-
-
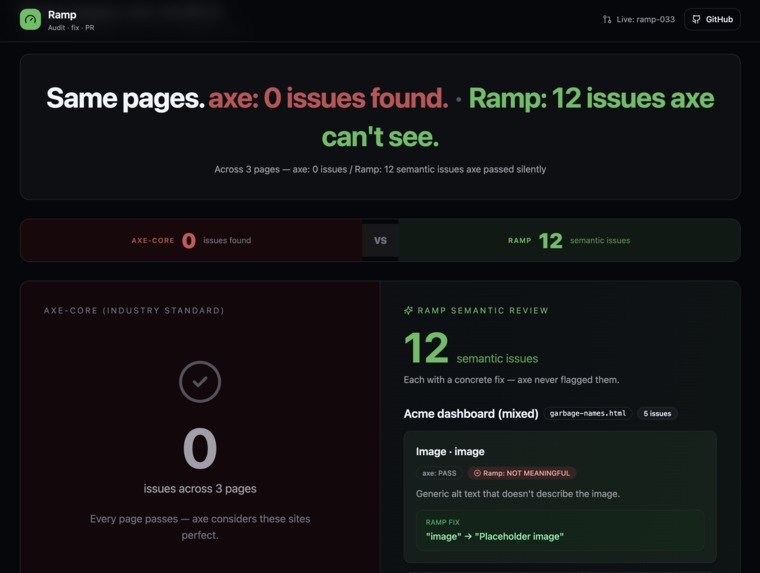
axe sees 0 issues. Ramp finds 12 — the semantic ones axe can't detect.
-
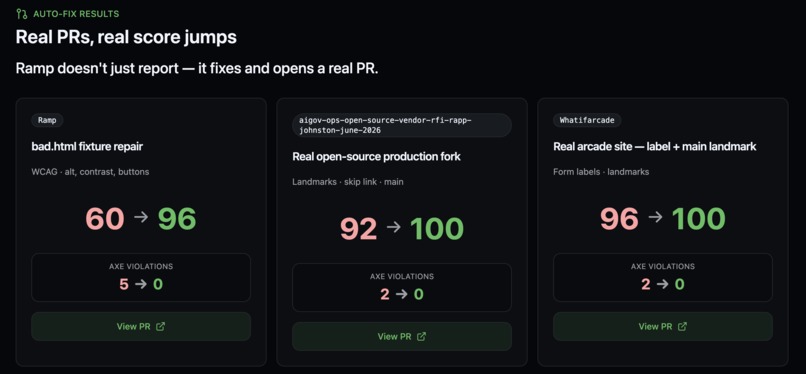
Ramp fixes real repos and opens verified PRs. Score jumps: 60→96, 92→100, 96→100.
Inspiration
1.3 billion people live with a disability. Whether they can use a website comes down to whether its code was written correctly — and the reality is that most of the web is broken for them. Over 96% of the top one million homepages have detectable accessibility failures.
Existing tools weren't built to close this gap. Industry standards like axe and Lighthouse can tell you whether an attribute exists — but they're blind to whether it's meaningful, and they only ever hand you a report. An image with alt="DSC_1042.JPG" passes axe cleanly, yet to a screen-reader user that filename means nothing. Ramp was built to catch what standard tools can't see — and to actually fix it.
What it does
Ramp is an end-to-end accessibility platform that audits a rendered web page, scores its compliance, and automatically fixes the code and opens a merge-ready pull request — dropping straight into the GitHub workflow teams already use.
Where existing tools stop at mechanical checks and static reports, Ramp pairs a real benchmark with an agent harness and an autonomous fix loop that turns evaluation into action. It has three core capabilities:
Semantic judgment axe cannot do. Across three realistic pages, axe-core reported 0 issues — everything passed. Ramp found 12 semantic issues axe let through silently: a product image labeled DSC_1042.JPG, a button labeled "button", and a link reading "click here". Only a model that understands language can judge whether an accessible name is meaningful.
Detection that depends on rendering. Many accessibility failures only appear once a page is actually rendered. Color contrast, for example, lives in external CSS — a model reading raw HTML can't see it. On a contrast-focused evaluation suite, the same model (GPT-4o-mini) reading only the HTML caught 40% of issues; equipped with Ramp's harness — which renders the page and measures contrast for real — it caught 92%.

