-

01. RBC Challenge - Customer Social Media Feedback Detection and Analysis.
-
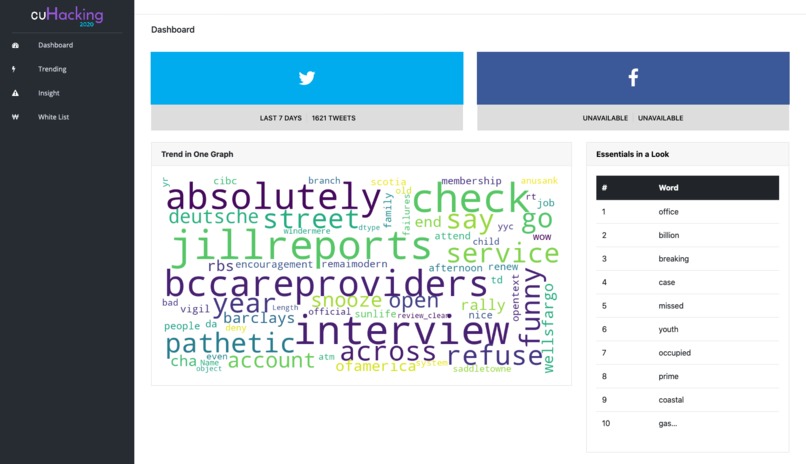
02. Dashboard - Just need a glance!
-
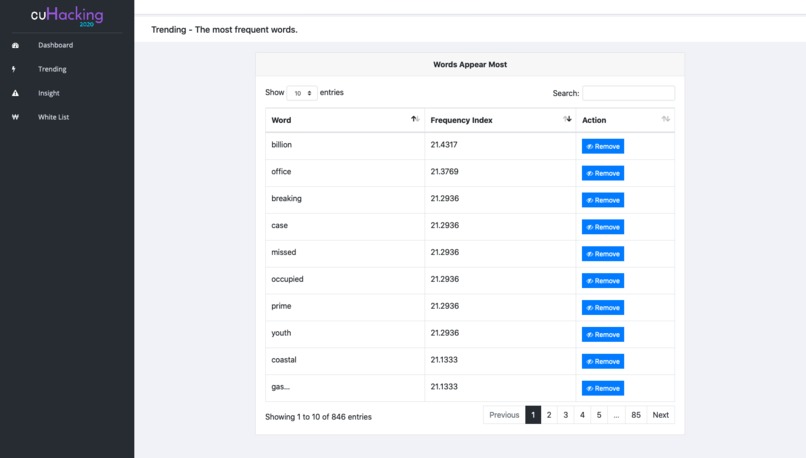
03. Trending - Show me highly mentioned words!
-
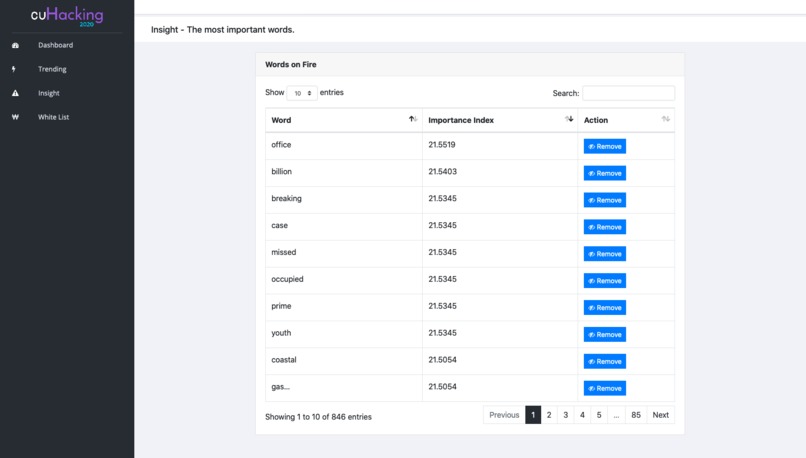
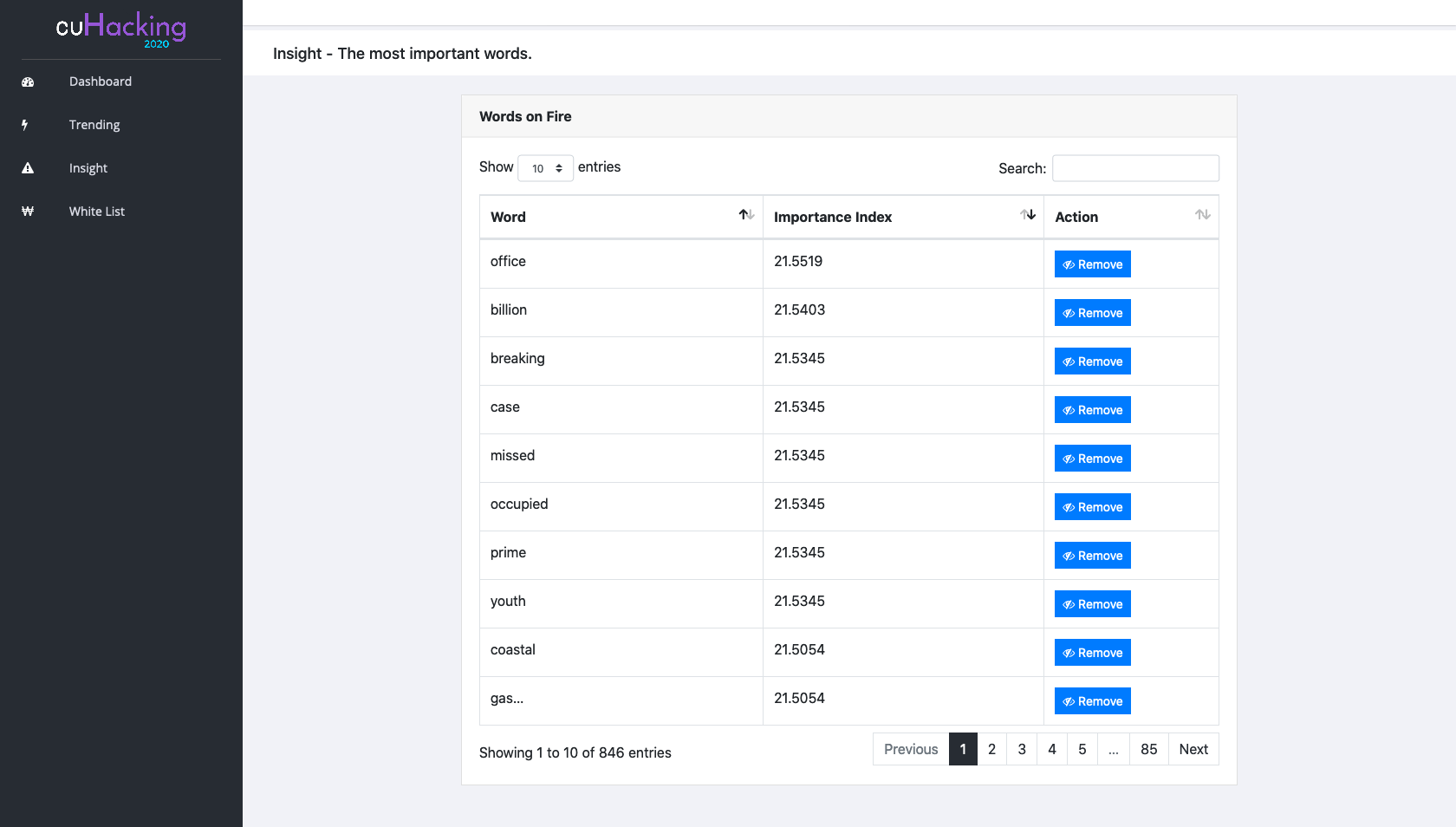
04. Insight - A table contains essential words!
-
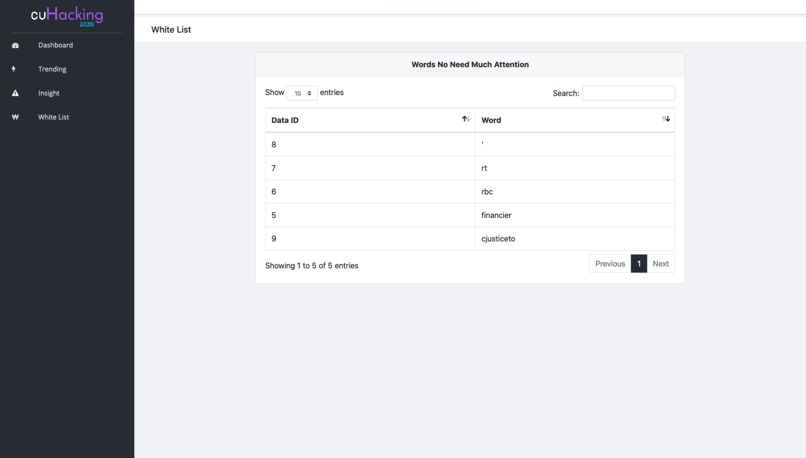
05. White List - Customizable list!




