-
-
Diagnostic Copilot Landing Page
-
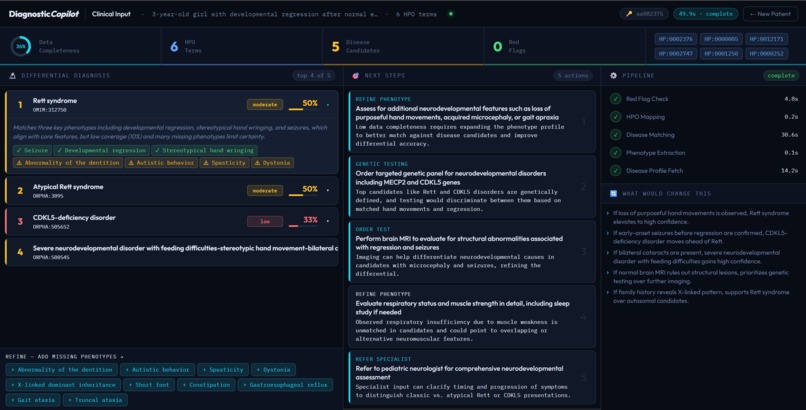
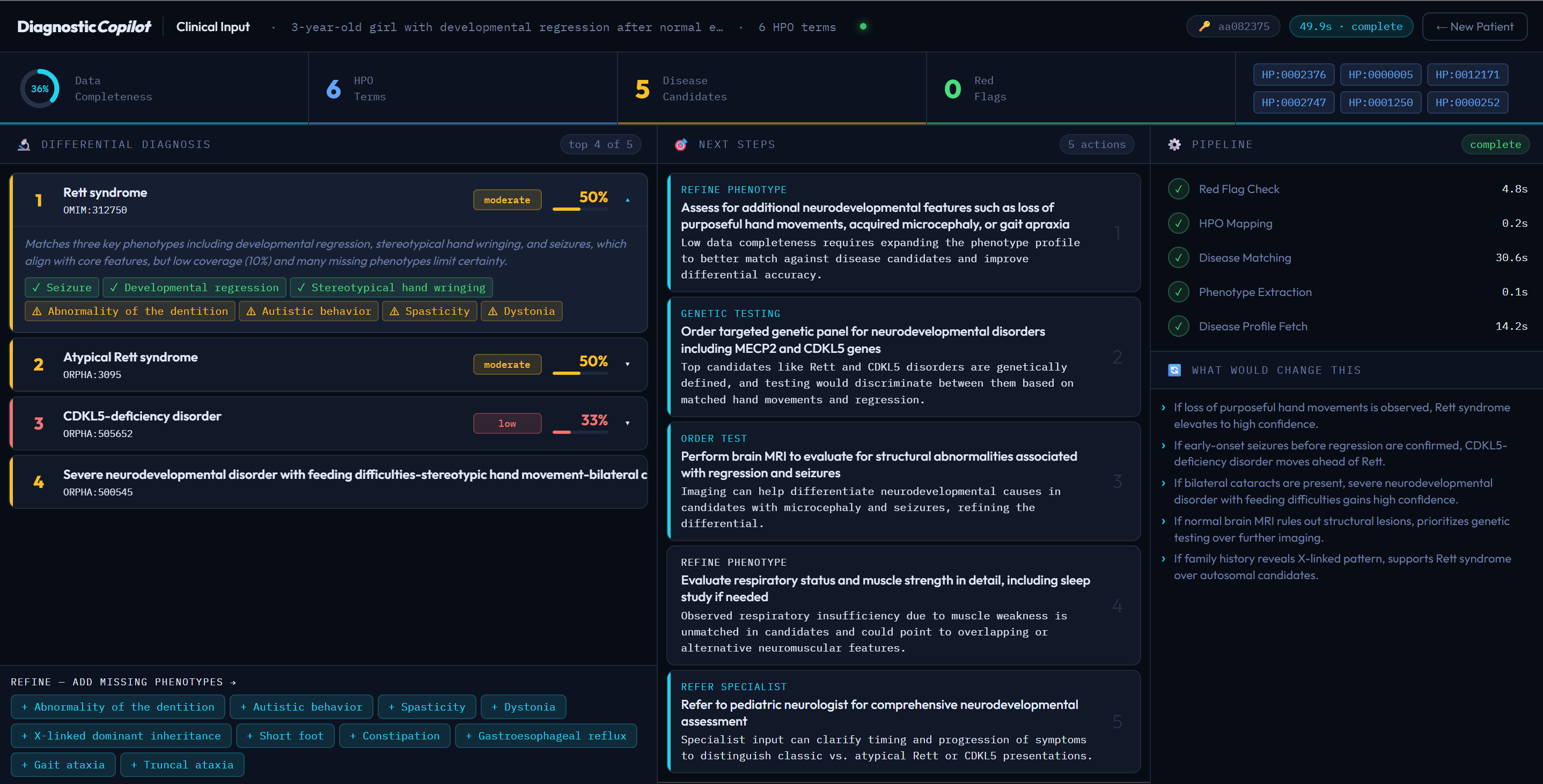
Diagnostic Copilot Clinician Dashboard
-
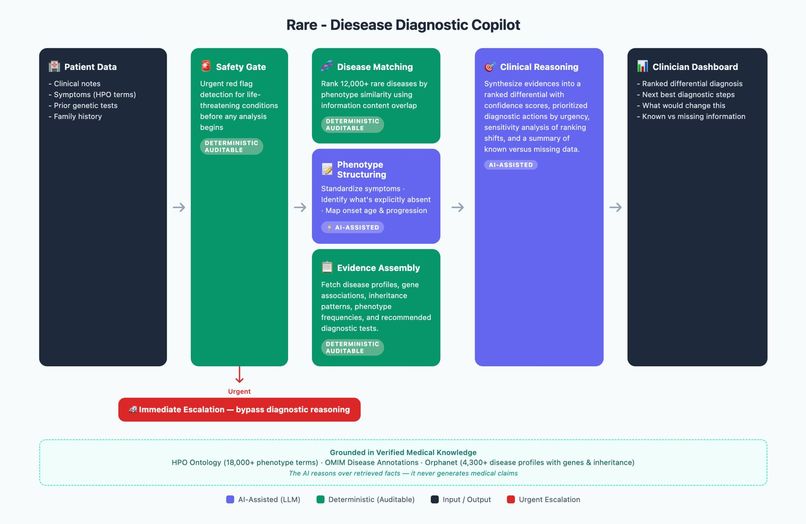
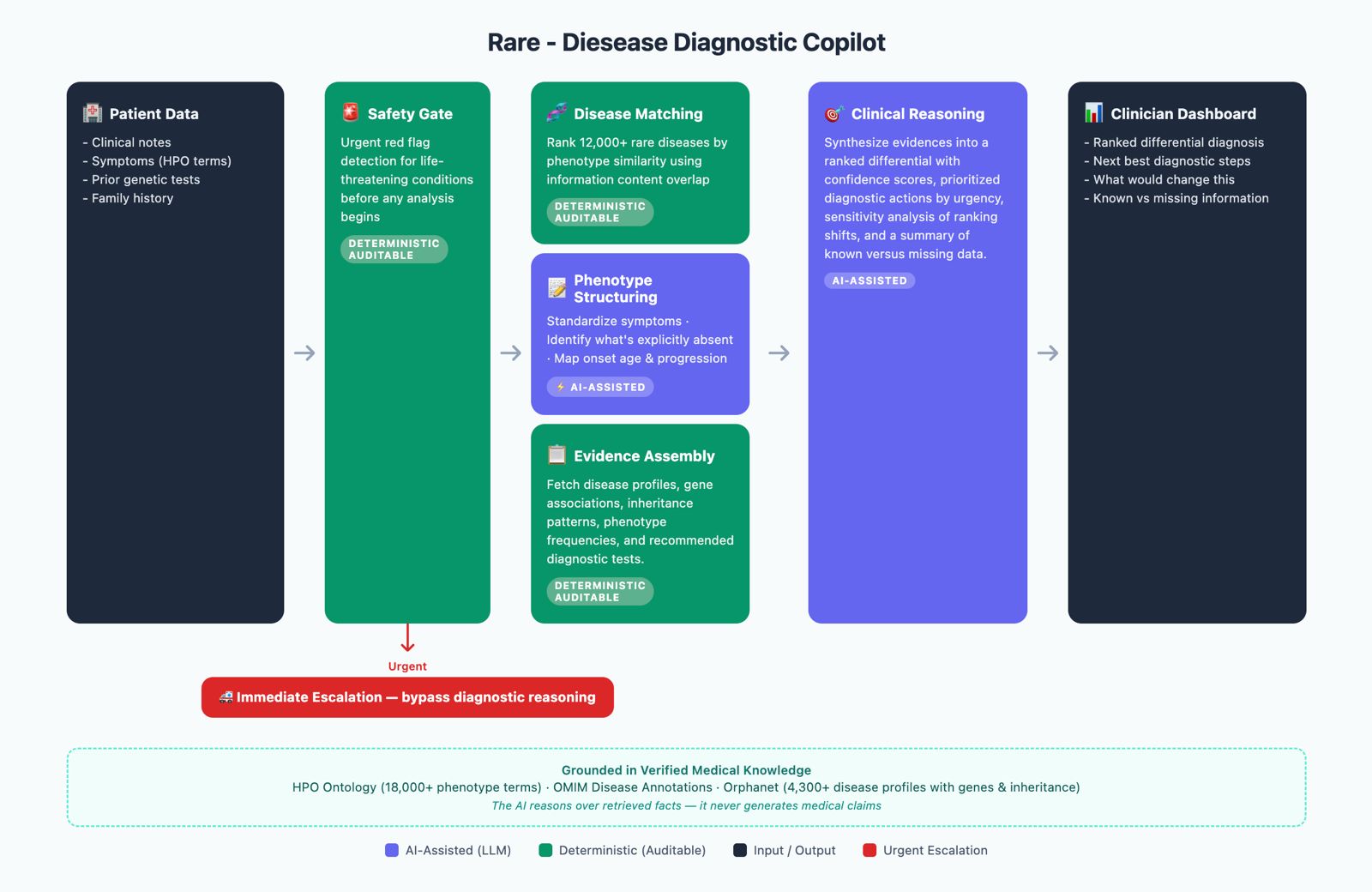
Diagnostic Copilot Workflow
Rare Disease Diagnostic Copilot
Inspiration
Rare disease patients wait an average of 4–7 years for a correct diagnosis. That's not a data problem — it's a usability problem. The data exists: HPO ontologies, OMIM, Orphanet, ClinVar. But it sits in silos while clinicians face unstructured notes, fragmented test histories, and time pressure.
We were struck by a simple question: what if the bottleneck isn't knowledge — it's synthesis? A clinician seeing a complex rare disease presentation doesn't need a textbook. They need someone to say: "Given what you have, here's the most likely explanation, here's what's missing, and here's the single most valuable next step."
