-
-

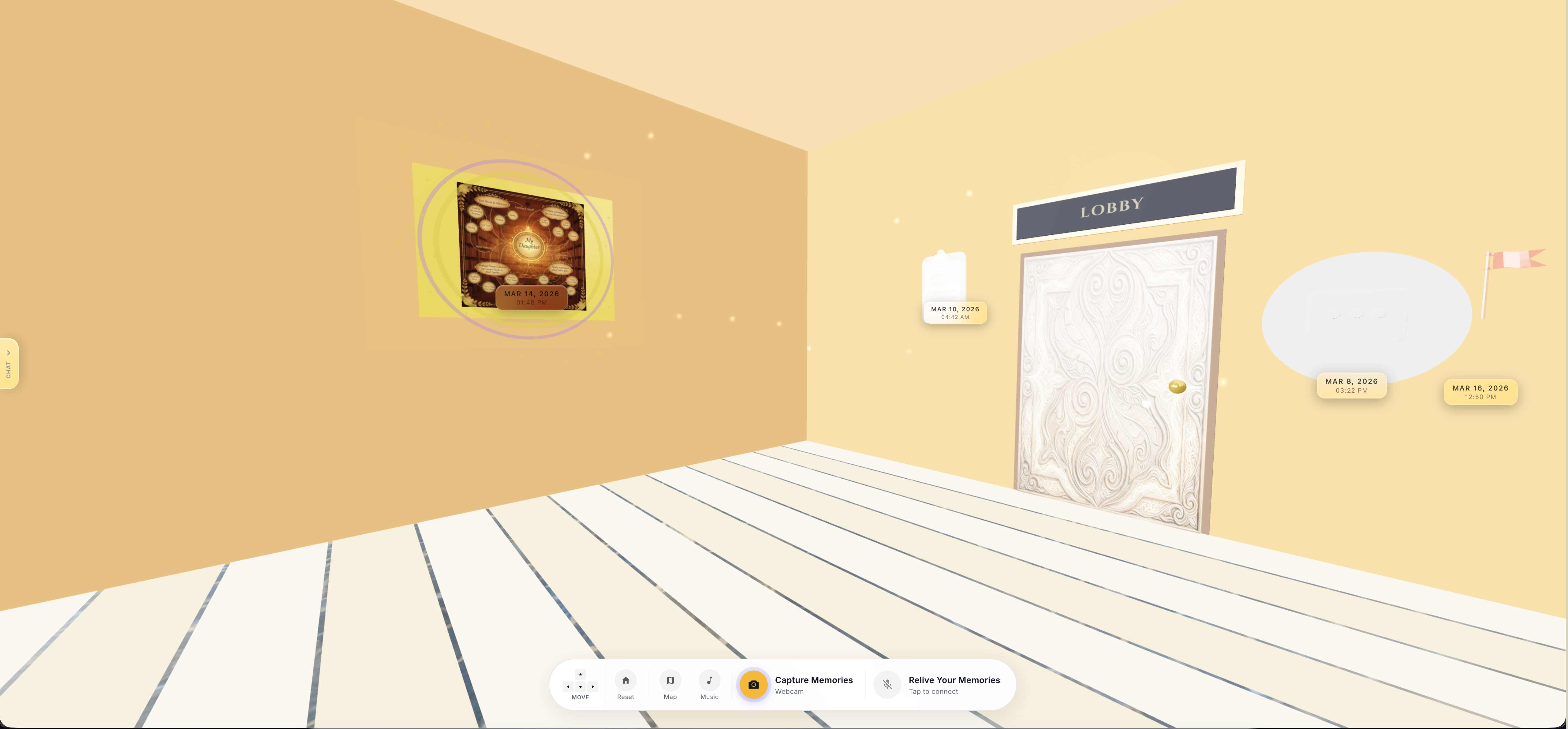
The main lobby
-
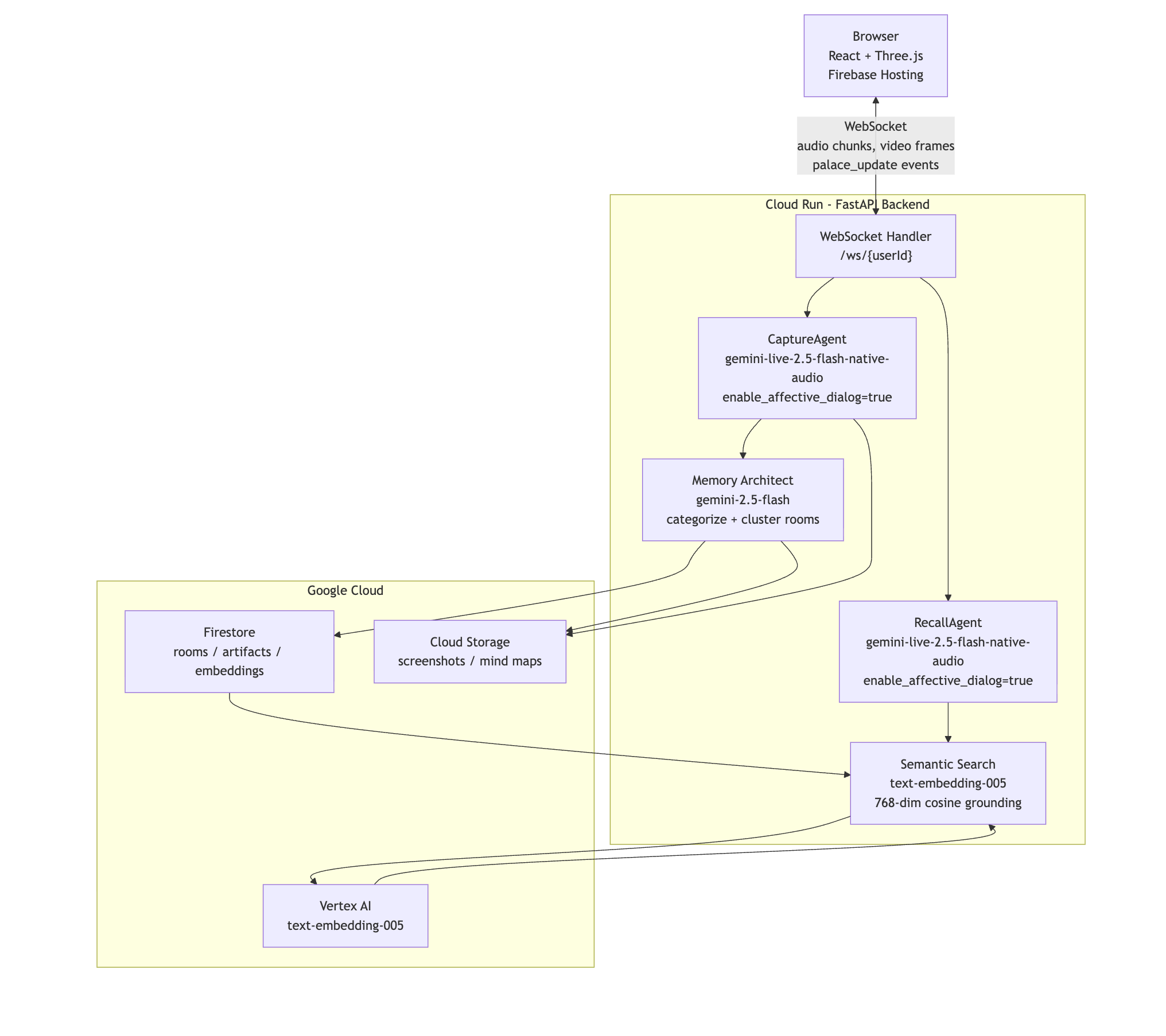
Architecture Diagram 1
-
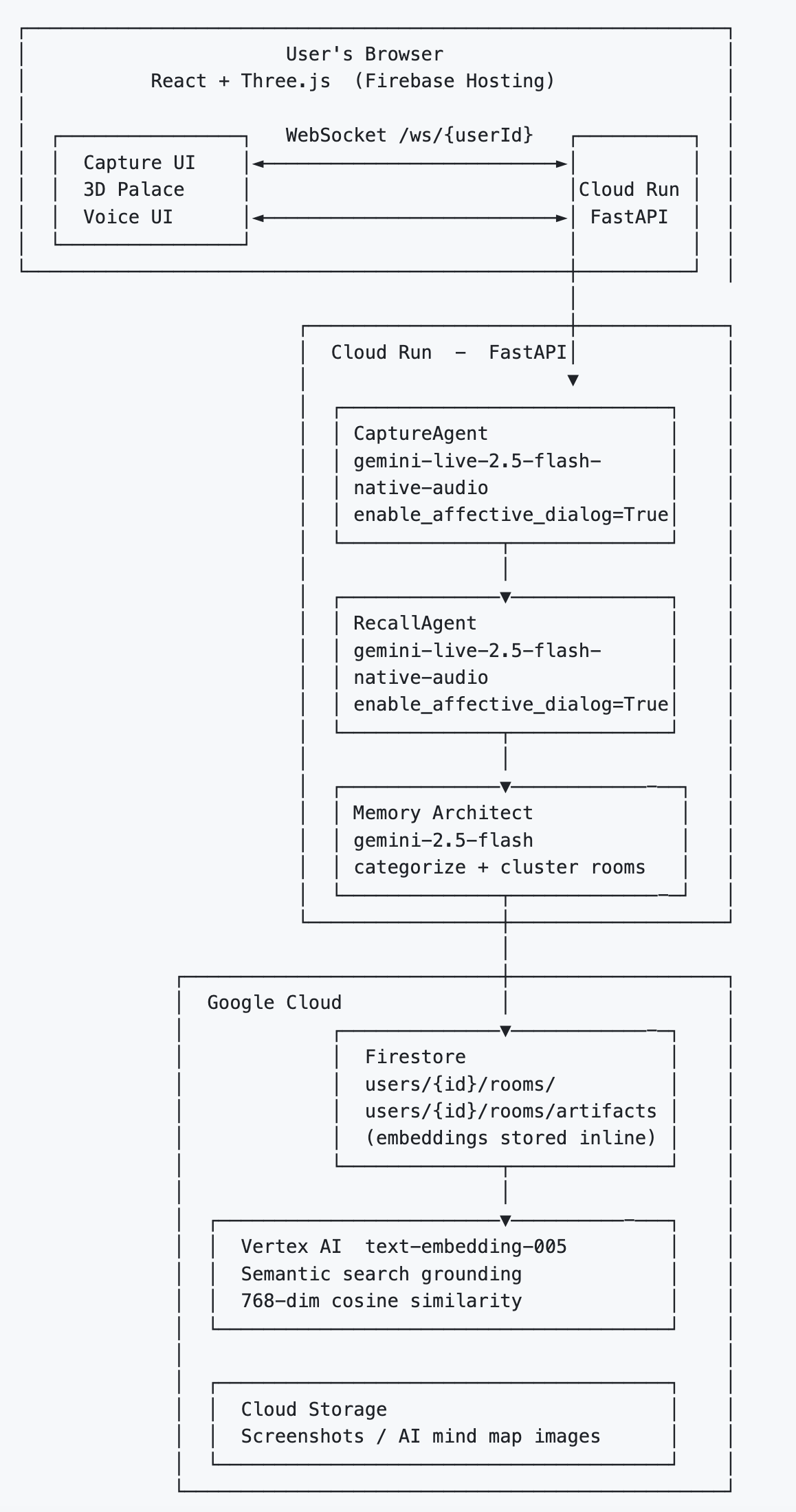
Architecture Diagram 2
-
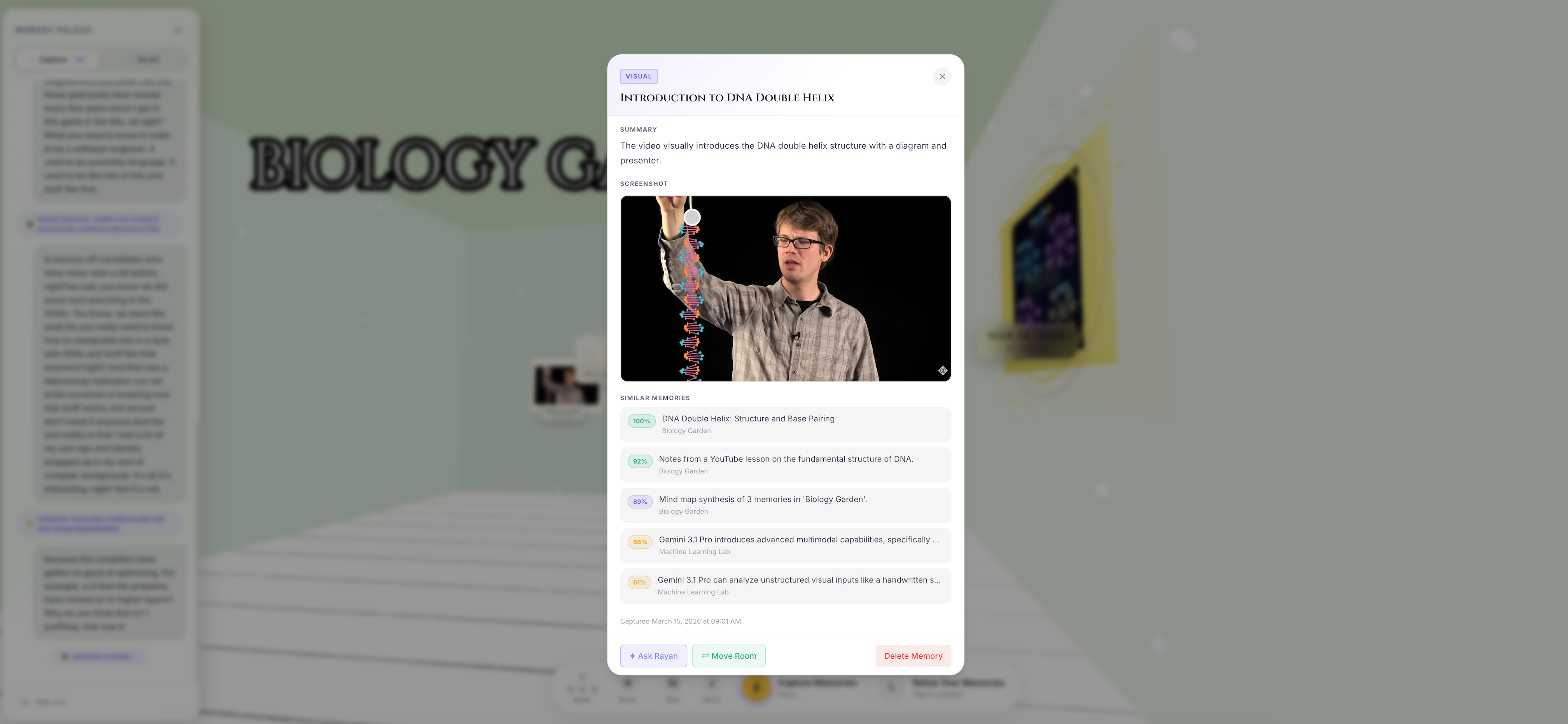
Screenshot Captured Automatically by the Capture Agent
-

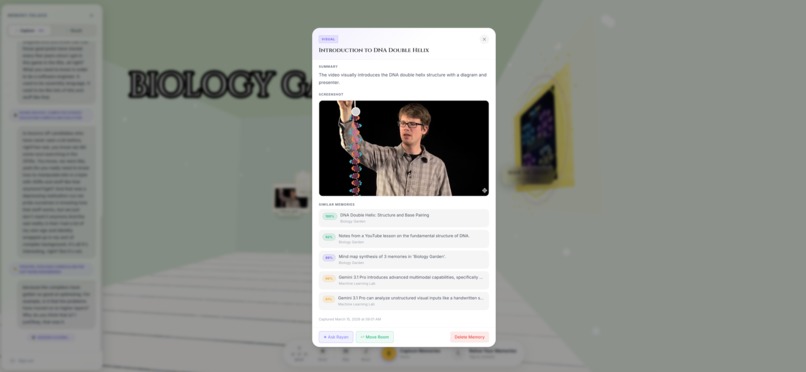
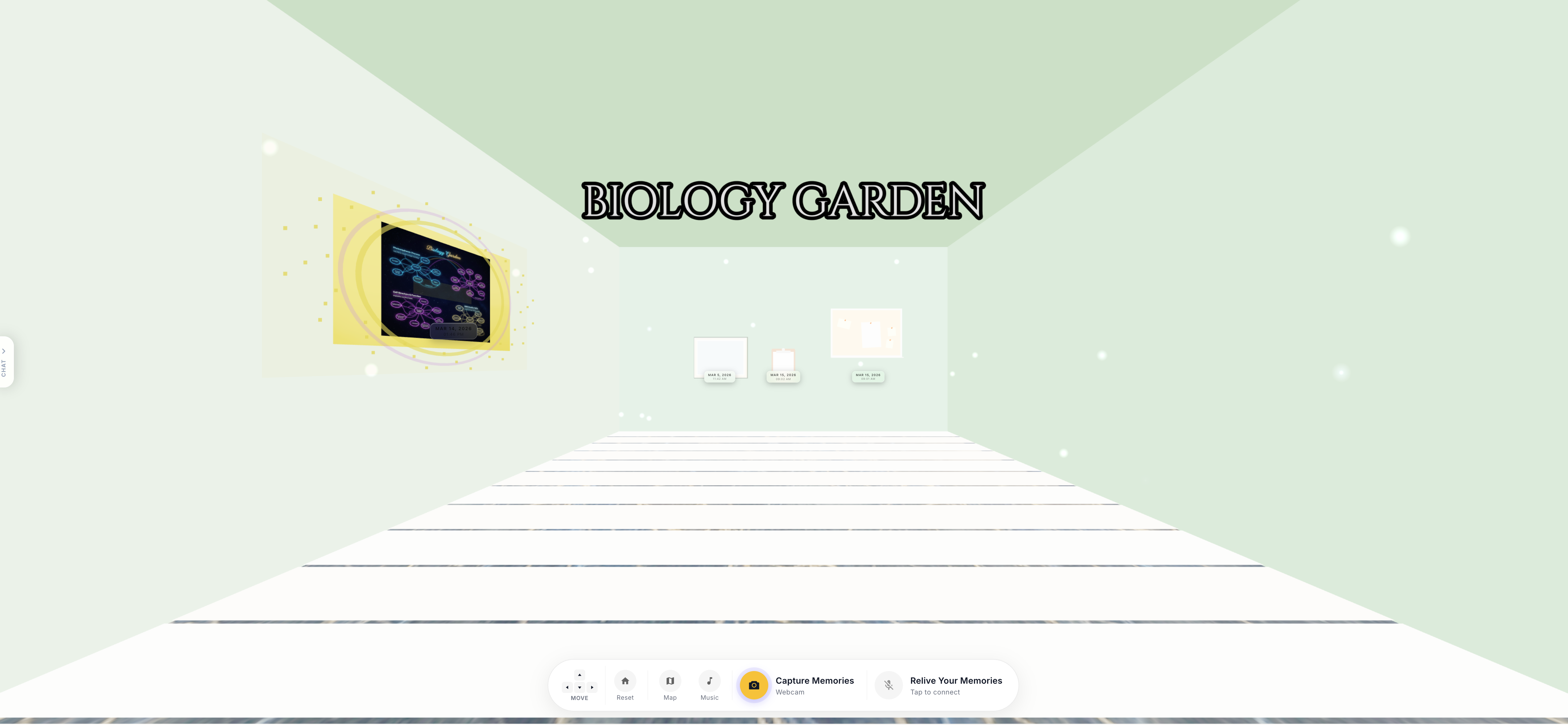
Two Memories Captured in the Biology Garden Room
-
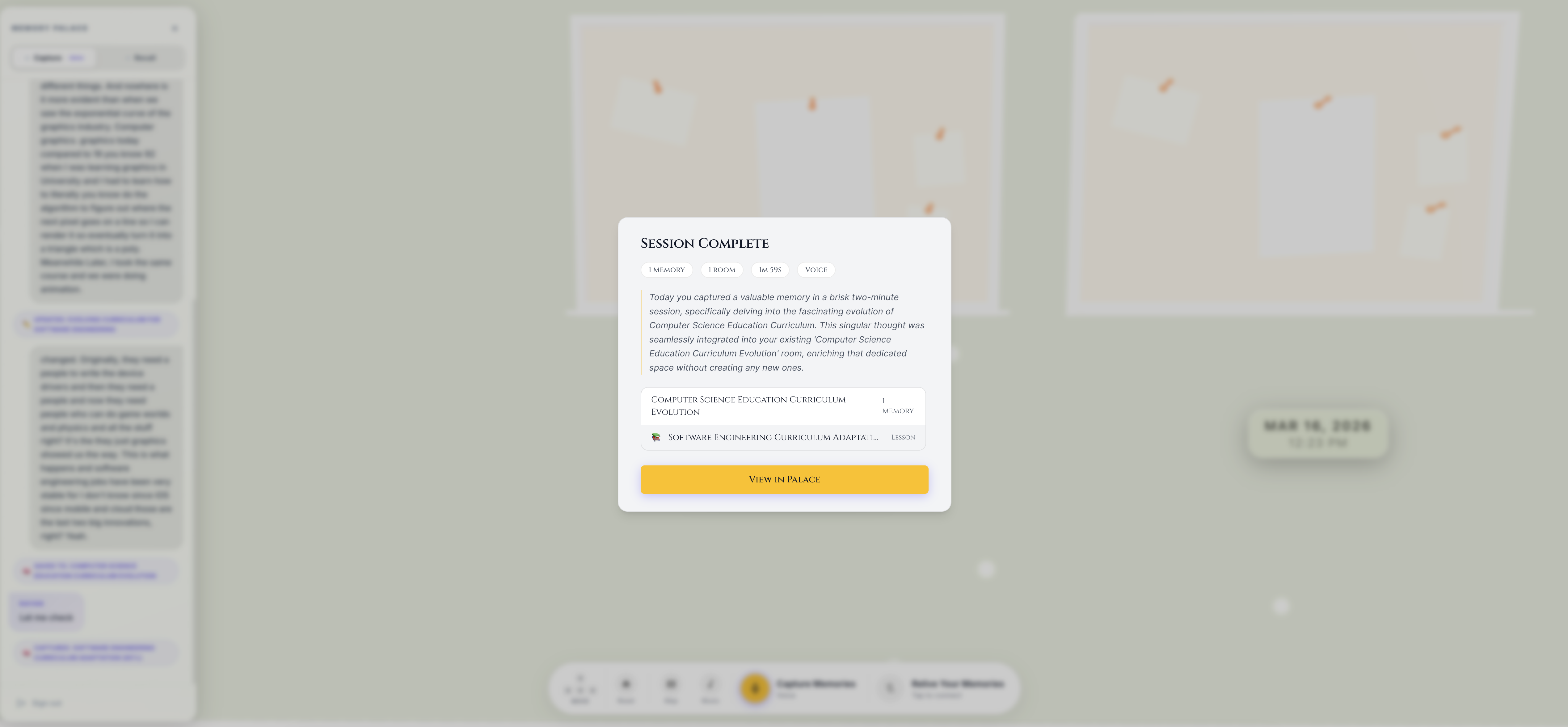
