-
-

-
Query-aware compression
-

Published Research Paper
-
Total-token crossover: Cheap-Echidna
-
Context growth per turn
-
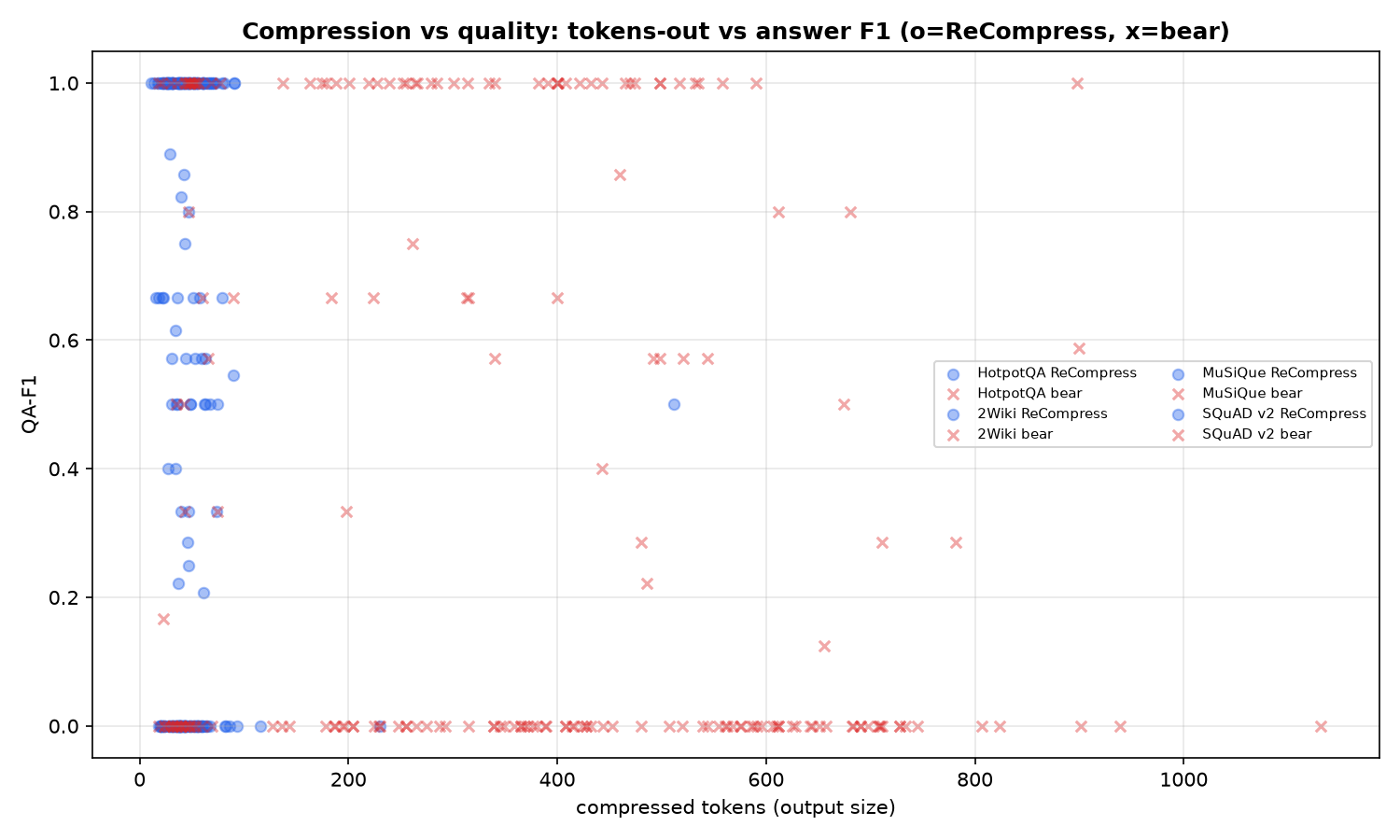
Compressions vs Quality
-
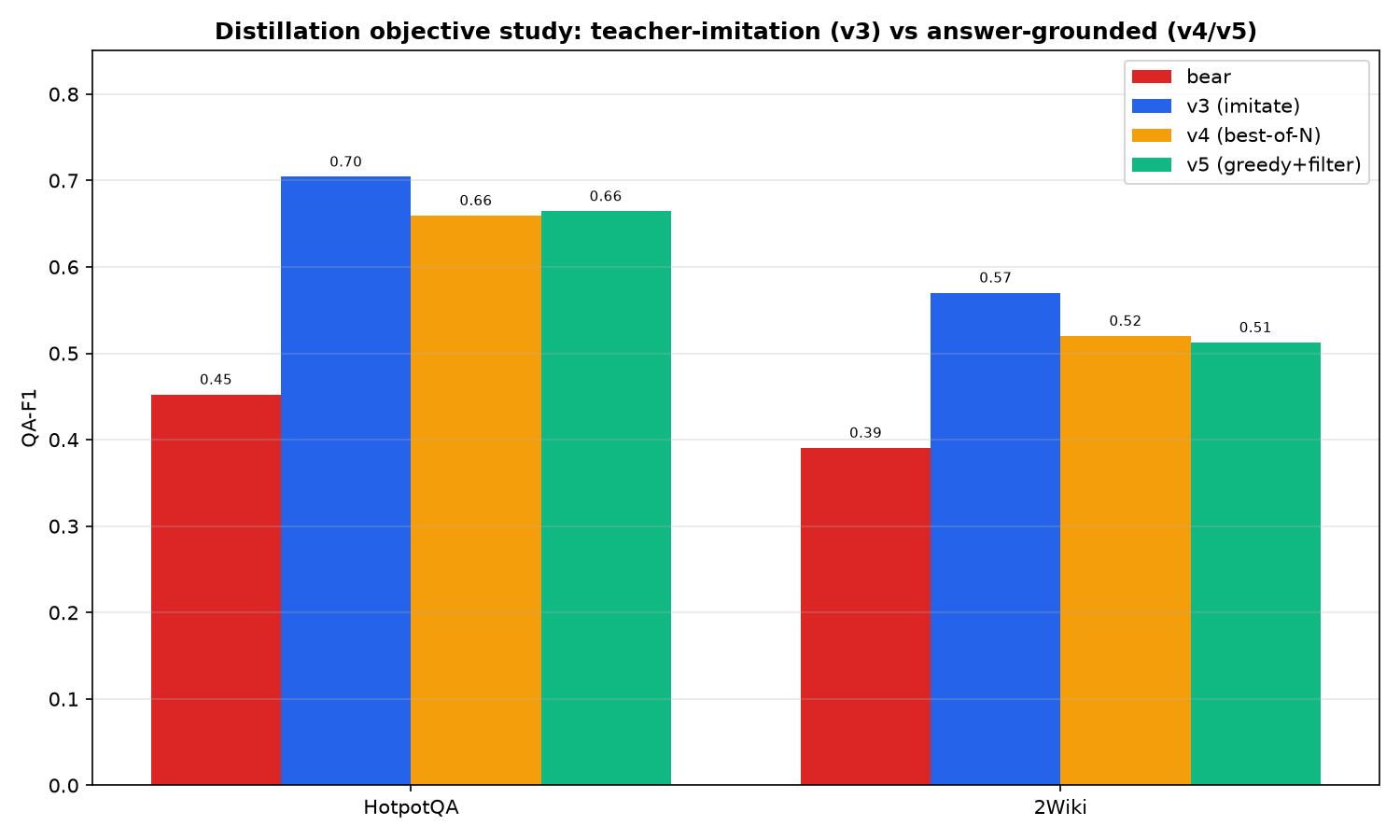
Distillation objective study: Which method worked best


ReCompress — Devpost submission
Paste each section into the matching Devpost field. This covers the WHOLE project — both acts and all five distillation experiments. Tagline + "Built With" + links at the bottom.