That's what we set out to build.
What it does
The Rare Disease Diagnostic Copilot is an agentic, evidence-grounded decision support tool that turns messy, incomplete patient data into the next best diagnostic action — not just a disease prediction.
Given a patient's HPO-coded symptoms, clinical notes, prior genetic tests, and family history, the system:
- Screens for urgent red flags — a deterministic safety gate that triggers immediate escalation before any AI reasoning begins
- Standardises phenotype inputs — fuzzy-matching free-text symptoms to HPO codes with confidence scoring
- Ranks 12,000+ rare diseases using IC-weighted phenotype ancestor overlap:
score(D) = sum(IC(t) for t in T_p ∩ T_D) / sum(IC(t) for t in T_D)
- Detects negations and onset timing — AI reads clinical notes to find ruled-out symptoms and map progression stages
- Re-ranks with exclusions applied — penalising diseases whose profiles depend on absent phenotypes (0.5× score)
- Assembles evidence — pulling gene associations, inheritance patterns, and test recommendations from Orphanet and OMIM
- Checks data completeness — a weighted quality gate that suppresses premature disease suggestions when inputs are sparse
- Synthesises a clinician report — AI produces a ranked differential with confidence levels, prioritised next-best actions, and a transparent "what would change this" analysis
Critically: green steps are fully deterministic and auditable. AI only touches the purple steps — and even there, it reasons over retrieved facts, never generating medical claims from training data alone.
