-
-
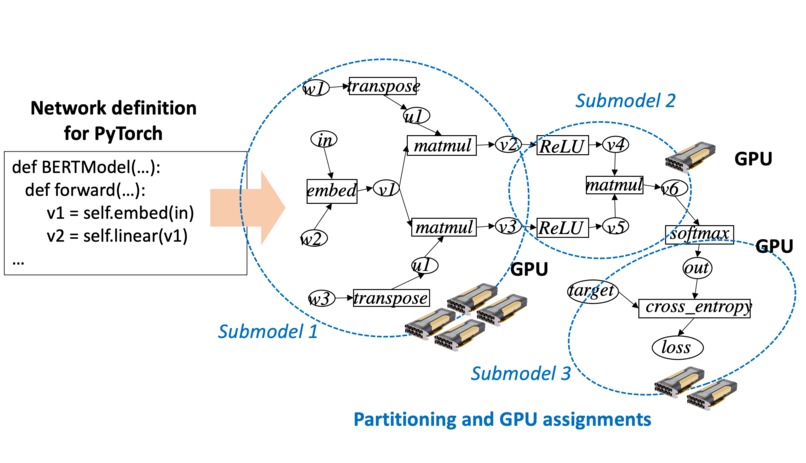
Hybrid parallelism by RaNNC
-

Overview of RaNNC
Inspiration
As exemplified by GPT-3, the sizes of neural networks have been rapidly increasing in the past few years. Since such extremely large models do not fit into the memory of a single GPU, they need to be partitioned for model parallelism.
Existing frameworks for model parallelism require users to significantly rewrite model definitions for model partitioning. This is usually very hard even for experts. In addition, some of these frameworks, like the well-known Megatron-LM, are applicable only to Transformer-family networks like BERT.
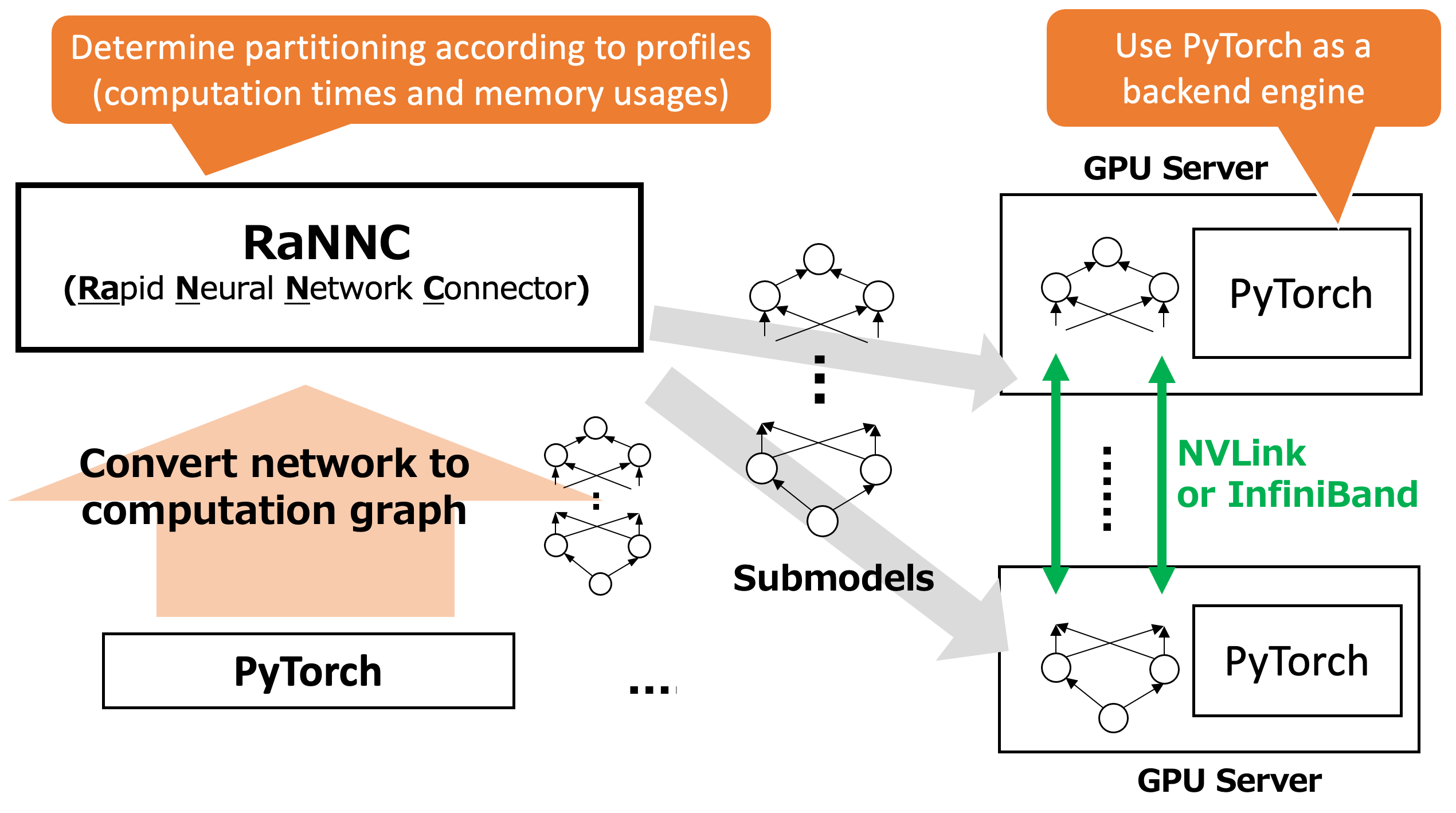
To address these problems, we developed a middleware called RaNNC, which can automatically partition various types of networks and parallelize the training.