Summary of Memories Created After Capture Session
-

Map View
-

-
My Daughter Room - To be filled with all of our memories
-

Machine Learning Lab




Inspiration - The Problem Lives in My Body
I'm not talking about forgetting where I left my phone. I mean, yes, that too, and there's something particularly humiliating about searching for your phone while actively talking on it, a joke so universal that strangers laugh at it on Reddit in threads with thousands of upvotes. But the thing that actually got me wasn't the keys, or the reusable bags I leave in the car every single week, or the one item I drove to the grocery store specifically to buy that somehow escapes my mind the moment I walk through the sliding doors.
What got me was something quieter.
I was in a conversation with someone I respect. A mentor. We were talking about a book, a book I had read, underlined, and supposedly absorbed. And I had nothing. Not the argument. Not the author's name. Not even the feeling I had when I finished it. Just a vague sense that it had been meaningful, like trying to describe a dream two hours after waking.
That's when it stopped being funny.
What it does
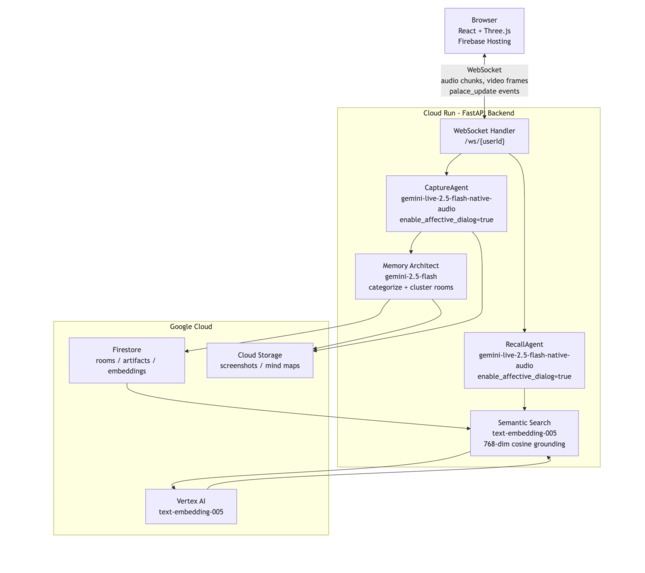
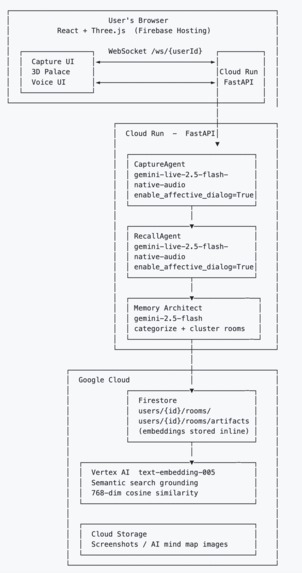
Rayan is a voice-first AI memory system. Two persistent Gemini Live agents run simultaneously in the background of a fully rendered Three.js 3D environment you navigate in first person.
CaptureAgent listens passively alongside you. Start a session during a lecture, a podcast, a meeting, a conversation. It processes your microphone and optionally your screen or camera. When it detects a concept worth keeping, confidence $\geq 0.7$, it silently extracts it: generates a title, summary, keywords, classifies the type, creates a 768-dimensional embedding via text-embedding-005, and hands it to the Memory Architect for placement. A glowing artifact appears on your palace wall in real time. You don't press anything.
