Inspiration
Rare diseases affect 300+ million people worldwide, yet the average diagnosis takes 5-7 years. Doctors lack access to consolidated, up-to-date information scattered across medical databases. We built RDDA to bridge this gap using AI.
What it does
RDDA is an explainable, RAG-based AI assistant that:
- Retrieves real-time data from PubMed, Orphanet, and FDA APIs
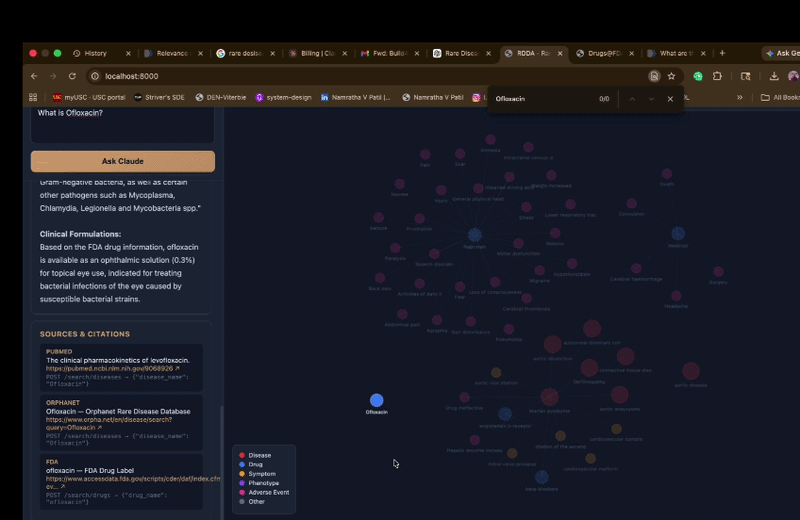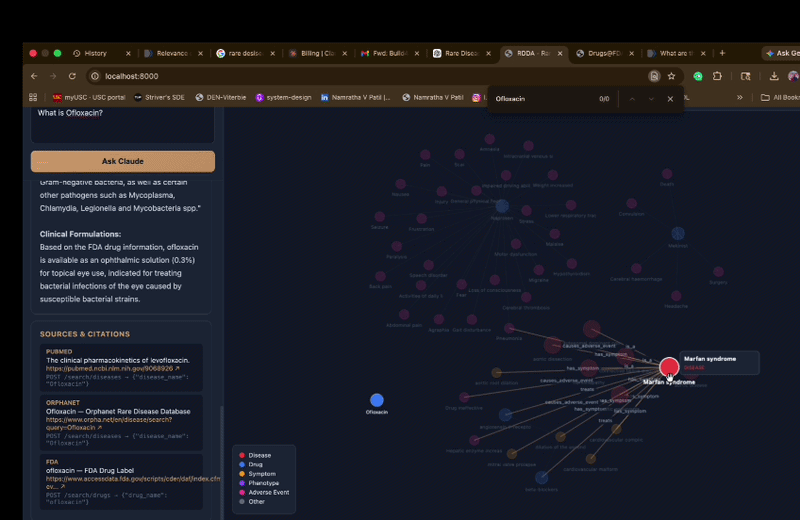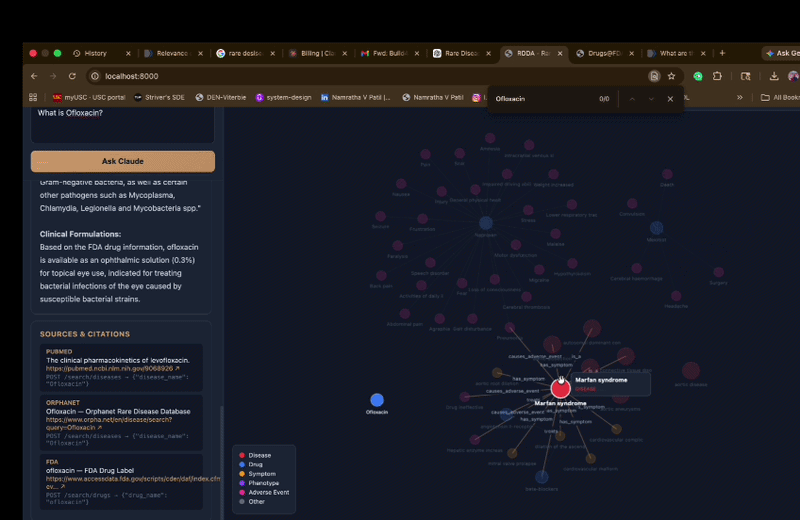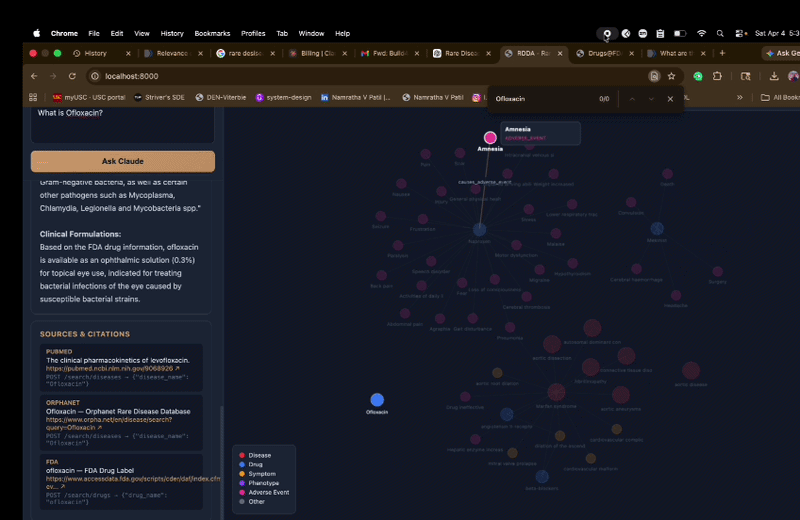
- Builds an interactive knowledge graph linking diseases, drugs, symptoms, and phenotypes
- Uses Anthropic Claude to generate evidence-based answers with source citations
- Self-assesses confidence (0-1) and auto-generates follow-up questions when uncertain
How we built it
- Data Collection — PubMed (NCBI E-utilities), Orphanet (REST API), FDA (OpenFDA) fetch medical data in real-time
- Text Chunking & Embedding — Documents split into overlapping chunks, embedded using Sentence Transformers (all-MiniLM-L6-v2)
- FAISS Vector Search — Semantic similarity search over 1500+ indexed chunks
- Claude RAG Generation — Anthropic Claude synthesizes answers from retrieved context with inline citations
- Knowledge Graph — NetworkX graph with interactive canvas-based visualization
- Confidence Scoring — Two-stage: FAISS retrieval score + Claude self-assessment
Anthropic Claude Integration (4 uses)
- Medical Entity Extraction — extracts diseases, drugs, symptoms from free text
- RAG Answer Generation — generates cited answers from PubMed/Orphanet/FDA context
- Confidence Self-Assessment — rates answer confidence, triggers follow-up questions if < 0.7
- Knowledge Graph Unification — merges entities across data sources into unified graph
Challenges
- Rate limiting on Claude API during rapid-fire queries (entity extraction + RAG run simultaneously)
- Building real-time knowledge graphs from 3 different API formats with different schemas
- Ensuring citation URLs point to actual source pages, not just API endpoints
What we learned
- RAG with domain-specific medical data produces significantly better answers than general LLM queries
- Confidence self-assessment adds crucial transparency for medical AI applications
- Multi-source data fusion (PubMed + Orphanet + FDA) provides more comprehensive answers than any single source
Built With
- anthropic-claude
- docker
- faiss
- fastapi
- html5
- javascript
- networkx
- python
- sentence-transformers
- spacy

Log in or sign up for Devpost to join the conversation.