Project name
ReCompress: rewrite-don't-delete context compression, distilled to 1.5B and extended to flat-context multi-turn
Tagline (Devpost "tagline" field)
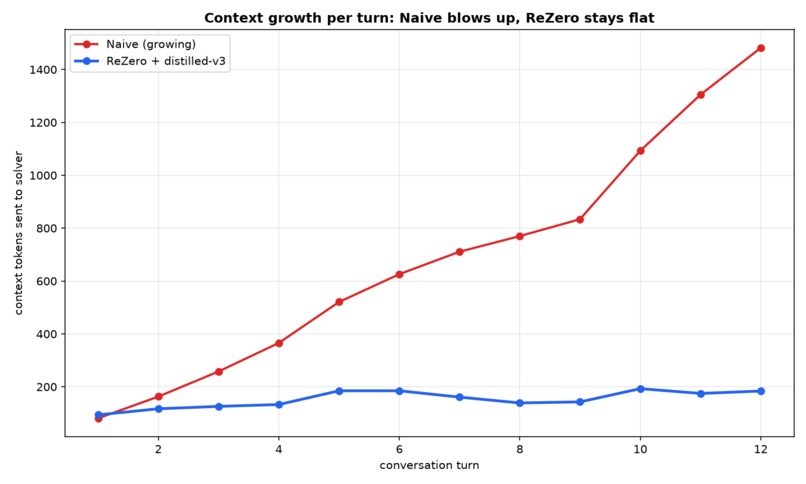
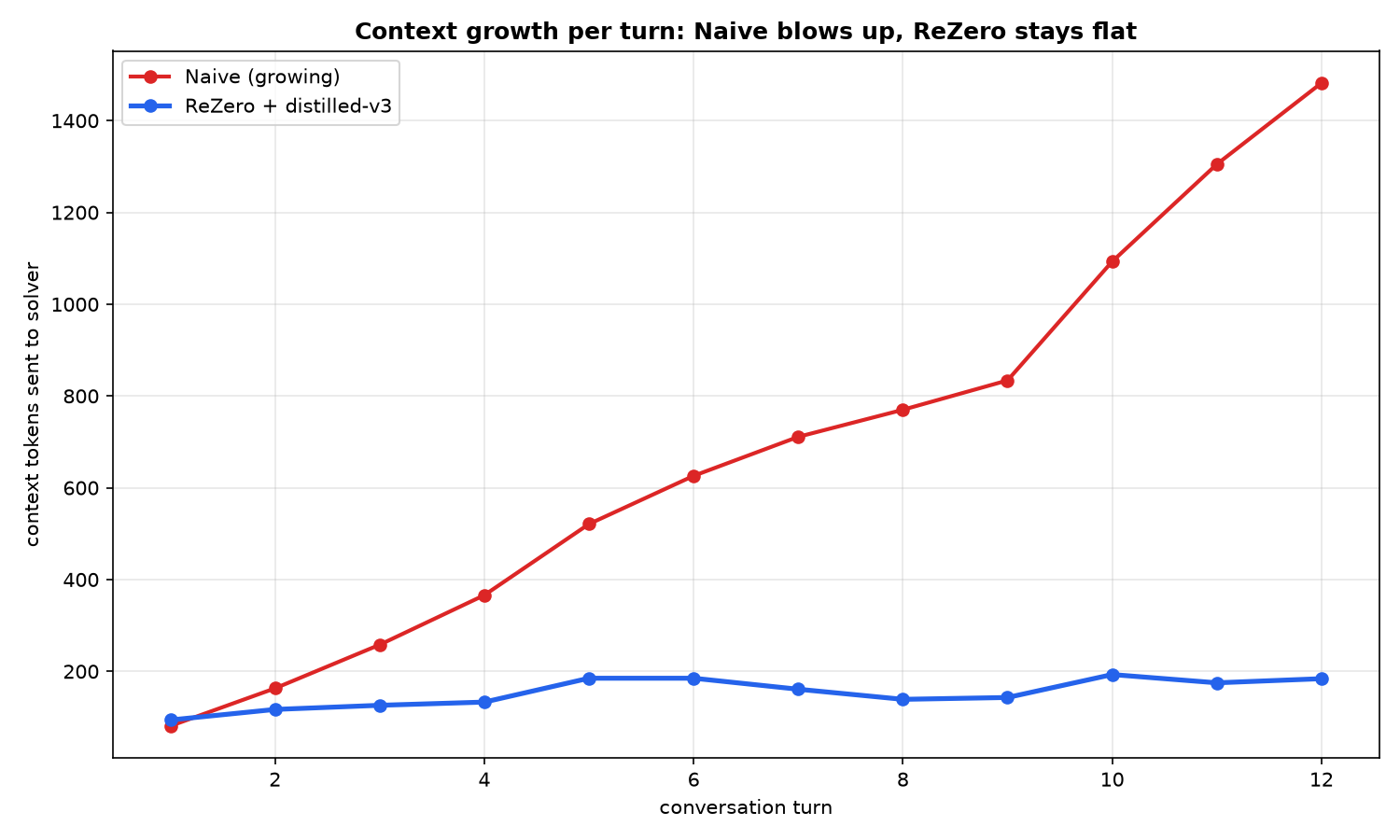
A query-aware rewriting layer that extends compression into the regime deletion can't reach — distilled into a 1.5B model, then carried into multi-turn conversations to keep a 12-turn chat flat (184 tok) while a naive agent balloons to 1,482.