How we built it
The pipeline is a sequential agentic architecture with hard-coded guardrails at key decision points:
- HPO Ontology (18,000+ terms) loaded locally for fuzzy phenotype matching via rapidfuzz
- Orphanet & OMIM disease profiles pre-processed into structured disease–phenotype frequency tables
- Disease ranking implemented as a pure information-content overlap algorithm — no ML, fully reproducible
- Negation & timing extraction via structured prompts to an LLM, constrained to return only JSON-formatted outputs over clinician-provided text
- Clinical reasoning via a context-packet prompt — the LLM receives all prior tool outputs as structured inputs and is explicitly forbidden from introducing claims not present in the retrieved evidence
- Front-end built as a clean diagnostic dashboard designed for clinician workflows, with explicit uncertainty labelling throughout
The architecture was designed so that every non-AI step can be independently audited and replayed — a deliberate choice for clinical trust.
Challenges we ran into
Phenotype noise is brutal. Free-text clinical notes use inconsistent terminology, abbreviations, and negation patterns that don't map cleanly to HPO codes. Getting reliable fuzzy matching with meaningful confidence scores — without over-matching — required significant tuning.
Preventing AI hallucination in a medical context. The biggest architectural risk was the LLM confabulating disease associations not present in our retrieved data. We solved this by structuring the reasoning prompt as a synthesis task over a bounded context packet — the model can only reference what's been explicitly passed to it.
Completeness vs. usefulness tension. Sparse records are the norm in rare disease. An early version would confidently output disease rankings even with 2–3 symptoms. We introduced the weighted completeness gate (threshold < 0.4) to force the system to recommend phenotype refinement rather than premature diagnosis.
Equity by design. Patients with less complete records, atypical presentations, or non-English notes should not receive systematically worse guidance. We tested robustness by randomly dropping 30–60% of phenotype inputs and verifying that next-step guidance degraded gracefully — falling back to "refine phenotype" rather than outputting low-confidence disease guesses.
Accomplishments that we're proud of
- A fully auditable deterministic backbone — every disease ranking score can be traced back to specific HPO term overlaps and IC weights
- Zero AI-generated medical facts — the system is architecturally incapable of hallucinating a gene association or inheritance pattern that isn't in Orphanet
- The safety gate never touches AI — urgent escalation is rule-based, fast, and cannot be overridden by model confidence
- A clinician-facing output that answers the question clinicians actually ask: "What should I do next, and why?" — not just a ranked list of diseases
- A design that degrades gracefully under data sparsity rather than outputting false confidence
What we learned
Building for clinical trust is a different problem than building for accuracy. A system can be highly accurate on benchmarks and still be unusable in practice if clinicians can't inspect, challenge, or override its reasoning.
The most important architectural decision we made was separating what the AI is allowed to do from what the system outputs. The LLM is a synthesis engine, not a knowledge source. That distinction — enforced structurally, not just through prompting — is what makes the output defensible.
We also learned that uncertainty quantification is a feature, not a disclaimer. Clinicians trust a system more when it says "I have low confidence here — here's what's missing" than when it presents a clean top-5 list with no caveats.
What's next for Rare Disease Diagnostic Copilot
- Stepwise case replay validation — retrospective testing on curated rare disease vignettes to measure steps-to-correct-diagnosis versus a disease-ranking-only baseline
- Calibration analysis — does stated confidence correlate with correctness? We want to publish a calibration curve
- VUS reanalysis triggers — integrating ClinVar to detect when a prior variant of uncertain significance should be re-evaluated in light of new phenotype data
- Multilingual note ingestion — extending negation and timing extraction to non-English clinical notes to improve equity for underserved populations
- Clinician-in-the-loop feedback loop — capturing accept/reject/modify signals on recommendations to continuously improve next-step ranking without retraining on medical claims
- Integration with EHR systems — moving from a standalone tool to an embedded copilot that surfaces recommendations at the point of care

Log in or sign up for Devpost to join the conversation.