Inspiration
Similar to analyze developers' behaviour on GitHub, analyzing RBC's Twitter customer feedback also can bring not only surprising finding but can improve service quality, which is the very original reason that why we want to conduct this little project.
What It Does
In this project, we use Python as our primary language to collect, pre-process and analyze Twitter posts with hashtag RBC. Also, we use sentiment analysis to classify positive and negative tweets, then we further perform TF-IDF technique to uncover the important but disperse keywords among tweets. Finally, we use MySQL to save data and use PHP to present it with user-friendly UI and format.
How We Built It
First, we use Python and Twitter API to collect tweets with #RBC, then pre-process it. Next, we perform Sentiment Analysis to find negative feedback. TF-IDF was introduced subsequently, which can analyze all textual corpus and present frequency of words as well as pointing out the most important keywords. Finally, MySQL plays the role of saving data and PHP can connect to the database then present data again.
Challenges We Ran Into
During the project, learning how to use twitter API and collecting raw data were the most time-spending challenges for us. What’s more, figure out a useful and reliable model to classifier processed data was also not easy.
Accomplishments That We're Proud of
In this project, we first perform Sentiment Analysis model to predict positive and negative feedback, which gives us a lot of inspiration about future academic research.
What We Learned
First of all, with this experience, we not only obtained and sharpen our developing skills but more importantly, team working also enables us to exchange domain knowledge and respect different specialties and.
What's Next for RBC Challenges: Twitter Customer Feedback Analysis
Though we tried hard to make this project complete, there is still some room to improve. First, in this project we only cover Twitter platform, but there are many more social media platforms that can be included (e.g. Facebook, Reddit, etc.). Secondly, our model so far can not very precisely point out specific service problems. We infer that we need to perform and combine other state-of-the-art techniques in order to improve accuracy.
Reference
☞ Term-weighting approaches in automatic text retrieval, Information Processing & Management
☞ A benchmark study on sentiment analysis for software engineering research
☞ GitHub Repo
Built With
- css
- customer-relationship-management
- html5
- javascript
- machine-learning
- mysql
- php
- python
- sentiment-analysis
- social-engineering
- social-media
- tf-idf
- word-cloud


Log in or sign up for Devpost to join the conversation.