Inspiration
The Token Company's bear-2 compresses prompts by deleting low-value tokens — fast and lossless-by-design, but blind in two ways deletion structurally can't fix: it can't read your question, and it can't rewrite. We wanted to measure what those two abilities are worth — and prove you don't need a giant model to get them.
Compression isn't only a single-prompt problem, though. In a long conversation, context grows every turn (O(n²) cost). So we built the project in two acts: Act 1 — a query-aware compressor distilled into a small offline model; Act 2 — a multi-turn memory ("Re:Zero") that uses that compressor to keep context flat forever.
What it does
ReCompress is one system in two acts.
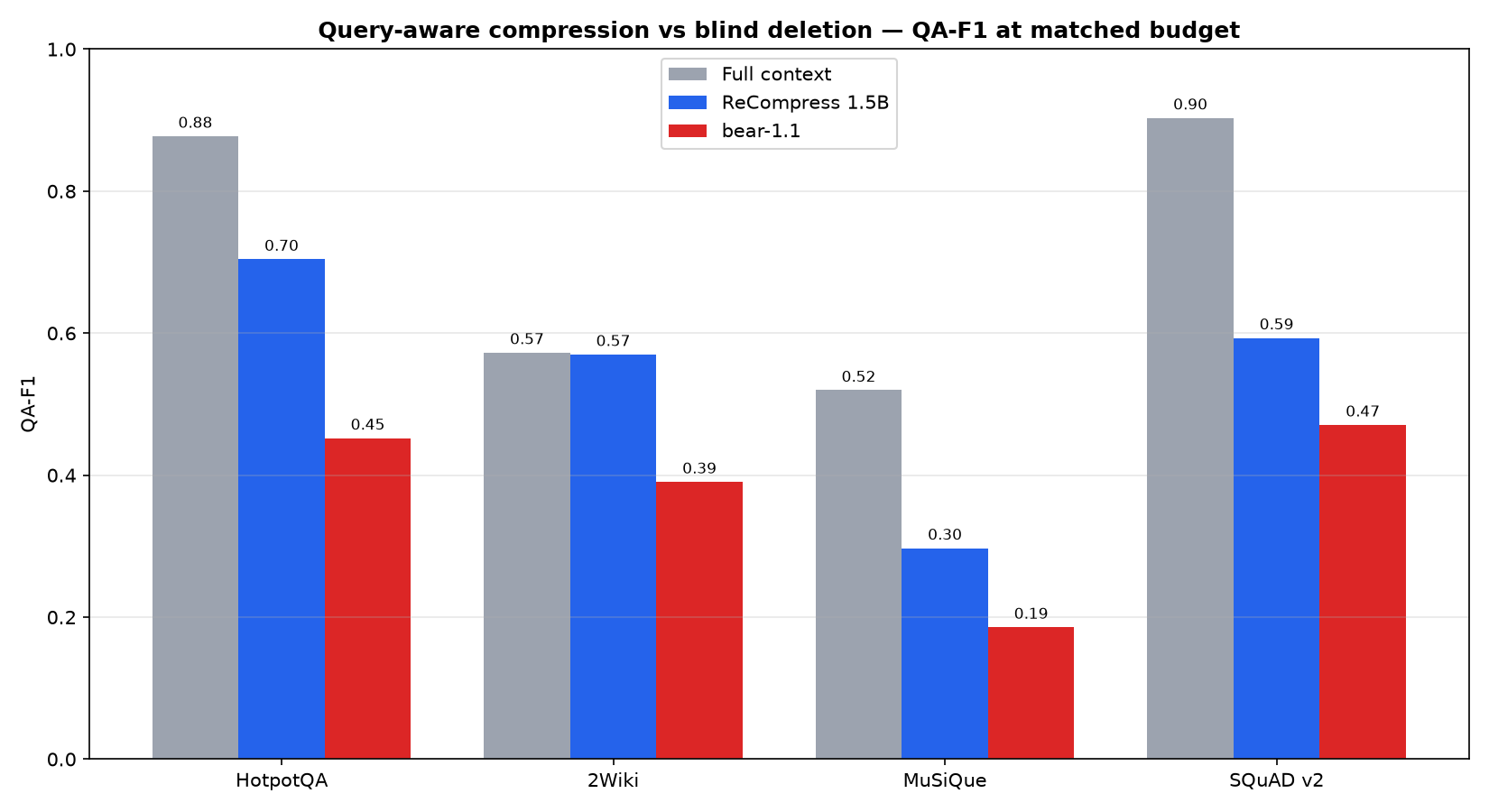
Act 1 — single-shot compression. Given a long context + a question, it drops the passages irrelevant to that question and rewrites the rest densely; a downstream LLM then answers. We distilled this behavior (from a DeepSeek teacher) into Qwen2.5-1.5B + LoRA so it runs offline and cheap.
