-
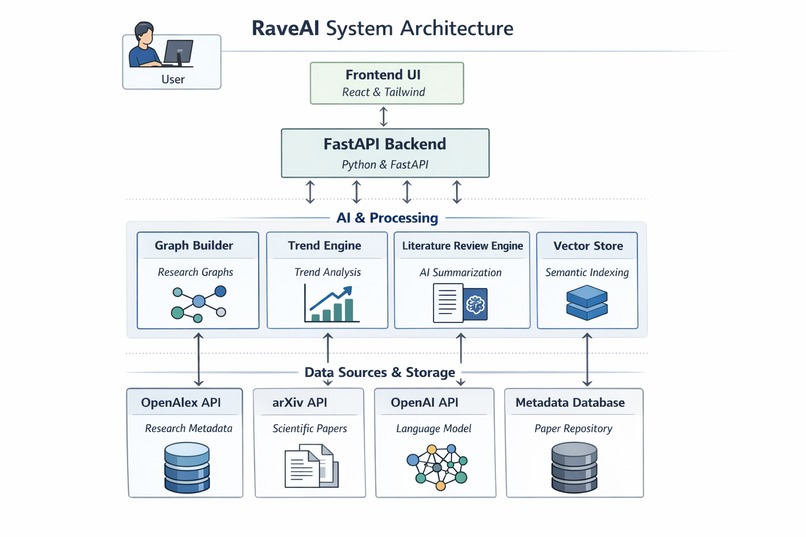
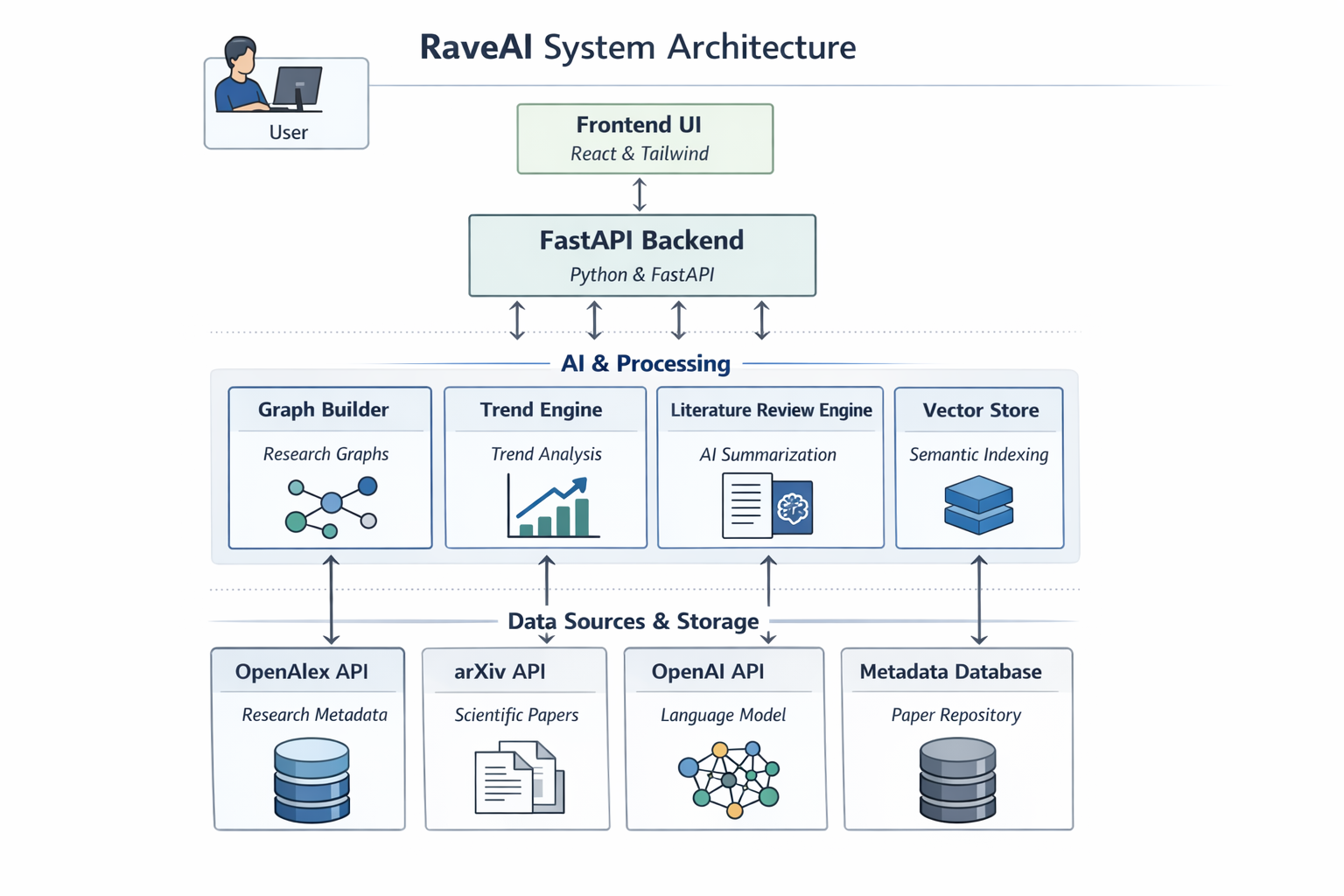
System Architecture
-
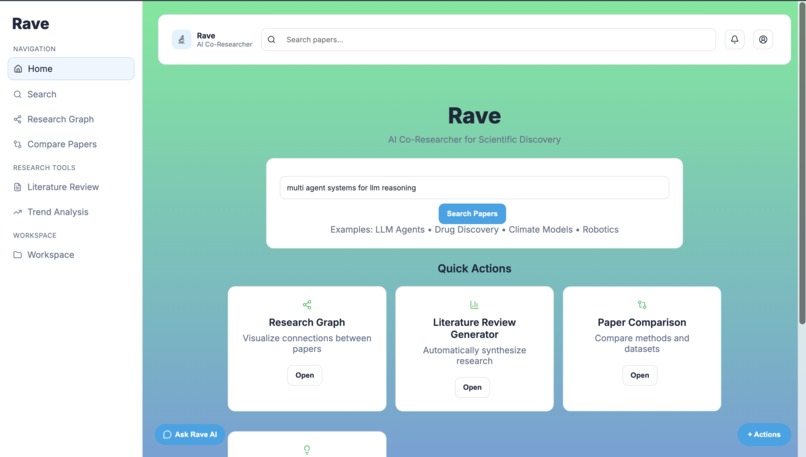
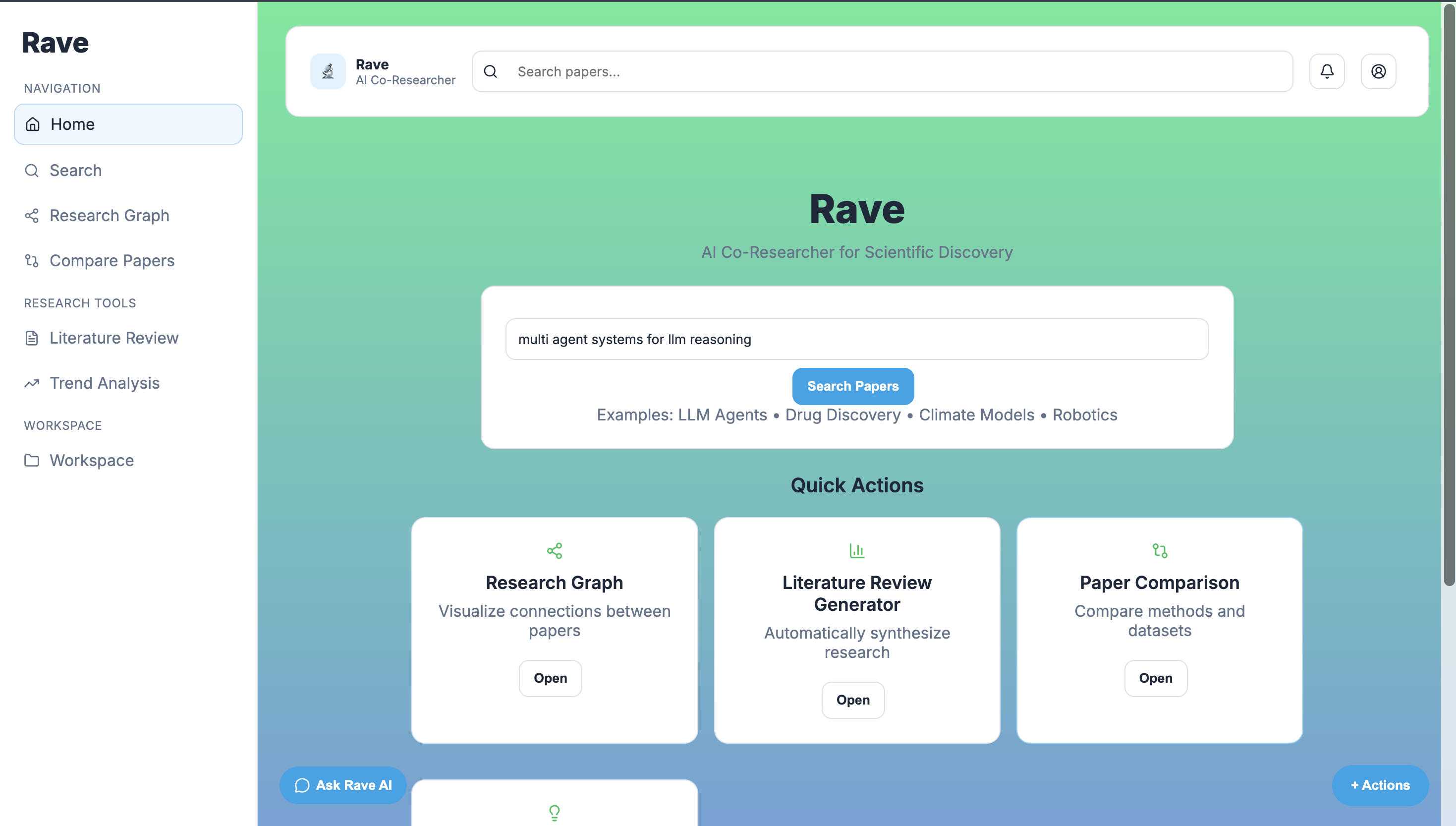
UI
Inspiration
Researchers, students, and developers spend hours searching through papers, documentation, and long PDFs just to find a few relevant insights. Traditional search tools return links, not understanding. We wanted to build something smarter — an AI system that can read, understand, and reason over large knowledge sources and give precise answers instantly. RaveAI was inspired by the idea of creating a personal AI research assistant that can analyze large collections of documents and help users discover insights faster.
What it does
RaveAI is an AI-powered research assistant that allows users to upload documents (such as PDFs, reports, or research papers) and ask questions about them conversationally.
- Instead of just searching keywords, RaveAI:
- Extracts and processes document content
- Converts text into vector embeddings
- Retrieves the most relevant information using semantic search
- Uses large language models to generate contextual answers
- Provides responses grounded in the uploaded documents Users can quickly summarize documents, ask complex questions, and explore knowledge without manually reading hundreds of pages.
How I built it
RaveAI is built using a Retrieval-Augmented Generation (RAG) architecture.
