-
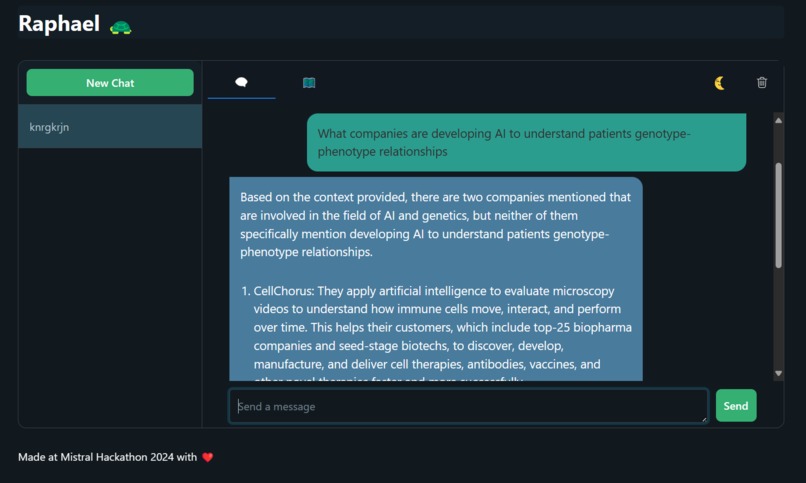
Raphael example idea chat
-
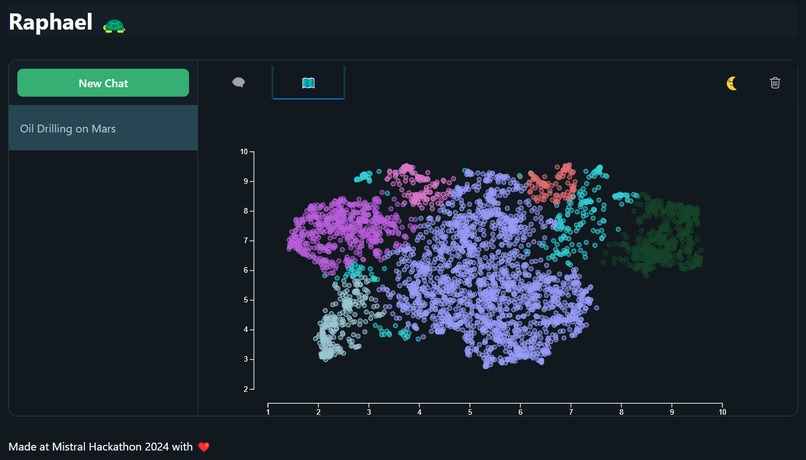
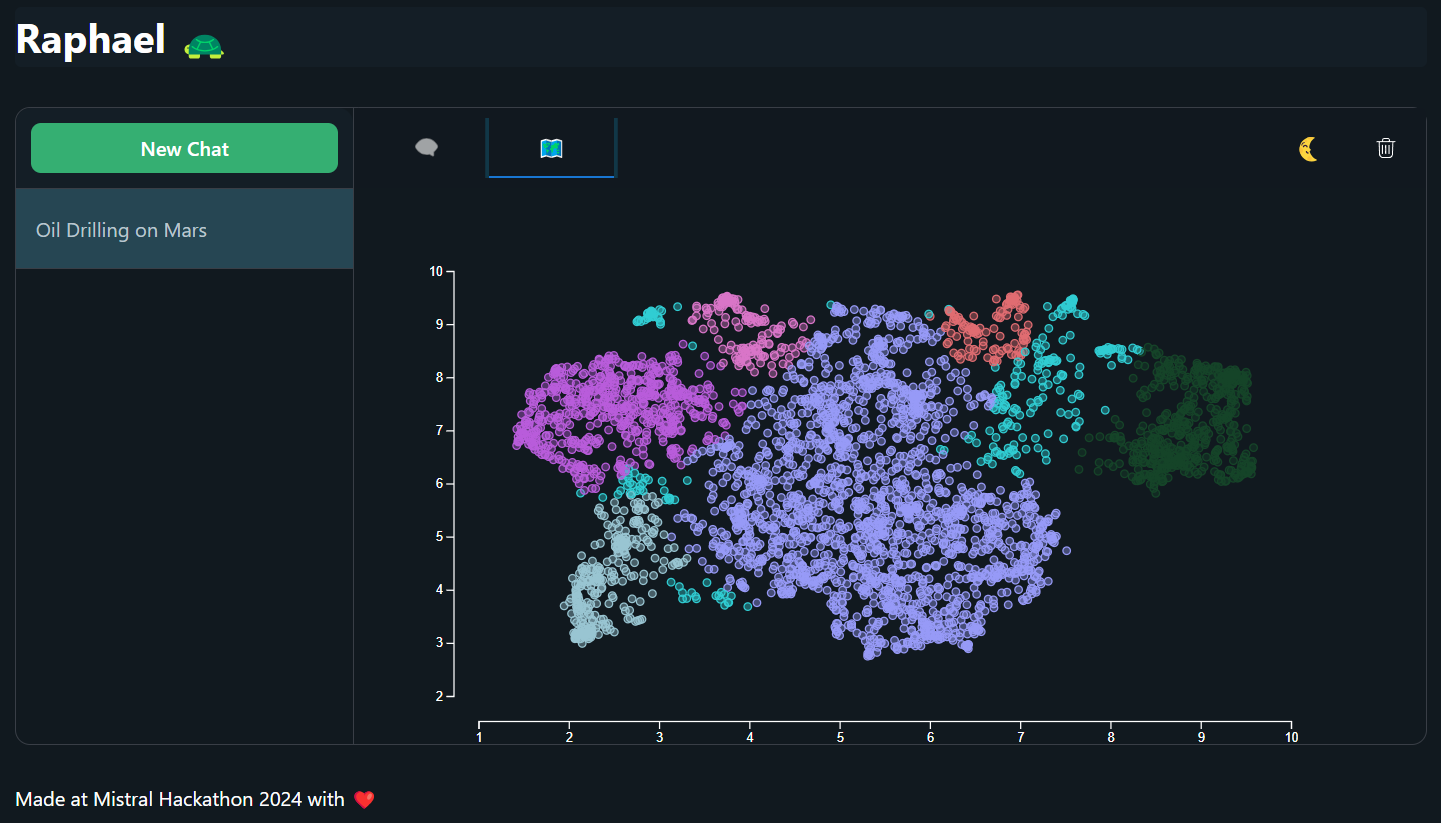
Graph of company landscape
-
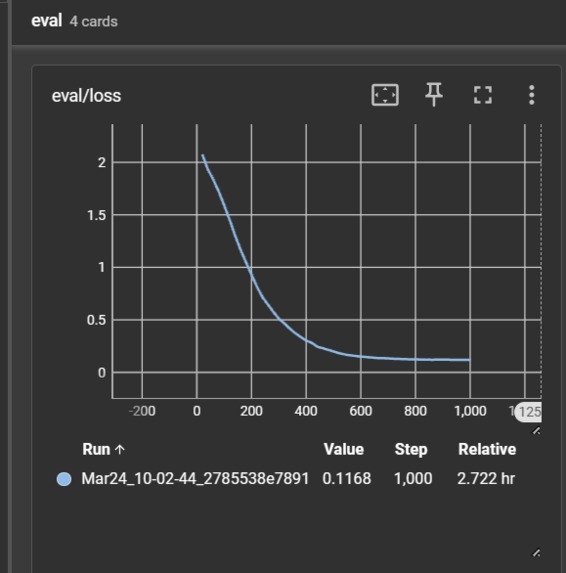
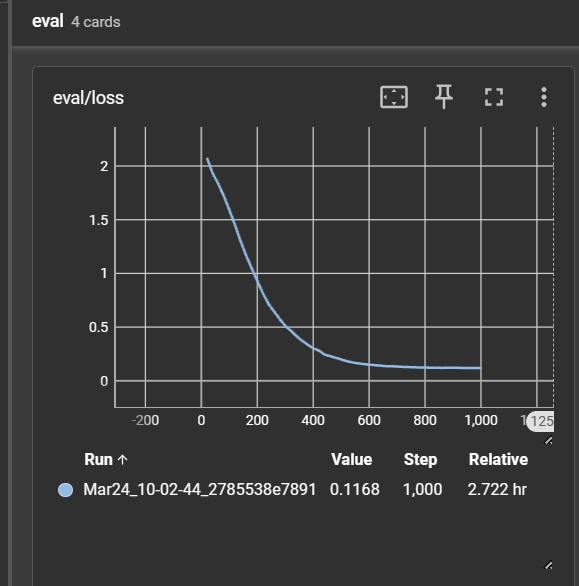
RAFTphael training loss
Inspiration
Standing at the intersection of finance and technology, we recognize that investors and innovators struggle with the same tedious process to learn about new companies and emerging markets. Angel investors and venture capitalists search across hubs of data, seeking novel startups working in a profitable niche, while founders look through the same hubs to identify their "edge" against potential competitors. Raphael streamlines the research process, aggregating data across standard hubs including YCombinator, AngelList, and BetaKit to provide unique insights through metrics and interactive visualizations.
