-
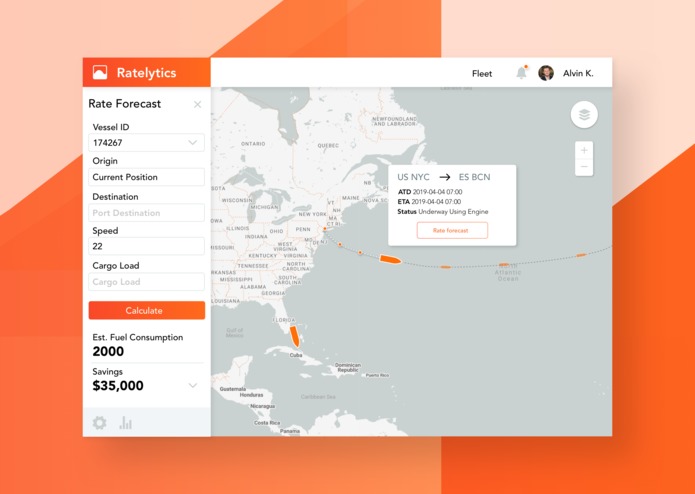
Dashboard
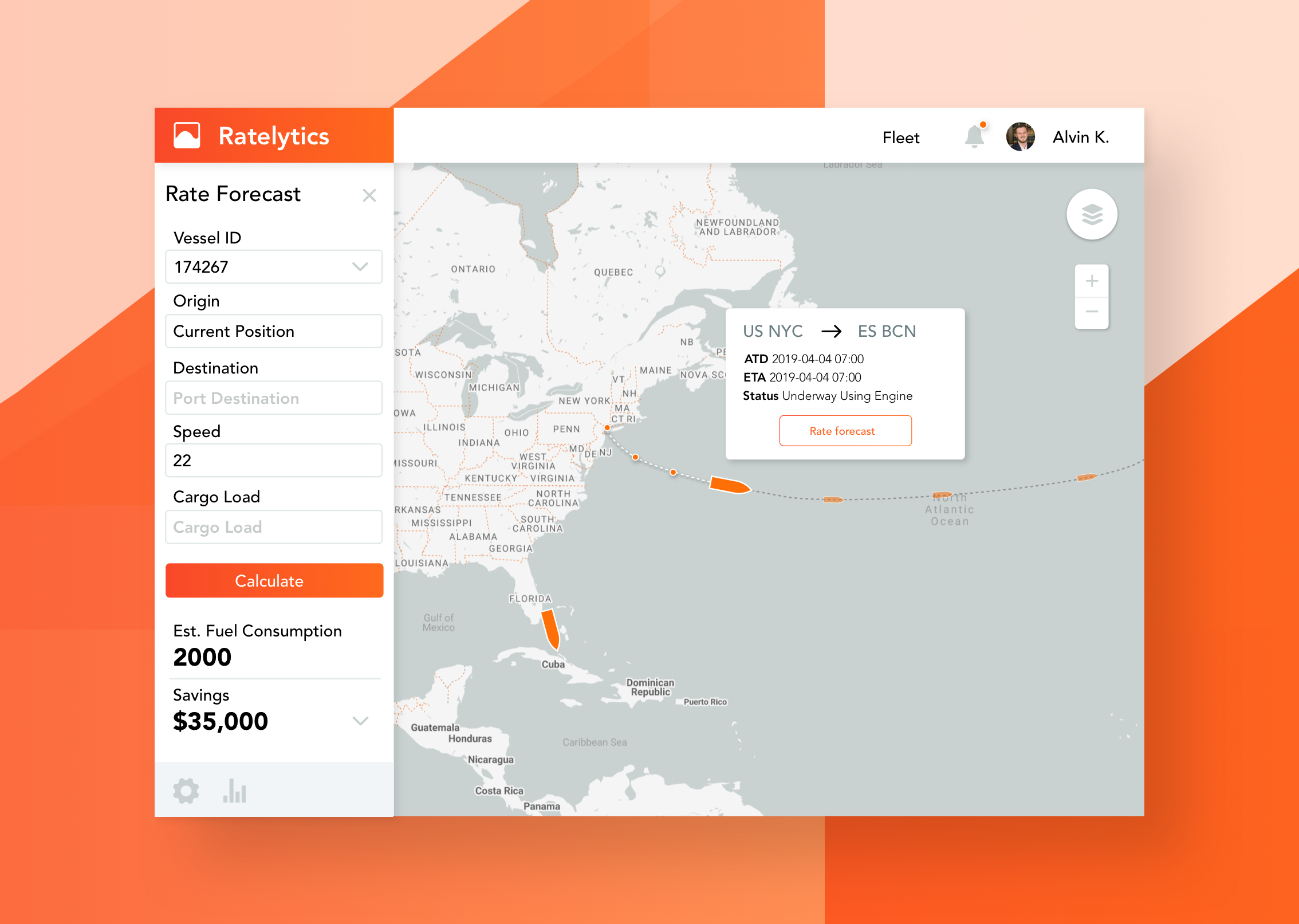
Inspiration
Fuel waste one of the biggest problems of our time. Both environmentally and financially, it is an enormous drain on resources. Maritime shipping has only increased in frequency in importance in recent years, corresponding with a boom in e-commerce and globalized trade patterns. The maritime industry, just last year, consumed approximately 2.6 million metric tons of fuel, at an average cost of $380 per metric ton.