RecallAgent is your voice companion inside the palace. Walk up to any room, any artifact, speak naturally. It searches your memories using cosine similarity over stored embeddings, grounds every answer in what you've actually captured, and speaks back. It cannot hallucinate things not in your palace, the system prompt enforces citation, and the retrieval is the only source of truth.
The palace isn't a metaphor. Themed rooms, glowing hologram panels, crystal orbs for formulas, framed screenshots on the walls, speech bubbles for quotes, 3D books. Sixteen distinct artifact types. You walk through it. You look around. The spatial context, that idea was on the north wall of my ML room, next to the orb about attention mechanisms, gives you retrieval cues that no flat list ever will.
Smart deduplication runs on every new capture. Near-duplicates at cosine similarity $\geq 0.90$ are merged, not added. The palace stays clean.
How I built it
The Backend: Surprisingly Smooth
The backend was honestly the easy part. Python, FastAPI, WebSockets. Gemini Live handles the persistent bidirectional audio streaming. The tool-calling architecture is clean: each agent declares a set of functions it can invoke mid-conversation , create_memory, navigate_to_room, highlight_artifact, synthesize_room, take_screenshot , and Gemini dispatches these asynchronously without breaking the audio stream at all. The moment an artifact is created, the server pushes a palace_update WebSocket event to the frontend. No polling. No page refresh. The 3D scene mutates in place, live.
The WebSocket protocol is fully typed on both ends. The RayanWebSocket client handles an auth handshake on connect, a 30-second heartbeat ping, and auto-reconnect with exponential backoff , starting at 1 second, capping at 30. Every server message belongs to a discriminated union of typed events: palace_update, live_tool_call, capture_tool_event, live_interrupted, capture_screenshot_request. Each one maps to a specific handler in the frontend with no ambiguity.
Google Search grounding is native to the Gemini agents , no third-party API, no wrapper. When Recall is asked about something not yet in the palace, it queries the live web mid-session and cites what it finds.
The creative synthesis feature uses gemini-2.5-flash-image to generate styled visual mind maps of an entire room's memories , warm parchment for a Library, holographic panels for a Lab. Not a diagram. Something closer to art.
The Frontend: Where All the Hard Work Lives
The frontend is a React + TypeScript app built around React Three Fiber and Three.js. The 3D canvas is the entire interface , there is no separate UI layer sitting on top of a viewport. Everything you interact with is inside the scene.
First-person controls, built from scratch. I didn't use any existing FPS library. FirstPersonControls.tsx is fully custom , WASD + arrow keys, right-click drag to look, scroll wheel to push forward, a mobile on-screen joystick, and single-finger touch rotation with separately tuned sensitivity. The camera sits at exactly 1.7 units height , eye level , and moves with velocity-damped physics. A damping factor of 7.0 gives that weighty, organic feel instead of stopping instantly. Dynamic FOV widens under speed, lerped against a target that adds up to 10 degrees at max velocity, so running feels fast without being disorienting. Head bob is a sin(timer × speed × 2.5) oscillation on camera Y that kicks in only above 0.5 velocity , subtle enough to feel real, not enough to nauseate. Wall collision is hard-clamped against each room's bounding box so you can never walk through a wall.
The cinematic intro. The first thing you see is not a fade-in , the camera starts at (6, 8, 35), elevated and behind the south wall, looking slightly downward into the space. Then it glides forward over 5.2 seconds using ease-in-out quadratic interpolation:
$$t_{\text{eased}} = \begin{cases} 2t^2 & t < 0.5 \ 1 - \dfrac{(-2t+2)^2}{2} & t \geq 0.5 \end{cases}$$
But there's a subtlety: the animation waits 15 frames before starting. Those 15 frames are for shader compilation and texture uploads , without that pause, the first frames of the fly-in stutter as WebGL compiles the toon materials. That one detail took an embarrassingly long time to understand.
Rooms as living environments. Each room has one of ten visual themes , library, lab, gallery, garden, workshop, museum, observatory, sanctuary, studio, dojo , each defined as explicit per-wall color palettes, ambient light color and intensity, and floor plank colors. Walls use MeshToonMaterial with a hand-crafted 4-step toon gradient texture ([40, 100, 180, 240]) that gives the space a painted, illustrated quality rather than a physically accurate render. The floor is alternating plank geometry, each plank a separate PlaneGeometry with its own toon material, giving a genuine parquet feel. Every room also has floating ambient particles , THREE.Points rendered with additive blending and a canvas-generated radial gradient soft-dot texture , drifting upward and respawning at the floor in a slow, infinite loop. In bird's-eye overview mode, each room island shows glassmorphism HTML labels floating in 3D space: room name badge, memory count, and a date range from the first to the last captured memory.
Artifacts as real 3D objects. Each artifact type maps to a GLB model , Brain.glb, Dream.glb, Headphones.glb, Hamburger.glb, Warning.glb, 24 models in total , or to a procedural mesh for special types like CrystalOrb and SpeechBubble. Every GLB has a hand-tuned scale constant derived from bounding-box analysis of the file (scales range from 0.001 for some organic models to 5 for the question mark) and a rotation correction to align its forward axis with +Z so it always faces into the room from whatever wall it's mounted on. The wallRotation() function checks the artifact's explicit wall attribute first, then falls back to spatial inference from raw x/z coordinates. Hover detection uses an invisible SphereGeometry hitbox with depthWrite: false , the visible model and the clickable surface are deliberately separate objects. Date/time plaques with glassmorphism styling float below each artifact, visible only when you are inside that artifact's room and not hovering.