Act 2 — Re:Zero multi-turn memory. A fixed ~300-token budget per turn — protected facts + a compressed checkpoint of older turns + the recent raw delta — so context stays flat instead of growing. The checkpoints are compressed by the Act 1 model, so the whole agent runs on our distilled compressor.
Headline results.
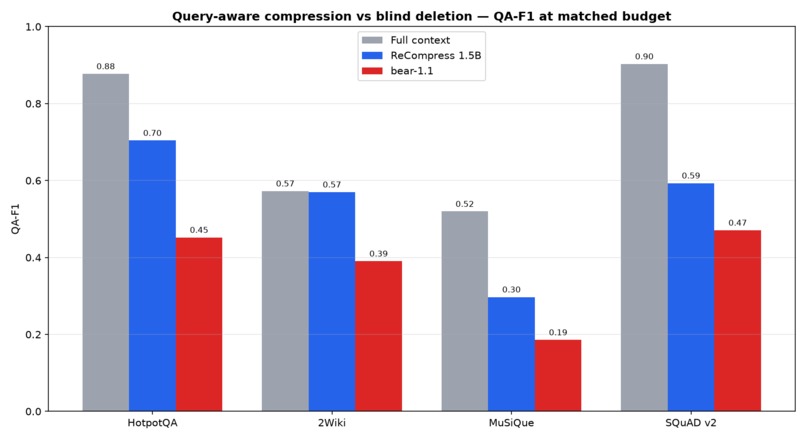
Act 1 — distilled 1.5B vs bear-2, same compression instruction (ours realizes ~8.5× fewer tokens: ~48 vs ~409 on HotpotQA), QA-F1, paired bootstrap 95% CI:
| Benchmark | ReCompress 1.5B | bear-2 | Δ vs bear | significant? |
|---|---|---|---|---|
| HotpotQA | 0.704 | 0.452 | +0.252 (+56%) | ✅ yes |
| 2Wiki (never trained on) | 0.570 | 0.390 | +0.180 (+46%) | ✅ yes |
| MuSiQue | 0.297 | 0.186 | +0.111 | directional |
| SQuAD v2 | 0.593 | 0.471 | +0.123 | directional |
Act 2 — multi-turn HotpotQA, 6 turns, n=20:
| Strategy | final F1 | context tokens |
|---|---|---|
| Naive (growing history) | 0.485 | 846 |
| Re:Zero + DeepSeek API | 0.455 | 198 |
| Re:Zero + our distilled model | 0.501 | 174 |
| Re:Zero + bear | 0.472 | 257 |
Re:Zero powered by our distilled model wins on both axes — best answer quality at the fewest tokens. Over 12 turns a naive agent grows to 1,482 context tokens while Re:Zero stays flat at ~184 (8.1× less, and diverging).
