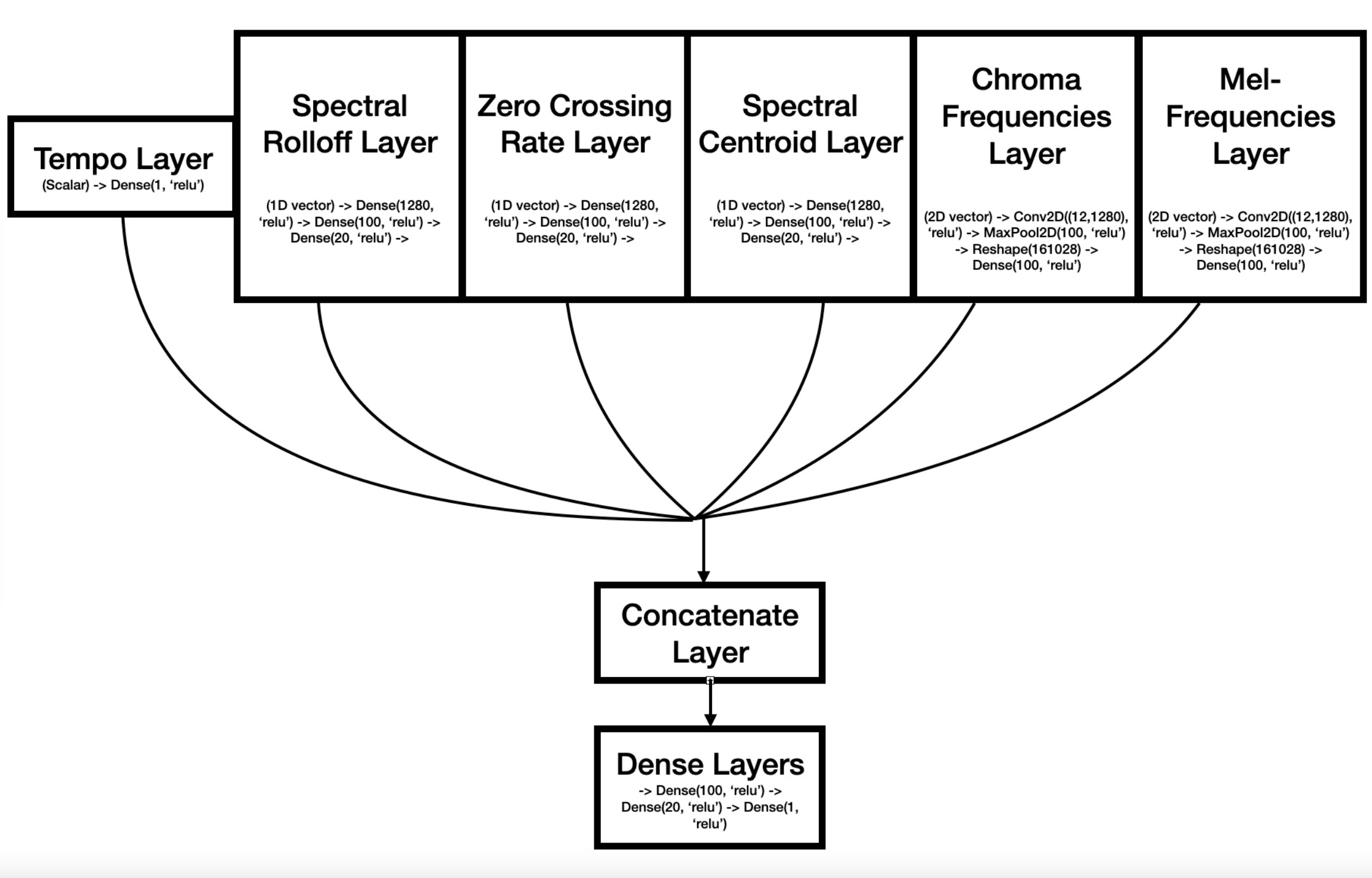
ML Architecture
-
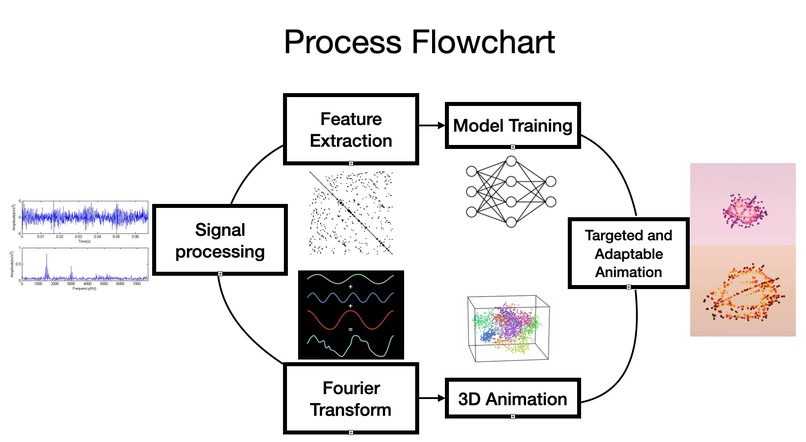
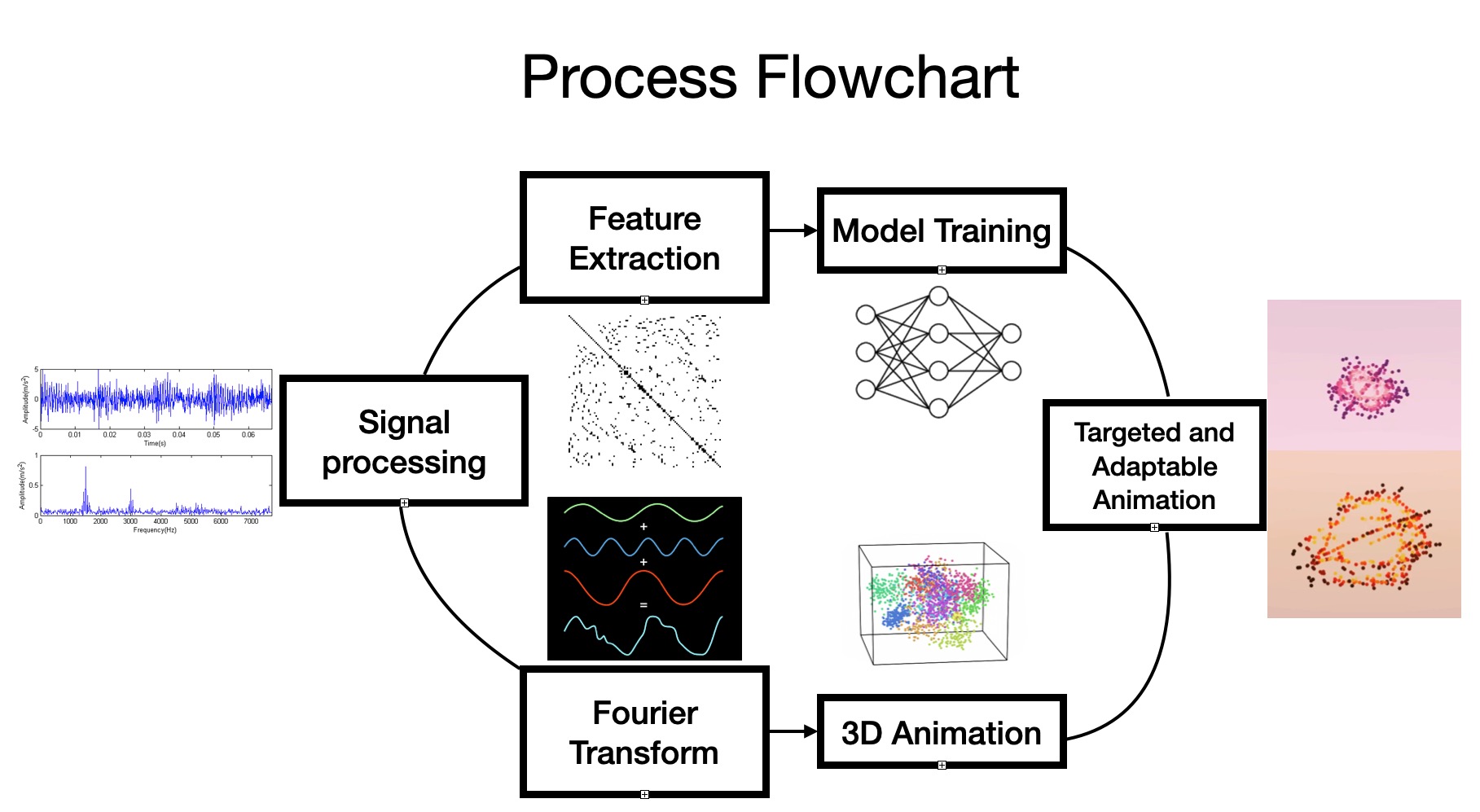
Process Flow Chart
-

3D-Visual Snapshot


Inspiration
“When you are Deaf, you see the world in a different way." Music, or any sound, is missing from a hearing impaired individual's life. Direct consequences from the loss of hearing include fewer educational opportunities, difficulties in social communication, a drop in self-esteem, etc. As a team, we feel empathetic to this often ignored minority group. Therefore, appreciating the importance of human-centred design, and in response to the UN SDG Goal of reduced inequality, we want to reduce the inconvenience that people are experiencing due to loss of hearing and restore their enjoyment of music. Our ultimate goal is to establish an inclusive social environment for everyone.