The Zustand state machine that ties everything together. A single palaceStore holds the live state: rooms array, a roomId → artifacts[] map, current room, highlighted artifact IDs, and agent-selected artifact ID. When a palace_update WebSocket event arrives, addArtifact() or addRoom() fires and React Three Fiber re-renders only the changed parts of the scene. When the RecallAgent calls navigate_to_room, the frontend receives a live_tool_call message, fires a flyTo on the camera store, and the camera glides cinematically to a position near the room entrance facing inward. When highlight_artifact fires, highlightedArtifactIds updates in the store and those objects pulse with a glow shell rendered with additive blending.
Challenges we ran into
The backend wasn't the hard part. Let me be honest about where I actually struggled.
Finding the right moment to capture. Not every sentence in a lecture is a memory worth keeping. Not every thought is a concept. Getting the CaptureAgent calibrated to extract what matters, frequently enough to be useful, infrequently enough not to flood the palace with noise, required a lot of tuning. Confidence thresholds, deduplication windows, how long to wait before synthesizing multiple mentions of the same idea into one artifact. This is where the real intelligence lives, and it's subtle.
Building something useful, not just technically impressive. There's a trap in hackathons where you assemble an impressive-looking stack and call it a product. I kept asking myself: would I actually use this? Would it help someone with ADHD who loses their train of thought mid-sentence? Would it help someone in burnout who can't retain what they read? Would it help the person who blanks on a word they've known their whole life? That question forced harder choices than any technical problem. It meant cutting features that were cool but didn't serve retrieval. It meant designing the voice interaction for someone who's exhausted, not someone who wants to demo AI.
The 3D was brutal. Three.js and React Three Fiber are powerful but unforgiving. Getting the first-person controls to feel right, the cinematic intro fly-in, the smooth navigation between rooms, the touch support, the way the camera settles, took far longer than I expected. Positioning artifacts on walls without them clipping through geometry, getting the lighting to make the rooms feel atmospheric rather than flat, handling the transitions when a new artifact appears mid-session. Small things that seem trivial until you're debugging them at 2am and the hologram panel is floating six feet in front of the wrong wall.
Making the rooms actually look nice, not just functional, but beautiful enough that you'd want to spend time in them, was genuinely hard. A memory palace that feels cold and utilitarian defeats the whole point. The spatial emotion matters. I spent more time on room aesthetics than on almost anything else.
Accomplishments that we're proud of
Some of these I'm proud of because they were technically hard. Some because they were emotionally hard. Some because they work in a way I didn't fully expect when I started.
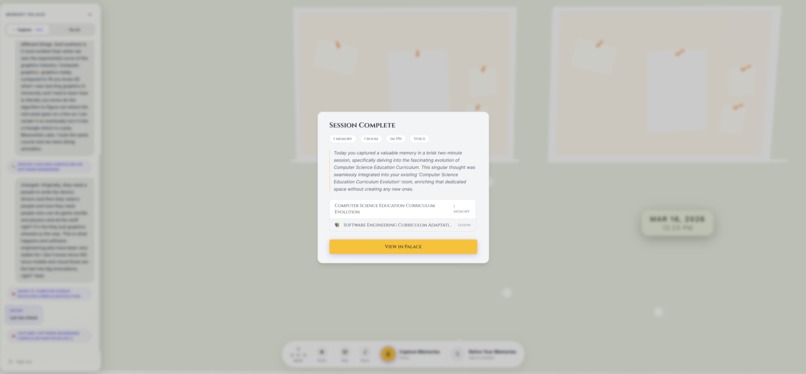
I built a real-time 3D world that updates itself while you just live your life. The moment the CaptureAgent extracts a concept, it appears on a palace wall , rendered as the right 3D object, in the right room, on the right wall, facing into the space , without you touching anything. That whole pipeline: Gemini Live → tool call → embedding → room classification → WebSocket push → Zustand state update → React Three Fiber re-render, all in a few seconds, reliably, mid-conversation. Getting that to work end-to-end without a single step breaking the audio session felt like a genuine engineering win.
The first-person controls feel like a real place. This sounds like a small thing. It isn't. Every FPS controller I've ever used in a browser felt like a toy , frictionless, sterile, disconnected from your body. The combination of velocity damping, head bob, dynamic FOV widening at speed, cinematic fly-to for agent navigation, and the 5-second intro fly-in that waits for shaders to finish before animating , together they make the palace feel inhabited. When someone walks into their ML room for the first time and looks around at the things they've captured over the past week, there's a moment of genuine recognition. I know this place. That reaction is what I was aiming for. Getting there required more care than any single feature.
Zero hallucination recall, grounded entirely in your own memories. The RecallAgent cannot fabricate. Every answer it gives is either directly retrieved from a stored artifact via 768-dimensional cosine similarity search, or explicitly flagged as coming from a live web search. The system prompt makes this non-negotiable: if the answer isn't in the palace and not findable on the web, the agent says so. In a world where AI assistants confidently invent sources and dates and quotes, building something that is constitutionally grounded in your actual knowledge felt important. It also required resisting a lot of pressure to make the demo sound smarter than the data actually supports.