How we built it — and the five experiments behind the winning model
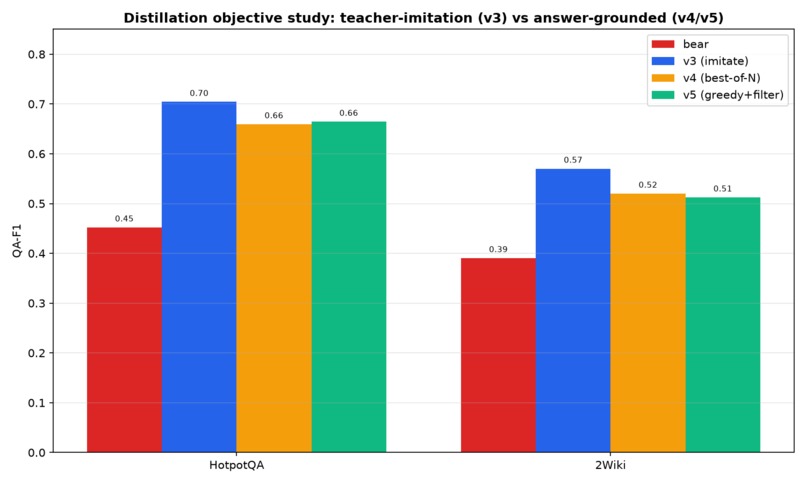
The Act 1 distilled model is the result of five distillation experiments, each a deliberate test. We name them so the trajectory is legible (not "v1…v5"):
| # | Experiment | What we changed | Outcome |
|---|---|---|---|
| 1 | Spark | first distill — 261 examples, LoRA r=16, 3 epochs | ❌ Wash vs bear (Δ=+0.06, CI includes 0): too little data |
| 2 | Bonfire | scaled hard — 2,500 examples, r=64, 6 epochs | ❌ Overfit: eval loss bottomed at epoch 2 then climbed every epoch |
| 3 | Hearth ⭐ | the balance — 5,000 examples, r=32, dropout 0.1, weight-decay, early-stop | ✅ The winner — +0.252 F1 (+56%) on HotpotQA, generalizes to 2Wiki |
| 4 | Oracle | answer-grounded: best-of-4 candidates, kept only ones the solver answers right | ❌ Lost to Hearth (−0.05 F1) — selecting by a frozen judge overfits the judge |
| 5 | Oracle-Lite | answer-grounded but greedy (no best-of-N) — to test if #4's loss was selection noise | ❌ Also lost — proving it wasn't a best-of-N artifact; answer-grounding just doesn't beat imitation |
Plus a sixth idea we designed, tested, and dropped — "Bear-Booster": train the small model to make bear's output better (optimize bear(model(text))). Our own data showed it's dominated — the standalone model beats model→bear on every benchmark, and a pre-processor is strictly costlier than bear alone. A clean negative result that sharpened the thesis: rewriting must replace deletion, not augment it.
Pipeline: DeepSeek teacher → 5,000 query-aware compression pairs → LoRA fine-tune Qwen2.5-1.5B (4-bit, Unsloth) on a Modal H100 → eval vs bear (TTC SDK) under the same compression instruction with bootstrap CIs across 4 benchmarks → wire the winner (Hearth) into Re:Zero as a pluggable backend → custom multi-turn benchmark. ~$10–15 total compute.
Challenges we ran into
- Distillation failed twice before Hearth worked (Spark wash → Bonfire overfit). Fixing it took the full anti-overfitting playbook: more data, lower rank, dropout, weight-decay, early-stopping on best-eval.
- A "smarter" idea (answer-grounded, Oracle/Oracle-Lite) lost — twice. Optimizing against downstream answer success overfit the frozen solver and hurt out-of-distribution generalization. Documented as a negative result.
- The Modal + Unsloth + trl stack is version-brittle — ~7 distinct runtime failures before the first clean train (dependency conflicts, container data paths, the
formatting_funccontract, eval-time CUDA OOM, a packing incompatibility). All written up as reproducibility notes. - Integration: wiring the Act 1 Modal model into Act 2's synchronous checkpoint loop without breaking either codebase.
Accomplishments we're proud of
- A 1.5B model that recovers the query-aware regime bear cedes — beating bear with statistical significance while emitting ~8.5× fewer tokens, and transferring to a near-in-distribution benchmark it never trained on (2Wiki, +46%; directional-but-unproven on the dissimilar OOD sets). It complements deletion rather than replacing it: deletion stays best for fast/verbatim/reusable; rewriting adds the query-specific case.
- We stress-tested our own headline before a judge could. The teacher and solver are both DeepSeek (a circularity a sharp reviewer attacks first), so we re-scored with an independent solver (Claude Sonnet): the gap is invariant — Δ vs bear = +0.288 (independent) vs +0.285 (in-family), CI excludes zero both ways. The result is not a same-family artifact.
- A unified system: the same distilled compressor works as a single-shot compressor and as a multi-turn memory engine (the strongest backend of the three we tested, vs DeepSeek and bear).
- Research-grade rigor + intellectual honesty in 24h: bootstrap CIs on every claim, a cross-solver audit, a mask-the-answer audit (measured against ourselves), 5 named experiments with a clear winner, three documented negative results, a conceptual finding (the "deletion ceiling"), a 13-figure visualization suite, and a custom multi-turn benchmark.
