Inspiration
We are awash in a sea of digital stuff and I try to build something that in its small way helps folks navigate around the waters.
How it works
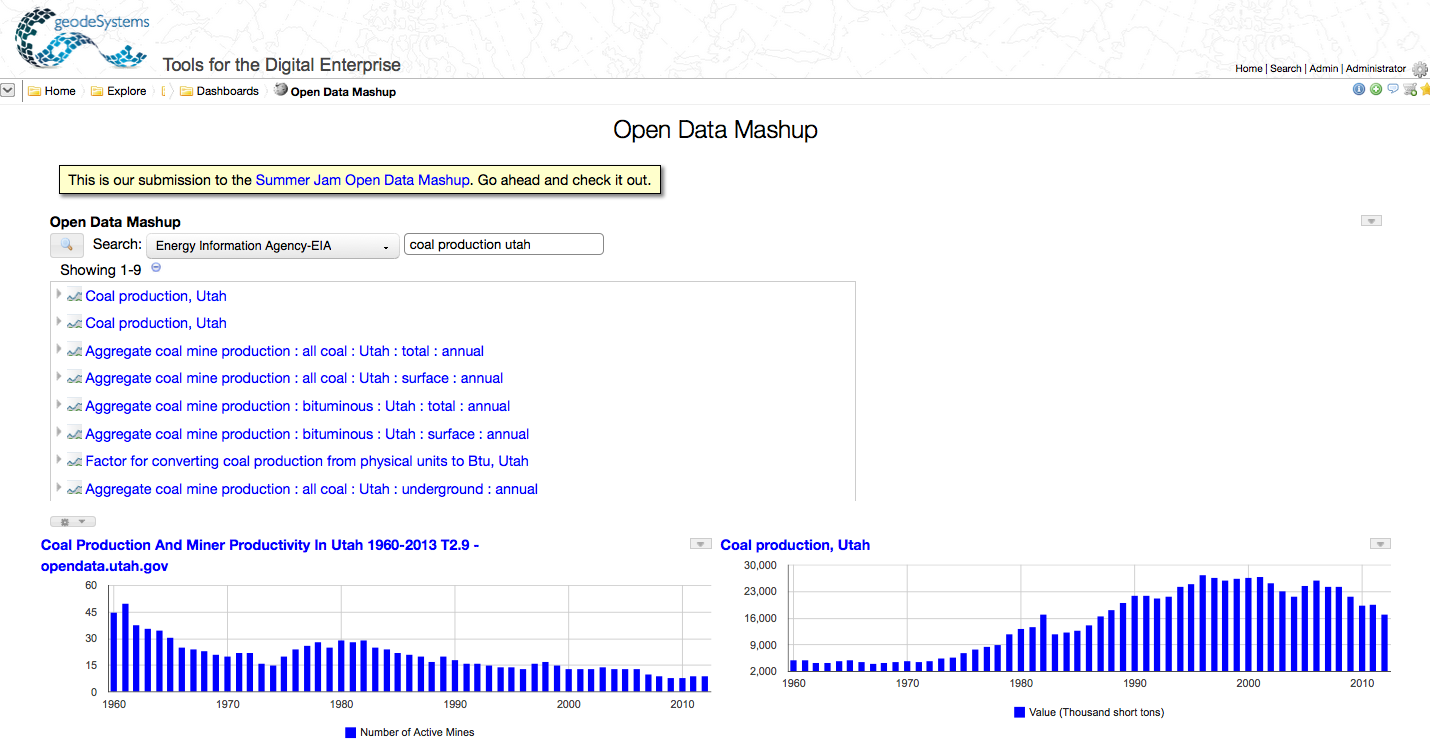
The example presented is a wiki page in RAMADDA that embeds a search and display interface. http://geodesystems.com/repository/alias/sj_opendata_mashup. End users can search across any number of sites - Socrata, Wolfram/Alpha, .gov, etc. They can then create charts, tables, etc. The video shows an example search for coal production and employment data. It uses the data from the Socrata Utah Open Data Repository, the Energy Information Agency (EIA) repository and the Federal Reserve Economic Data (FRED) system.