Two simultaneous persistent Gemini Live sessions, coordinated without conflict. CaptureAgent and RecallAgent run at the same time. They share the same palace. A capture can happen in the middle of a Recall session , the WebSocket pushes the new artifact, the scene updates, and the RecallAgent can reference it in the same conversation, immediately. Keeping both sessions alive, ensuring their tool calls route to the right handlers, preventing race conditions in the palace state , the coordination layer was subtle and I'm proud it works as cleanly as it does.
The synthesis images. Asking Rayan to synthesize a room and watching gemini-2.5-flash-image generate a styled mind map that genuinely reflects the visual identity of that room's theme , the warm parchment of a Library, the cool holographic grid of a Lab , and seeing it appear as a framed artifact on the 3D wall, in real time, rendered inside the palace you're standing in: that feature surprised me every time during testing. It's the most overtly beautiful thing in the system and the one that consistently made people go quiet for a second.
The capture calibration actually works. Confidence $\geq 0.7$, deduplication at cosine similarity $\geq 0.90$, intelligent session-aware merging of near-identical concepts , this combination means the palace fills with things that are genuinely worth keeping and not with noise. Running the CaptureAgent through a 45-minute lecture and ending up with 8–12 clean, distinct artifacts that actually represent the structure of what was taught: that's the system working as intended. It required a lot of prompt tuning and threshold experimentation to get there, and it's still the part I'd most want to improve further.
It runs in a browser. No app install. No desktop client. A full first-person 3D memory palace with two live AI voice agents, real-time WebSocket updates, and 24 loaded GLB models , in a browser tab. That constraint forced every performance decision to be deliberate: instanced rendering for books and orbs, useGLTF.preload() for all models, the 15-frame shader settle delay before the intro animation, memo with custom equality on every artifact component. The fact that it loads and runs smoothly on a normal laptop, on the web, without plugins, still feels like something.
What I learned
Gemini Live isn't just a fast model. The affective dialogue support changes the emotional register of the whole interaction. The agent doesn't just understand what you say. It picks up on how you're saying it. When you're excited, it matches the energy. When you're tired, it softens. That's not a small thing when you're building a companion you'll use for hours.
I learned that spatial memory is real and underused. The method of loci has been documented for centuries for a reason. When I tested the palace with actual users, the most common reaction wasn't "wow, it looks cool", it was "I actually remember where things are." People started navigating by feel. The transformer stuff is in the ML room, second wall on the right. The 3D isn't decoration. It's the retrieval mechanism.
And I learned that the problem I was trying to solve, the helplessness of forgetting, the low-grade shame of not being able to retrieve your own mind,is more universal and more painful than I expected. When I explained Rayan to people, they didn't nod politely. They leaned in. They said I need this. Some of them said it quietly, like they were admitting something.
What's next for Rayan Memory
Vertex AI Vector Search at Scale
Right now, semantic search loads all artifacts from Firestore and computes cosine similarity in Python. This works at hundreds or low thousands of artifacts. Next step is activating the Vertex AI Vector Search Index already provisioned in Terraform, moving to approximate nearest neighbor search that handles millions of embeddings with sub-millisecond latency. This also opens the door to hybrid search, combining semantic similarity with keyword matching and temporal filters at the index level.
Mobile Companion App
The 3D palace works great on desktop, but real life happens on your phone. A mobile companion app (React Native or Flutter) would let you run Capture sessions from your pocket during walks, commutes, or in-person conversations, syncing everything back to your palace. The mobile experience would focus on voice-first interaction with a simplified 2D room view. The full 3D palace stays on desktop.
Collaborative Palaces
A shared palace for a study group, a project team, or a couple. Multiple users contributing memories to shared rooms, with RecallAgent understanding multi-user context. "What did Sarah capture about the API design?" The architecture already supports multi-user Firestore paths. The agent context and permission model need extension.
Spaced Repetition Engine
The palace structure is inherently spatial, which already helps memory. Adding a spaced repetition layer where Rayan proactively surfaces memories about to fade from your recall curve would turn the palace into an active learning system. "You haven't visited your Organic Chemistry room in 12 days. Want me to quiz you on the key reactions?"
Persistent Cross-Session Agent Memory
Right now, each Capture and Recall session starts fresh (though the palace itself persists). Adding persistent agent memory where Rayan remembers how you like to be spoken to, what topics you care about most, your learning style, your naming conventions would make the companion feel truly personal over months of use.
Collaborative palaces.
Right now your palace is yours alone. The obvious next step is shared rooms, a study group building a palace together during a lecture, a team capturing decisions and context from a meeting that everyone can walk through afterward. The architecture already supports multiple users per palace; the missing piece is the permissions model and the real-time merge layer.
Palace-to-palace connections.
You capture something in your Machine Learning room that directly relates to a memory a colleague has in their Statistics room. Right now those live in two separate systems. A cross-palace connection graph, opt-in, semantic similarity driven, would let you walk through a door in your palace and step into someone else's, into the specific room where that related idea lives.
Built With
- audioworklet
- canvas-api
- cloud-build
- cloud-run
- cloud-storage
- docker
- embeddings
- fastapi
- firebase-admin-sdk
- firebase-analytics
- firebase-auth
- firebase-hosting
- firestore
- framer-motion
- gcloud
- gemini
- github-actions
- google-genai-sdk
- gsap
- httpx
- javascript
- nano-banana
- pydantic
- pydantic-settings
- python
- react
- tailwind-css
- terraform
- three-js
- typescript
- uvicorn
- vertex-ai
- vite
- vitest
- web-audio-api
- websockets
- zustand






Log in or sign up for Devpost to join the conversation.