What we learned
- Query-aware rewriting beats blind *deletion* at far fewer tokens — most where there are distractors (multi-hop QA). On purely abstractive QA (MS MARCO) it ties bear — an honest boundary we report.
- The win survives an independent judge (Claude Sonnet, +0.288) — it's not teacher↔solver affinity.
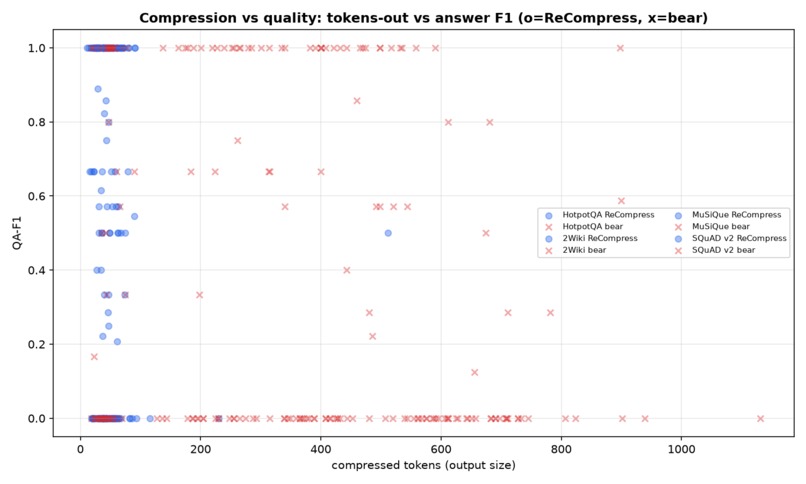
- Much of the margin is span-selection, not reasoning — and we proved it on ourselves. Masking the gold answer from the compression drops our F1 by 65% (vs bear's 31%). So our edge is largely "query-aware compression keeps the answer-bearing span at a 3.5% budget where bear's deletion at 30% truncates it" — a real, useful property, stated precisely rather than oversold.
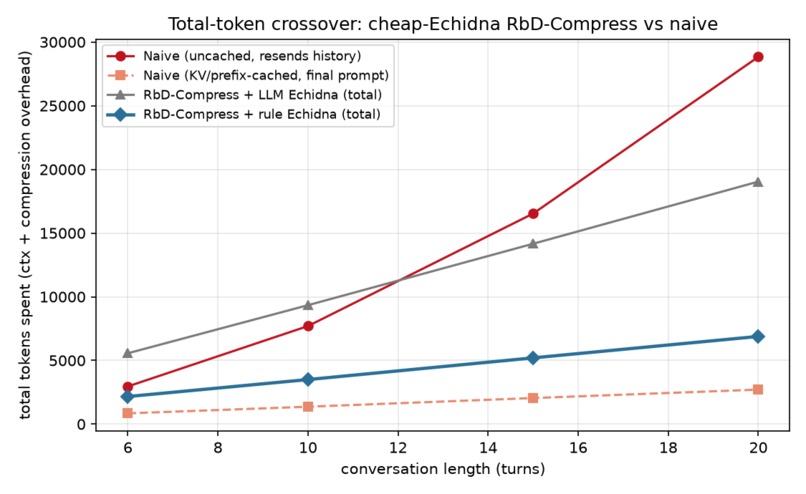
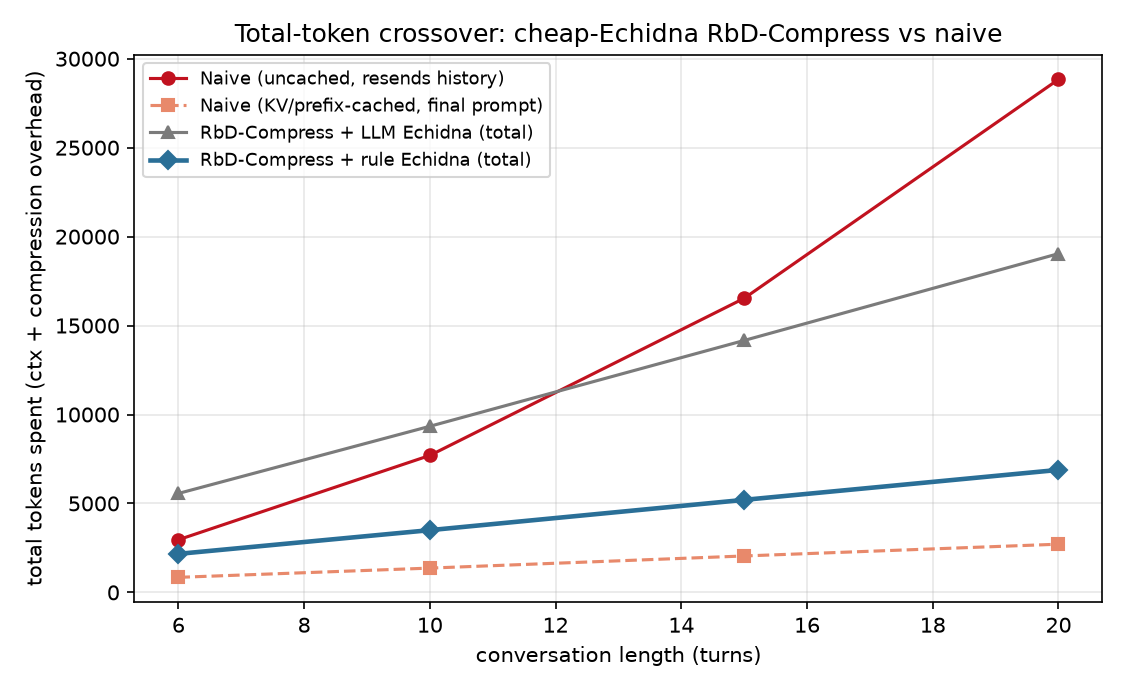
- We measured our multi-turn overhead honestly — and found our own expensive component was useless. The "8.1× flatter context" is the solver-context axis; counting the per-turn compression LLM calls, the system actually costs more in total tokens at short horizons. Digging in, the LLM "Echidna" checkpoint-trigger turned out to decide
checkpoint98.3% of the time — no real decision. We replaced it with a free rule (2.6× cheaper, same F1) and swept conversation length: with the cheap trigger the system beats an uncached growing-history agent on total tokens from ~6 turns, widening monotonically to ~4× by 20 turns (6,886 vs 28,838). The LLM-trigger version was actually so expensive it got overtaken by the naive agent around turn 11 — it was counterproductive, not just wasteful. Against a cached agent we still don't win on raw tokens, and we say so. - You can't fix deletion by stacking it after rewriting (