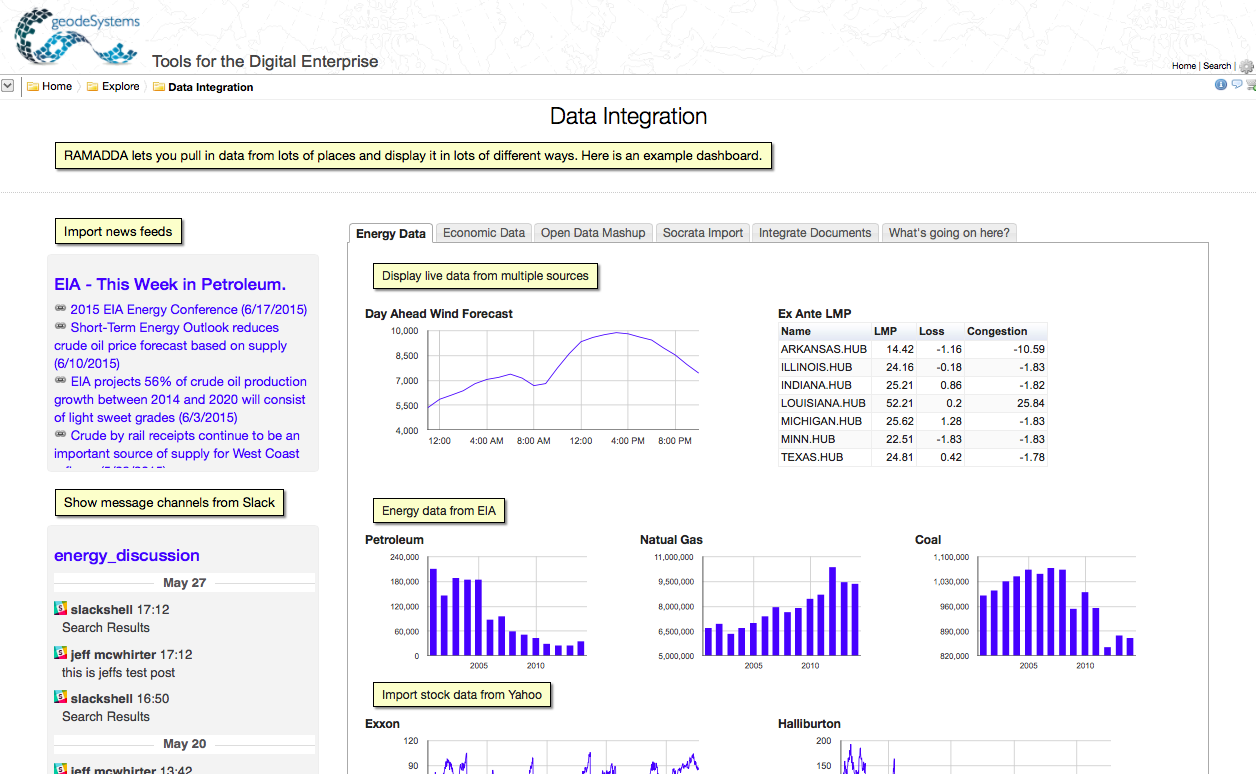
An example dashboard display (another wiki page) is also presented that shows data from lots of external sources - http://geodesystems.com/repository/alias/dataintegration
On the back, all of the search and data access to remote sites is proxied through RAMADDA's data integration framework. To go reallt wonky, RAMADDA is a software framework that is designed to be extended. The search integration and display of external data is accomplished with a number Java-based plugins, e.g. - http://sourceforge.net/p/ramadda/code/HEAD/tree/src/org/ramadda/plugins/ The code implements searching of external repositories and it maps the results into the internal RAMADDA content model. Which then gets displayed in any number of ways through basic RAMADDA services.
Challenges I ran into
APIs, APIs, APIs. Way too many different APIs. For the most part they are all very well done and very well documented. But, each has their own way of authenticating, of submitting requests (usually REST style and not a real problem) and returning results - a REAL problem. Most repositories return some form of JSON or XML and/or CSV (which I like) but there is no standard content model (other than the little uses ATOM/RSS XML).
Accomplishments that I'm proud of
I'm just tickled when I see visual and interactive data from lots (and lots) of places.
What I learned
Big data isn't the problem. Lots of little data is the problem.
What's next for RAMADDA Open Data Integration
More and more APIs and data - Dropbox, Box, Evernote, Google, etc.

Log in or sign up for Devpost to join the conversation.