Document Processing : PDFs are parsed and split into smaller chunks for better semantic understanding.
Embedding & Indexing : Each chunk is converted into vector embeddings and stored in a FAISS vector database for fast similarity search.
Retrieval System: When a user asks a question, the system retrieves the most relevant document chunks using semantic similarity.
Answer Generation: The retrieved context is sent to a Large Language Model (OpenAI API) which generates a grounded response.
Backend: Built with FastAPI to manage document ingestion, querying, and API endpoints.
Frontend: A lightweight React interface allows users to upload documents and interact with the AI assistant.
Infrastructure: Docker for containerization, Git/GitHub for version control
Challenges I ran into
One of the biggest challenges was ensuring accurate retrieval of relevant information. If the wrong document chunks are retrieved, the AI generates weaker answers. Another challenge was managing large documents efficiently. We had to experiment with chunk sizes and embedding strategies to improve retrieval quality. Latency was also a concern when processing queries, so optimizing the retrieval pipeline and reducing unnecessary API calls was important for improving response time.
Accomplishments that I'm proud of
One of the most exciting parts was successfully building a working end-to-end RAG pipeline that can ingest documents, index them, and answer questions with context. I'm also proud of creating a system that significantly reduces the time required to analyze large documents, turning hours of manual research into seconds. The project demonstrates how AI can move beyond chatbots and become a true knowledge assistant.
What I learned
a. Building RaveAI gave me deeper insights into: b. Retrieval-Augmented Generation (RAG) systems c. Vector embeddings and semantic search d. LLM prompting and context grounding e. Designing scalable backend APIs f. Structuring AI pipelines from data ingestion to inference I also learned how important retrieval quality and prompt design are when building real-world AI systems.
What's next for RaveAI
We plan to expand RaveAI into a multi-agent AI system capable of deeper reasoning and automated research workflows. Future improvements include:
- Multi-agent research pipelines
- Support for large document collections
- Real-time streaming responses
- Integration with research APIs like arXiv and Semantic Scholar
- Knowledge graphs for better reasoning across documents
- Collaborative research workspaces
The long-term vision is to build an intelligent AI research platform that can accelerate knowledge discovery for students, developers, and scientists.
Built With
- amazon-web-services
- docker
- faiss-vector-database
- fastapi
- huggingface-transformers
- langchain/langgraph
- openai-api
- postgresql
- python
- react

Log in or sign up for Devpost to join the conversation.