We even realized that builders struggle when brainstorming novel ideas; for us, reducing this friction means we "fail earlier, fail more often, and always fail forward.
What it does
You miss 100% of the shots you don't take, right? Whenever a new idea pops into your head, rather than letting it rot away in an idea notebook that you rarely open, send Raphael your idea! Raphael is an experienced mentor who you can ask for insights on your idea. It will provide an interactive plot of where your idea lies in the current market landscape, as well as a score to identify your most unique ideas.

How we built it
Raphael was built on top of our custom fine-tuning recipe, RAFTphael. To implement this newly released paper, we started out creating a company descriptions embedding before working through the following steps:
Data Collection:
- We started out by identifying public sources of data to scrape. We settled on well-known sources in the forms of YCombinator, AngelList, and BetaKit (Canadian Startup News). Crunchbase's data was unfortunately locked behind API paywalls.
- We were interested in the company descriptions, as these would be useful for our RAG/RAFT model. For YC and AngelList, companies have individual pages which we were able to scrape using standard python scraping techniques. However, for BetaKit, company information was scattered throughout unstructured news articles. After retrieving article data, we asked Groq to identify the company of interest (if any) as well as a short description of the company.
Pre-Processing:
- RAFT requires document-based QA structure. To train our model using RAFT, we needed to generate questions, answers, and document groups.
- To select companies with a clear ground truth, we first asked mistral to generate ten word descriptions of these companies. We then fed these descriptions back into the embeddings model; if it correctly identified the same company, then we could include this as part of our dataset, as they provide a differentiated product which would have a clear oracle document.
- For each query we took a few random embeddings (NEQ to the oracle) to use as distractor documents.
Dataset Generation:
- We settled on P = 0.5, which meant that half of our rows contained an oracle document (golden value, the description of the company) and half contained no oracle document (only distractor documents, the goal is for the model to "memorize" the correct answers).
- We used the randomly generated keywords from the pre-processing step to form the question, the answer was the name of the company, and documents were descriptions of companies (with the oracle document being the description of the correct company).
- You can learn more about RAFT here.
Model Finetune:
- We fine-tuned our model with the above dataset using DoRA.
Inference!
- We ended up running on MistralAPI, as we had issues running inference with the RAFT fine-tuned model
Challenges we ran into
- Struggling to find an initial idea (meta, right?)
- Conflicting package versions of mistral and weaviate in Docker (there was no v4 release of weaviate with matching httpx versions), forcing us to rewrite out Flask endpoint
- Hosting fine-tuned model on fireworks.ai (sadly, no support for DoRA)
- High latency during inference because using remote 3090 on East Coast
What's next for Raphael
There are a myriad of ways in which we would have liked to extended Raphael, given more time:
- RAG re-ranker
- Visualized query embedding in latent space
- Scoring function using cosine similarity
- Unrelated input filter with Langchain
- Improvements on data quality and quantity
- Lowered latency through cloud compute
- and many more!


Log in or sign up for Devpost to join the conversation.