If we save even 1% of total fuel spend - that's 26,000 metric tons unburned, at a cost savings of $100 million.
We aim to help the maritime industry reduce cost through optimizing fuel usage.
What it does
Our statistical model finds ways to save fuel while in the middle of a voyage. Through combining historical ship data with up-to-date info on ship characteristics and norms, we look for obscure optimizations which can add up to clear savings.
How we built it
We analyzed data from the Tecpier Noon Report and Lloyd's List vessel characteristics. We would like to say "thank you" to those two companies for allowing us to work with their data (and thanks to all other companies who participated as well).
In a future iteration of the project, we will combine private sources with open weather APIs and bunker price indexes to give more accurate and useful information about possible fuel savings.
Combining and analyzing these data points allowed us to gain insights into the factors that contribute to fuel inefficiencies.
Challenges we ran into
Two significant challenges were problem framing and data comprehension. When the Hackathon opened, and we formed our amazing team, we quickly settled on one problem - tackling fuel inefficiency. Our team is pretty environmentally inclined, and it was an interesting problem from an analytical standpoint as well. When we began working on the problem, however, we slowly realized that we had to make a choice - work with a much smaller dataset than anticipated, or reframe the problem entirely? We eventually settled on switching to the TecPier dataset, which, while smaller than we would have liked, included our target variable (fuel spend). This led to the second problem - data comprehension. The Noon Reports are full of industry-only abbreviations. Luckily for us, a very helpful mentor came in and gave us a crash course on maritime operational terms and concepts.
Accomplishments that we're proud of
We went from having virtually no knowledge of the industry to developing a strong preliminary product for the industry in about 18 hours. By combining the info learned over the weekend with our statistical and programming backgrounds, we developed a model that returned high accuracy ratings and succinctly illuminated some surprising fuel-spend factors.
What we learned
We learned much too much to list here, but knowledge gained included: Different measures of ship speed, including "speed over land" vs "slip speed" The various measurements of ship tonnage Congestion at ports can be very expensive, and has been increasing in frequency
What's next for Ratelytics
We are currently seeking partners who are interested in supplying us with datasets. We would like to continue building out the product with a larger collection of ship reports.
Our Team
Ratelytics is comprised of a diverse team with strongly complementary backgrounds. Our members represent four different countries and six overlapping professional fields.
Our members:
Sylvan O'Sullivan: project direction, server management, and Python-based data engineering. sylvanosullivan (at) gmail.com
Jing Li: Data Science and Analytics in R jl5358 (at) columbia.edu
Carlos Merced: UX Design and Front End Development mail.merced (at) gmail.com
Maggie Chen: Full-Stack Software Developer mchen.code (at) gmail.com
Alberto Giannetti: Data Scientist and Database Engineer with senior experience in high-frequency trading system design albertogiannetti (at) gmail.com
Raquel Hollatz: Industry specialist, with senior experience in the Maritime and Foreign Trade industries rakerholl (at) hotmail.com





Log in or sign up for Devpost to join the conversation.