What it does
It takes in music and transforms it into a 3D visualization!
How we built it
Using machine learning, vector calculus, signal processing in python and applying engineering empathy into design and decision making. We were able to create a product that can take in the music and create a 3D visualization of the music by classifying the genre of the music and analyzing its rhythm and decomposed signals. Therefore creating a brand new way of music representation.
Machine Learning: Using Librosa, a python library for sound feature extraction, we were able to extract six defining features of different genres of music. We concatenated neural network layers for each branch together and topped it off with a dense layer. We were able to reach a mae of 1.3 when training on 80% of the dataset. With this model, we were able to create a transition of background themes based on the classified genre of the music.
Fourier Transformation To create animation, music is separated into windows of frames of signals. Then, we applied Fourier Transform to the signals and converted them into polar coordinates to create a meaningful and unique representation of the selected segments.
Turning into 3D The 2D points created using FFT is expanded into 3d shape by rotating around a different axis. Due to white noise or background noise, there are many points clustered in the middle of the plots, especially after being expanded to 3D. To ensure visual appeal and also runtime/complexity requirements, optimizations are performed such as selecting more of the outer points and decreasing the size and opacity of the points closer to the middle.
Challenges we ran into
We divided our project into developing the neural network for music genre classification and turning raw signal waveforms into lively animations.
Challenges when developing neural networks
Given that we have no prior experience with signal processing, it’s challenging to determine which features are best for our model to learn from. We were able to figure out the necessary features after reading related papers/documentation and watching YouTube tutorials.
Processing the data and feeding them into a neural network for training is extremely time-consuming. Specifically, features of each audio take approximately 2 seconds to be extracted. We had to make smaller experiments, and then make informed decisions on how we go about efficiently training the neural networks.
Challenges for animating raw signal waveforms
The most demanding task of animation is understanding the math behind it. In this case, we had to first figure out how to apply Fourier transformations and visualize the results in 2D and 3D spaces.
Another challenging milestone was adapting the animation to different genres of music with the integration of the genre classification model. This tests our team’s ability to communicate different parts of a design to each other to arrive at a final, complete solution.
Accomplishments that we're proud of
- Able to train a machine learning model based on sound data (which we haven’t worked with before).
- Learned how to use Fourier transformation to create a meaningful representation of signals in 3D.
- Able to apply what we learned from school (vector calculus and matrix transformation) to create 3D animations.
- Have a working finished product!
What we learned
- Learned how to use Fourier transformation to create meaningful representation in 3D.
- Learned how to perform signal processing and feature extraction on these signals.
- Furthered our knowledge in training machine learning models and data processing.
- Learned how to make animations using Matplotlib.
What's next for RE-HEAR
This 36 hours of hacking is not only an invaluable learning experience for us, it is also an opportunity for us to explore the future of our project, Re-hear. We can further work on improving the genre classifications model, expanding the features to include 3D / AR / VR technologies, and involving stakeholder validation.
For genre classification models, we plan to utilize more comprehensive datasets and increase the complexity of our model to achieve more accurate results.
Introducing 3D / AR / VR technologies brings a more immersive "restoration" experience for the intended users. With multiple technologies at play, users can experience a more realistic simulation of restoration.
We also look forward to working with stakeholders to learn about how the general community feels about this project and to determine the features our team needs to iterate through again.





 Jason")

Log in or sign up for Devpost to join the conversation.