model→bear<modeleverywhere) — the "deletion ceiling." - Downstream-grounded distillation isn't free — selecting by a frozen judge overfits it (Oracle/Oracle-Lite both lost to imitation-based Hearth).
- The same compressor composes — single-shot quality transfers to keeping conversations flat.
What's next
- Direct comparison to LLMLingua-2 (closest prior work — they delete/classify tokens; we rewrite and distilled it into a generative 1.5B).
- Scale teacher data + ratios to push MuSiQue/SQuAD into significance.
- A live demo of Re:Zero holding a long conversation flat in real time.
"Built With"
python · qwen2.5-1.5b · lora · unsloth · modal · h100 · deepseek-api · the-token-company-sdk · huggingface-datasets · hotpotqa · 2wikimultihop · musique · squad · ms-marco · matplotlib
Links
- 📄 Paper (Zenodo, DOI): https://doi.org/10.5281/zenodo.20786357
- 📓 Reproduce in Google Colab: https://colab.research.google.com/github/Kart-ing/ReCompress/blob/main/notebooks/ReCompress_reproduce.ipynb
- 🎛 Interactive demo: https://demo-eight-olive-97.vercel.app
- 🖥 Slides: https://slides-teal-tau.vercel.app
- 💻 Code (both acts): https://github.com/Kart-ing/ReCompress
- Trained adapters + full experiment archive (all 5 experiments, incl. failures) + figures: in the repo (Git LFS)
One-line differentiator (keep ready for the pitch + Q&A)
"LLMLingua deletes tokens; we rewrite them — distilled into a 1.5B (after five experiments — Hearth won) that extends The Token Company's bear into the query-aware regime it cedes, measured head-to-head with CIs across 4 benchmarks, and powers a multi-turn memory that keeps a 12-turn chat flat at 184 tokens while a naive agent hits 1,482."
Built With
- 2wikimultihop
- deepseek-api
- h100
- hotpotqa
- huggingface-datasets
- lora
- modal
- ms-marco
- musique
- python
- qwen2.5-1.5b
- squad
- the-token-company-sdk
- unsloth




Log in or sign up for Devpost to join the conversation.