Across the full 18-page suite, the harness wins on both recall (84.5%) and precision (89.3%). This is the core thesis: accessibility lives in what the user experiences, not just in the source code.
An autonomous fix loop. Ramp doesn't stop at flagging issues — it fixes them. It takes a real open-source project, edits the code with Claude Code, re-verifies the result with axe, and opens a real pull request — raising compliance from 92 to 100, with axe violations going from 2 to 0.

We don't send a report. We send the fix.
How Claude Code powered Ramp
Claude Code wasn't just a tool we integrated — it was the force multiplier that made the project possible within a hackathon timeframe. It contributed in three compounding ways.
Claude Code is the agent at the heart of our fix loop. When the audit surfaces a finding, Claude Code edits the source, makes a minimal targeted change, and self-verifies — turning a detected issue into real, working code. The image alt text DSC_1042.JPG becomes "Aero Runner shoe"; the unlabeled icon button receives aria-label="Search". The output isn't an alert — it's a merge-ready pull request, indistinguishable from a human-authored accessibility fix.
Claude Code built the system alongside us. The harness, control plane, sandbox checkout, fixer, and dashboard came together during the hackathon because Claude Code worked as a collaborator. We developed parallel slices while focusing on architecture and scoring, giving the codebase the surface area of a much larger team's project.
Claude Code makes semantic fixes possible. Detecting that alt="image" is meaningless is only half the problem. Deriving the right replacement from the surrounding context — and applying it as a clean diff — is what closes the loop. Without an agent capable of long-horizon, context-aware editing, this system wouldn't exist.
How we built it
Ramp is a TypeScript monorepo that connects model providers, sandboxed execution, accessibility tooling, and GitHub workflows through one control plane.

- Auditing: Playwright and axe-core, combined with a rendered accessibility tree, screen-reader serialization, and real contrast measurement.
- Multi-provider model layer: The Vercel AI SDK, allowing models to be evaluated on identical tasks.
- The fix loop: Sandboxed checkout → Claude Code headless edits → axe re-verification → real pull request through Octokit.
- Benchmark and scoring: A11y-Bench tasks plus a hand-built HTML-live evaluation suite, scored deterministically.
- Observability: The complete fix loop is instrumented with Sentry, with every audit, fix, and pull request represented as a traced span.
- Dashboard: React, Vite, and Tailwind, showing axe-versus-Ramp comparisons and before-and-after compliance scores.
Challenges we ran into
Stitching auditing, sandboxed checkout, Claude Code, and GitHub into one reproducible loop required significant infrastructure work.
Our most important insight came from an evaluation failure: scoring a harness against single-PR ground truth can actually penalize a thorough auditor. A real page may contain dozens of accessibility issues, but the answer key contains only the one issue fixed by the original pull request. As a result, a system that finds additional real problems can incorrectly appear imprecise.
This taught us that precision is only meaningful on fully annotated pages. It reshaped our evaluation approach and led us to build a fully annotated HTML-live suite where the harness's advantage could be measured fairly.
Accomplishments that we're proud of
- Built a capability axe fundamentally lacks: judging whether accessible names are meaningful, not merely present — axe: 0 findings, Ramp: 12 findings on the same pages.
- Demonstrated a measurable render-dependent advantage: 40% to 92% contrast-detection recall using the same model, with only the harness changing.
- Built a closed loop from detection to a merge-ready pull request on real open-source projects.
- Covered issues including landmarks, form labels, button names, alternative text, and color contrast.
- Curated a benchmark of 51 real accessibility tasks, each tied to a reviewable pull request.
What we learned
- Tools and prompts are a real lever on capability: the same model behaves very differently when equipped with a domain-specific harness.
- The pull request is the right interface for accessibility work because review, CI, collaboration, and merging are already solved by the tools developers use.
- The value isn't in reporting more issues — it's in being precise and actually fixing them.
What's next for Ramp
We plan to integrate Ramp directly into CI so that newly introduced accessibility issues can be automatically reproduced, fixed, and submitted upstream as pull requests.
We also want to move the fix engine to a pure API path so anyone can run it using their own keys, without requiring a local agent installation. Finally, we plan to extend Ramp's source-level analysis capabilities, building on the source-code tasks already included in our benchmark.
The goal is to make accessibility something developers complete by reviewing a single pull request.
Built With
- anthropic-api
- axe-core
- claude-code
- drizzle-orm
- github-api
- node.js
- octokit
- openai-api-(gpt-4o-mini)
- playwright
- pnpm
- react
- sentry
- sqlite
- tailwind-css
- typescript
- vercel-ai-sdk
- vite



Log in or sign up for Devpost to join the conversation.