What it does
Given the definition of an existing neural network written for PyTorch, RaNNC automatically partitions a neural network to fit it into the memory of each available GPU and also optimizes the training throughput using multiple GPUs. This way, developers do not need to rewrite the neural network definitions for partitioning, which makes training of large-scale neural networks much easier.
The code below shows a simple usage of RaNNC (The complete code is available in our tutorial).
model = Net() # Define a network
model.to(torch.device("cuda")) # Move parameters to a cuda device
optimizer = optim.Adam(model.parameters(), lr=0.01) # Define an optimizer
model = pyrannc.RaNNCModule(model, optimizer) ####### Insert this line ######
loss = model(input) # Run a forward pass
loss.backward() # Run a backward pass
optimizer.step() # Update parameters
Models used with RaNNC do not need special operators for distributed computation or annotations for partitioning (See our examples: model for the tutorial, enlarged versions of BERT and ResNet. All these models are defined using only PyTorch's normal functions).
In contrast, for example, Megatron-LM needs special operators like ColumnParallelLinear and RowParallelLinear
(See a typical usage in Transformer).
Implementing a model using such operators is very hard even for experts because the user needs to consider computational loads
of the model, memory usage, and communication overhead.
In addition, some existing frameworks (including Megatron-LM) can only be applied to Transformer family networks.
RaNNC partitions a model to submodels so that each submodel fits to a GPU memory and that a high training throughput is achieved. Submodels are replicated for data parallelism whenever possible (hybrid data/model parallelism).
We conducted some experiments using enlarged BERT and ResNet to evaluate the performance of RaNNC. The results showed that RaNNC achieved better or similar throughputs compared to other frameworks although RaNNC . See our paper for the details of the experiments (preprint):
Automatic Graph Partitioning for Very Large-scale Deep Learning, Masahiro Tanaka, Kenjiro Taura, Toshihiro Hanawa and Kentaro Torisawa, In the Proceedings of 35th IEEE International Parallel and Distributed Processing Symposium (IPDPS 2021), pp. 1004-1013, May, 2021.
How we built it
RaNNC first converts a model definition for PyTorch to a computation graph. Next, it partitions the graph into fine-grained submodels. Then, RaNNC tries to find combinations of the so that (1) each submodel fits a device memory and (2) a high training throughput for pipeline parallelism is achieved by balancing the computation times of the submodels.
Since the search space for partitioning models can be extremely large, RaNNC partitions a model through the following three phases. First, it identifies atomic submodels using simple heuristic rules. Next it groups them into coarser-grained blocks while balancing their computation times. Finally, it uses a novel dynamic programming-based algorithm to efficiently search for combinations of blocks to determine the final partitions.
Refer to our IPDPS 2021 paper (preprint) for the details of the algorithm.
Challenges we ran into
When designing RaNNC, we focused on the compatibility with PyTorch's APIs and kept the same interface as PyTorch as much as possible. However, it was very challenging to balance the simplicity of the APIs and the performance of parallel/distributed training.
Accomplishments that we're proud of
Recent research reported the training of extremely large neural networks including GPT-3 (175 billion parameters), HyperCLOVA, a Korean language model trained by NAVER (82 billion parameters), and Wu Dao 2.0, which was trained using English and Chinese text as well as images (1.7 trillion parameters). However, training of such large networks must have required manual optimization by human experts.
In contrast, we confirmed that RaNNC can automate parallelization of training of a neutral network with 100 billion parameters without any manual tuning. We think this is an unprecedent result in this field.
Updates during the submission period
We implemented an offloading of model parameters to the host memory during the submission period.
When training a very large model, a large amount of the GPU memory is necessary for model parameters (The memory for activations can be relatively small). RaNNC partitions the model to reduce the memory usages per GPU, but partitioning a model into many submodels for model parallelism often increases communication overheads.
Therefore, we introduced a feature to move model parameters across the host memory and the device memory. RaNNC first places model parameters on the host memory when using this feature. Before executing an operator that needs a parameter, RaNNC moves the parameter to the device memory. RaNNC also moves the parameter soon after the operator finishes.
The peak memory can be significantly reduced by this feature. RaNNC can precisely measure the peak memory and determine partitioning so that the total memory usage for each partitioned submodel (including parameters, gradients, optimizer states, and activations) fits to the memory of a single GPU. This allows us to train a large model with a less number of submodels and to reduce communication overheads.
What we learned
We learned that TorchScript engine is very flexible when you want to extend PyTorch's behaviors.
For this hackathon, we needed to implement additinal processes in forward/backward passes in the short period. What we did for this were just to implement a few custom operators and to insert them in a computation graph that TorchScript engine executes.
What's next for RaNNC
We will work on the followings to improve RaNNC:
- Improve efficiency by introducing state-of-the-art pipeline parallelism techniques
- Apply to a wider variety of neural networks
- Thorough performance benchmarks
- Improve usability



Log in or sign up for Devpost to join the conversation.